 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynQP: A Framework and Metrics for Evaluating the Quality and Privacy Risk of Synthetic Data
Jan 17, 2026The use of synthetic data in health applications raises privacy concerns, yet the lack of open frameworks for privacy evaluations has slowed its adoption. A major challenge is the absence of accessible benchmark datasets for evaluating privacy risks, due to difficulties in acquiring sensitive data. To address this, we introduce SynQP, an open framework for benchmarking privacy in synthetic data generation (SDG) using simulated sensitive data, ensuring that original data remains confidential. We also highlight the need for privacy metrics that fairly account for the probabilistic nature of machine learning models. As a demonstration, we use SynQP to benchmark CTGAN and propose a new identity disclosure risk metric that offers a more accurate estimation of privacy risks compared to existing approaches. Our work provides a critical tool for improving the transparency and reliability of privacy evaluations, enabling safer use of synthetic data in health-related applications. % In our quality evaluations, non-private models achieved near-perfect machine-learning efficacy \(\ge0.97\). Our privacy assessments (Table II) reveal that DP consistently lowers both identity disclosure risk (SD-IDR) and membership-inference attack risk (SD-MIA), with all DP-augmented models staying below the 0.09 regulatory threshold. Code available at https://github.com/CAN-SYNH/SynQP
* 7 Pages, 22nd Annual International Conference on Privacy, Security, and Trust (PST2025), Fredericton, Canada
Multiview Equivariance Improves 3D Correspondence Understanding with Minimal Feature Finetuning
Nov 29, 2024Vision foundation models, particularly the ViT family, have revolutionized image understanding by providing rich semantic features. However, despite their success in 2D comprehension, their abilities on grasping 3D spatial relationships are still unclear. In this work, we evaluate and enhance the 3D awareness of ViT-based models. We begin by systematically assessing their ability to learn 3D equivariant features, specifically examining the consistency of semantic embeddings across different viewpoints. Our findings indicate that improved 3D equivariance leads to better performance on various downstream tasks, including pose estimation, tracking, and semantic transfer. Building on this insight, we propose a simple yet effective finetuning strategy based on 3D correspondences, which significantly enhances the 3D correspondence understanding of existing vision models. Remarkably, even finetuning on a single object for just one iteration results in substantial performance gains. All code and resources will be made publicly available to support further advancements in 3D-aware vision models. Our code is available at https://github.com/qq456cvb/3DCorrEnhance.
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
May 09, 2024



Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
IL-MCAM: An interactive learning and multi-channel attention mechanism-based weakly supervised colorectal histopathology image classification approach
Jun 07, 2022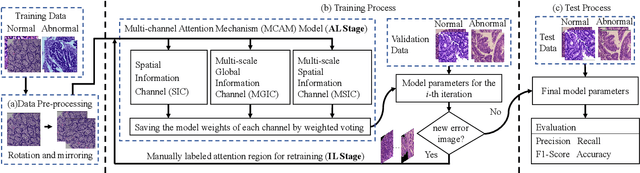
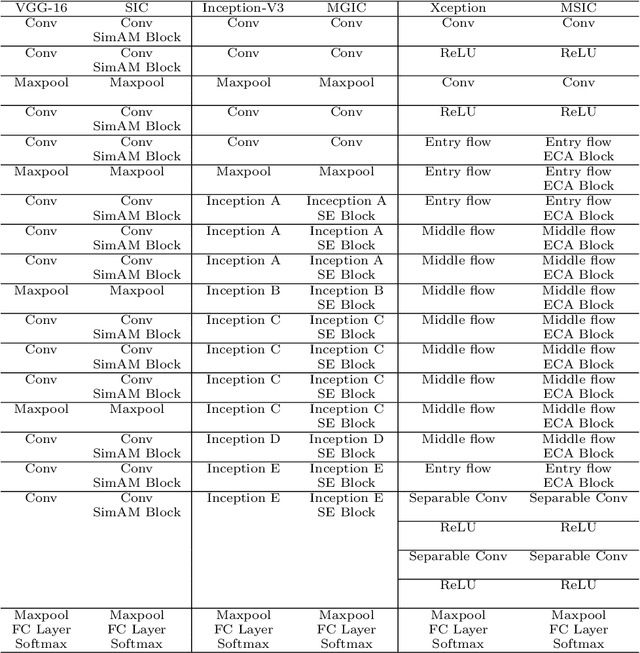
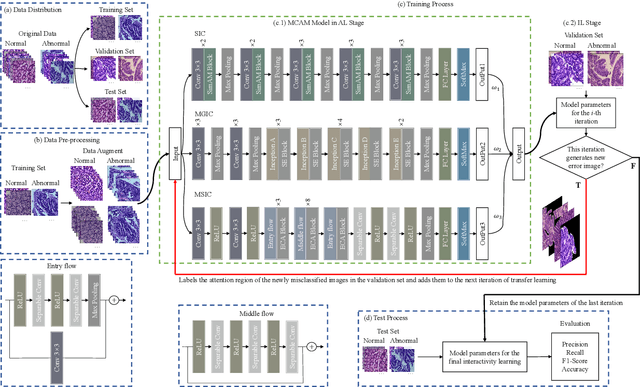
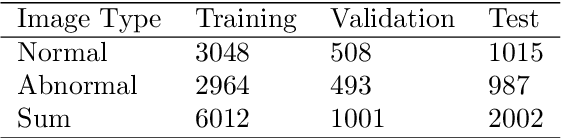
In recent years, colorectal cancer has become one of the most significant diseases that endanger human health. Deep learning methods are increasingly important for the classification of colorectal histopathology images. However, existing approaches focus more on end-to-end automatic classification using computers rather than human-computer interaction. In this paper, we propose an IL-MCAM framework. It is based on attention mechanisms and interactive learning. The proposed IL-MCAM framework includes two stages: automatic learning (AL) and interactivity learning (IL). In the AL stage, a multi-channel attention mechanism model containing three different attention mechanism channels and convolutional neural networks is used to extract multi-channel features for classification. In the IL stage, the proposed IL-MCAM framework continuously adds misclassified images to the training set in an interactive approach, which improves the classification ability of the MCAM model. We carried out a comparison experiment on our dataset and an extended experiment on the HE-NCT-CRC-100K dataset to verify the performance of the proposed IL-MCAM framework, achieving classification accuracies of 98.98% and 99.77%, respectively. In addition, we conducted an ablation experiment and an interchangeability experiment to verify the ability and interchangeability of the three channels. The experimental results show that the proposed IL-MCAM framework has excellent performance in the colorectal histopathological image classification tasks.
Application of Graph Based Features in Computer Aided Diagnosis for Histopathological Image Classification of Gastric Cancer
May 17, 2022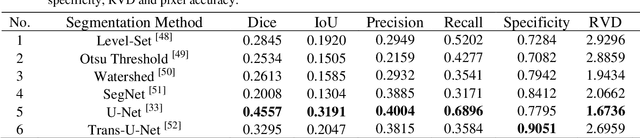

The gold standard for gastric cancer detection is gastric histopathological image analysis, but there are certain drawbacks in the existing histopathological detection and diagnosis. In this paper, based on the study of computer aided diagnosis system, graph based features are applied to gastric cancer histopathology microscopic image analysis, and a classifier is used to classify gastric cancer cells from benign cells. Firstly, image segmentation is performed, and after finding the region, cell nuclei are extracted using the k-means method, the minimum spanning tree (MST) is drawn, and graph based features of the MST are extracted. The graph based features are then put into the classifier for classification. In this study, different segmentation methods are compared in the tissue segmentation stage, among which are Level-Set, Otsu thresholding, watershed, SegNet, U-Net and Trans-U-Net segmentation; Graph based features, Red, Green, Blue features, Grey-Level Co-occurrence Matrix features, Histograms of Oriented Gradient features and Local Binary Patterns features are compared in the feature extraction stage; Radial Basis Function (RBF) Support Vector Machine (SVM), Linear SVM, Artificial Neural Network, Random Forests, k-NearestNeighbor, VGG16, and Inception-V3 are compared in the classifier stage. It is found that using U-Net to segment tissue areas, then extracting graph based features, and finally using RBF SVM classifier gives the optimal results with 94.29%.
Application of Transfer Learning and Ensemble Learning in Image-level Classification for Breast Histopathology
Apr 18, 2022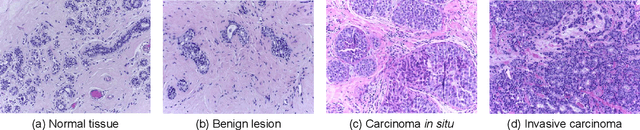

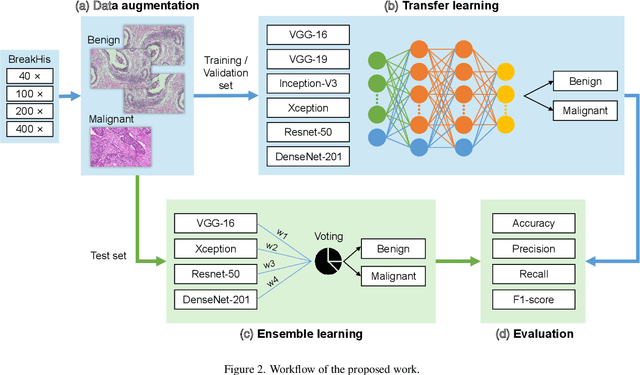
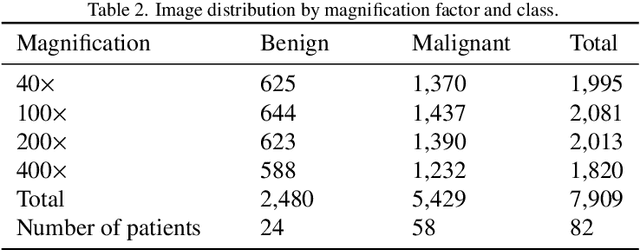
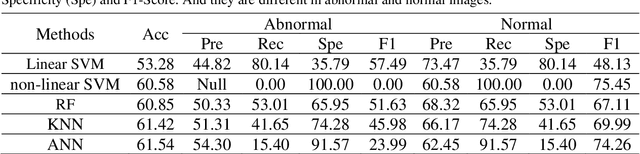
Background: Breast cancer has the highest prevalence in women globally. The classification and diagnosis of breast cancer and its histopathological images have always been a hot spot of clinical concern. In Computer-Aided Diagnosis (CAD), traditional classification models mostly use a single network to extract features, which has significant limitations. On the other hand, many networks are trained and optimized on patient-level datasets, ignoring the application of lower-level data labels. Method: This paper proposes a deep ensemble model based on image-level labels for the binary classification of benign and malignant lesions of breast histopathological images. First, the BreakHis dataset is randomly divided into a training, validation and test set. Then, data augmentation techniques are used to balance the number of benign and malignant samples. Thirdly, considering the performance of transfer learning and the complementarity between each network, VGG-16, Xception, Resnet-50, DenseNet-201 are selected as the base classifiers. Result: In the ensemble network model with accuracy as the weight, the image-level binary classification achieves an accuracy of $98.90\%$. In order to verify the capabilities of our method, the latest Transformer and Multilayer Perception (MLP) models have been experimentally compared on the same dataset. Our model wins with a $5\%-20\%$ advantage, emphasizing the ensemble model's far-reaching significance in classification tasks. Conclusion: This research focuses on improving the model's classification performance with an ensemble algorithm. Transfer learning plays an essential role in small datasets, improving training speed and accuracy. Our model has outperformed many existing approaches in accuracy, providing a method for the field of auxiliary medical diagnosis.
Neural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review
Jul 07, 2021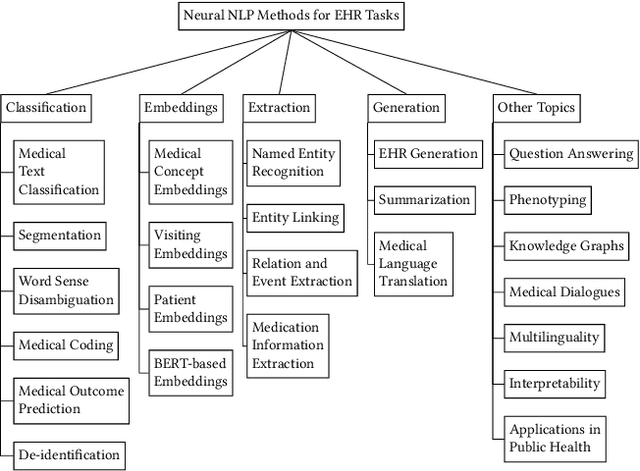
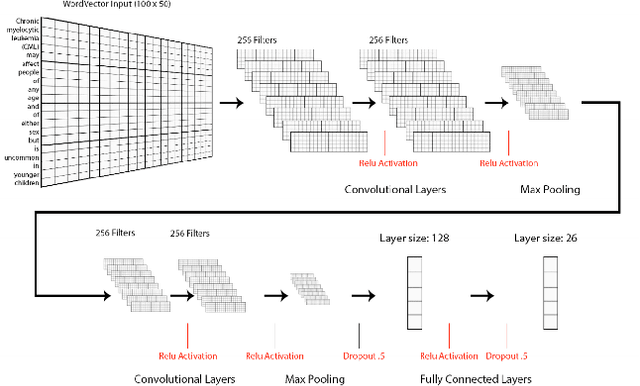

Electronic health records (EHRs), digital collections of patient healthcare events and observations, are ubiquitous in medicine and critical to healthcare delivery, operations, and research. Despite this central role, EHRs are notoriously difficult to process automatically. Well over half of the information stored within EHRs is in the form of unstructured text (e.g. provider notes, operation reports) and remains largely untapped for secondary use. Recently, however, newer neural network and deep learning approaches to Natural Language Processing (NLP) have made considerable advances, outperforming traditional statistical and rule-based systems on a variety of tasks. In this survey paper, we summarize current neural NLP methods for EHR applications. We focus on a broad scope of tasks, namely, classification and prediction, word embeddings, extraction, generation, and other topics such as question answering, phenotyping, knowledge graphs, medical dialogue, multilinguality, interpretability, etc.
GasHis-Transformer: A Multi-scale Visual Transformer Approach for Gastric Histopathology Image Classification
May 25, 2021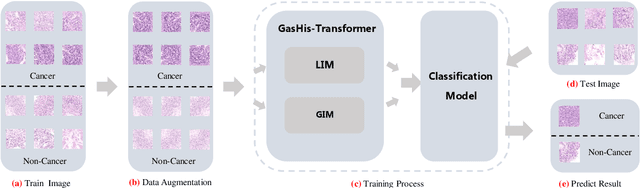

Existing deep learning methods for diagnosis of gastric cancer commonly use convolutional neural networks (CNN). Recently, the Visual Transformer (VT) has attracted a major attention because of its performance and efficiency, but its applications are mostly in the field of computer vision. In this paper, a multi-scale visual transformer model, referred to as GasHis-Transformer, is proposed for gastric histopathology image classification (GHIC), which enables the automatic classification of microscopic gastric images into abnormal and normal cases. The GasHis-Transformer model consists of two key modules: a global information module (GIM) and a local information module (LIM) to extract pathological features effectively. In our experiments, a public hematoxylin and eosin (H&E) stained gastric histopathology dataset with 280 abnormal or normal images using the GasHis-Transformer model is applied to estimate precision, recall, F1-score, and accuracy on the testing set as 98.0%, 100.0%, 96.0% and 98.0% respectively. Furthermore, a critical study is conducted to evaluate the robustness of GasHis-Transformer according to add ten different noises including adversarial attack and traditional image noise. In addition, a clinically meaningful study is executed to test the gastric cancer identification of GasHis-Transformerwith 420 abnormal images and achieves 96.2% accuracy. Finally, a comparative study is performed to test the generalizability with both H&E and Immunohistochemical (IHC) stained images on a lymphoma image dataset, a breast cancer dataset and a cervical cancer dataset, producing comparable F1-scores (85.6%, 82.8% and 65.7%, respectively) and accuracy (83.9%, 89.4% and 65.7%, respectively) respectively. In conclusion, GasHis-Transformerdemonstrates a high classification performance and shows its significant potential in histopathology image analysis.
Heterogeneous Graph Neural Networks for Multi-label Text Classification
Mar 26, 2021
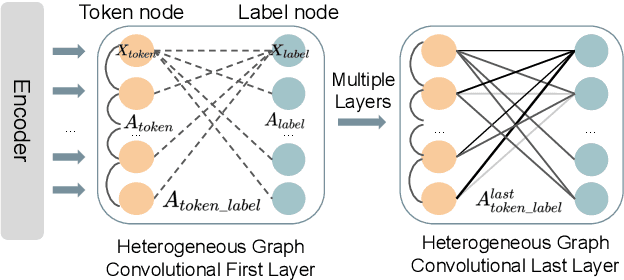


Multi-label text classification (MLTC) is an attractive and challenging task in natural language processing (NLP). Compared with single-label text classification, MLTC has a wider range of applications in practice. In this paper, we propose a heterogeneous graph convolutional network model to solve the MLTC problem by modeling tokens and labels as nodes in a heterogeneous graph. In this way, we are able to take into account multiple relationships including token-level relationships. Besides, the model allows a good explainability as the token-label edges are exposed. We evaluate our method on three real-world datasets and the experimental results show that it achieves significant improvements and outperforms state-of-the-art comparison methods.
A Hierarchical Conditional Random Field-based Attention Mechanism Approach for Gastric Histopathology Image Classification
Feb 21, 2021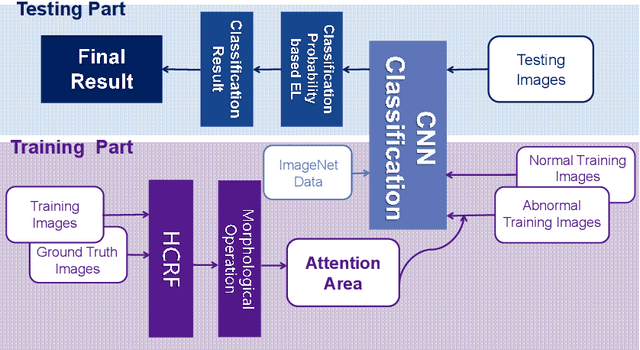

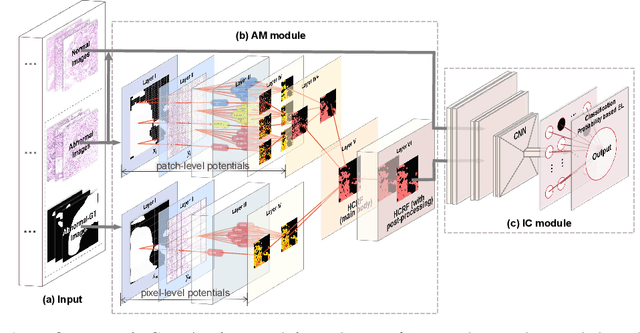

In the Gastric Histopathology Image Classification (GHIC) tasks, which is usually weakly supervised learning missions, there is inevitably redundant information in the images. Therefore, designing networks that can focus on effective distinguishing features has become a popular research topic. In this paper, to accomplish the tasks of GHIC superiorly and to assist pathologists in clinical diagnosis, an intelligent Hierarchical Conditional Random Field based Attention Mechanism (HCRF-AM) model is proposed. The HCRF-AM model consists of an Attention Mechanism (AM) module and an Image Classification (IC) module. In the AM module, an HCRF model is built to extract attention regions. In the IC module, a Convolutional Neural Network (CNN) model is trained with the attention regions selected and then an algorithm called Classification Probability-based Ensemble Learning is applied to obtain the image-level results from patch-level output of the CNN. In the experiment, a classification specificity of 96.67% is achieved on a gastric histopathology dataset with 700 images. Our HCRF-AM model demonstrates high classification performance and shows its effectiveness and future potential in the GHIC field.