 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal 3D Brain Tumor Segmentation with Adversarial Training and Conditional Random Field
Nov 21, 2024Accurate brain tumor segmentation remains a challenging task due to structural complexity and great individual differences of gliomas. Leveraging the pre-eminent detail resilience of CRF and spatial feature extraction capacity of V-net, we propose a multimodal 3D Volume Generative Adversarial Network (3D-vGAN) for precise segmentation. The model utilizes Pseudo-3D for V-net improvement, adds conditional random field after generator and use original image as supplemental guidance. Results, using the BraTS-2018 dataset, show that 3D-vGAN outperforms classical segmentation models, including U-net, Gan, FCN and 3D V-net, reaching specificity over 99.8%.
* 13 pages, 7 figures, Annual Conference on Medical Image Understanding and Analysis (MIUA) 2024
Application of Graph Based Features in Computer Aided Diagnosis for Histopathological Image Classification of Gastric Cancer
May 17, 2022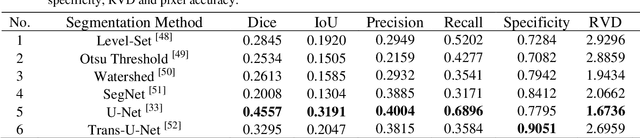

The gold standard for gastric cancer detection is gastric histopathological image analysis, but there are certain drawbacks in the existing histopathological detection and diagnosis. In this paper, based on the study of computer aided diagnosis system, graph based features are applied to gastric cancer histopathology microscopic image analysis, and a classifier is used to classify gastric cancer cells from benign cells. Firstly, image segmentation is performed, and after finding the region, cell nuclei are extracted using the k-means method, the minimum spanning tree (MST) is drawn, and graph based features of the MST are extracted. The graph based features are then put into the classifier for classification. In this study, different segmentation methods are compared in the tissue segmentation stage, among which are Level-Set, Otsu thresholding, watershed, SegNet, U-Net and Trans-U-Net segmentation; Graph based features, Red, Green, Blue features, Grey-Level Co-occurrence Matrix features, Histograms of Oriented Gradient features and Local Binary Patterns features are compared in the feature extraction stage; Radial Basis Function (RBF) Support Vector Machine (SVM), Linear SVM, Artificial Neural Network, Random Forests, k-NearestNeighbor, VGG16, and Inception-V3 are compared in the classifier stage. It is found that using U-Net to segment tissue areas, then extracting graph based features, and finally using RBF SVM classifier gives the optimal results with 94.29%.
Application of Transfer Learning and Ensemble Learning in Image-level Classification for Breast Histopathology
Apr 18, 2022

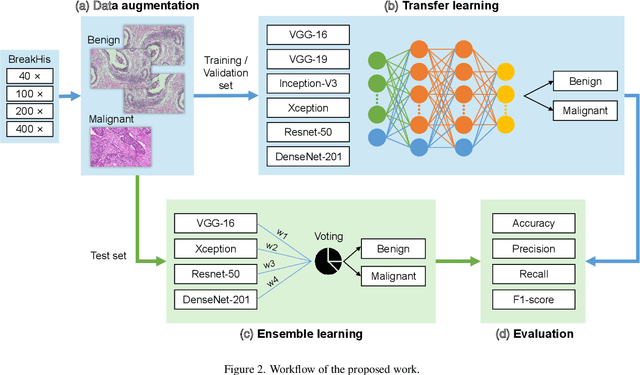
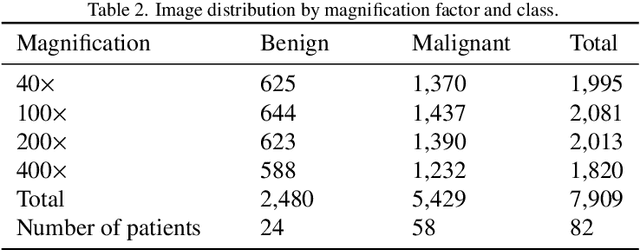
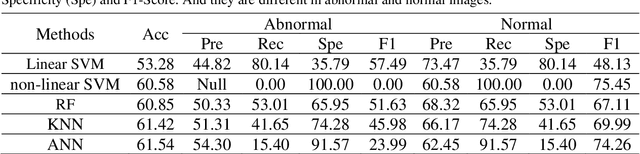
Background: Breast cancer has the highest prevalence in women globally. The classification and diagnosis of breast cancer and its histopathological images have always been a hot spot of clinical concern. In Computer-Aided Diagnosis (CAD), traditional classification models mostly use a single network to extract features, which has significant limitations. On the other hand, many networks are trained and optimized on patient-level datasets, ignoring the application of lower-level data labels. Method: This paper proposes a deep ensemble model based on image-level labels for the binary classification of benign and malignant lesions of breast histopathological images. First, the BreakHis dataset is randomly divided into a training, validation and test set. Then, data augmentation techniques are used to balance the number of benign and malignant samples. Thirdly, considering the performance of transfer learning and the complementarity between each network, VGG-16, Xception, Resnet-50, DenseNet-201 are selected as the base classifiers. Result: In the ensemble network model with accuracy as the weight, the image-level binary classification achieves an accuracy of $98.90\%$. In order to verify the capabilities of our method, the latest Transformer and Multilayer Perception (MLP) models have been experimentally compared on the same dataset. Our model wins with a $5\%-20\%$ advantage, emphasizing the ensemble model's far-reaching significance in classification tasks. Conclusion: This research focuses on improving the model's classification performance with an ensemble algorithm. Transfer learning plays an essential role in small datasets, improving training speed and accuracy. Our model has outperformed many existing approaches in accuracy, providing a method for the field of auxiliary medical diagnosis.
Jointly identifying opinion mining elements and fuzzy measurement of opinion intensity to analyze product features
Nov 13, 2018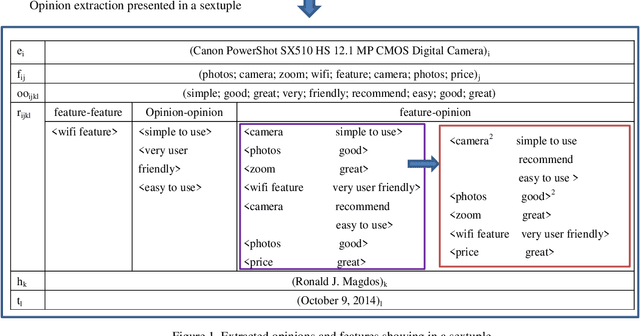

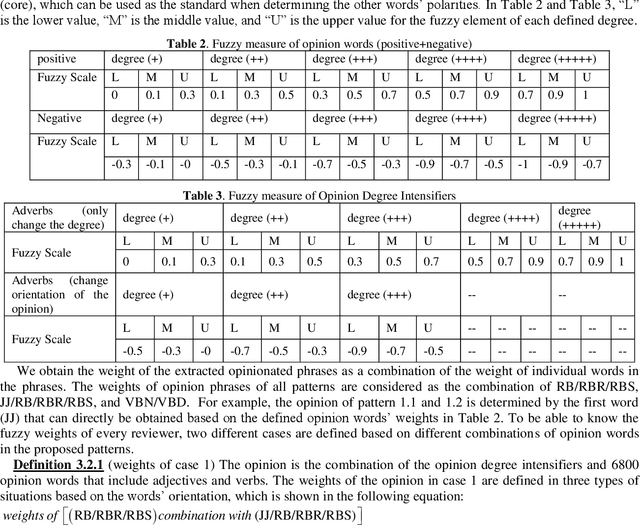
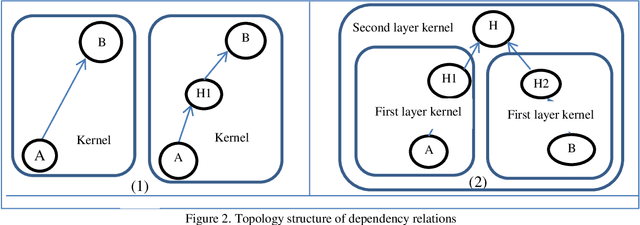
Opinion mining mainly involves three elements: feature and feature-of relations, opinion expressions and the related opinion attributes (e.g. Polarity), and feature-opinion relations. Although many works have emerged to achieve its aim of gaining information, the previous researches typically handled each of the three elements in isolation, which cannot give sufficient information extraction results; hence, the complexity and the running time of information extraction is increased. In this paper, we propose an opinion mining extraction algorithm to jointly discover the main opinion mining elements. Specifically, the algorithm automatically builds kernels to combine closely related words into new terms from word level to phrase level based on dependency relations; and we ensure the accuracy of opinion expressions and polarity based on: fuzzy measurements, opinion degree intensifiers, and opinion patterns. The 3458 analyzed reviews show that the proposed algorithm can effectively identify the main elements simultaneously and outperform the baseline methods. The proposed algorithm is used to analyze the features among heterogeneous products in the same category. The feature-by-feature comparison can help to select the weaker features and recommend the correct specifications from the beginning life of a product. From this comparison, some interesting observations are revealed. For example, the negative polarity of video dimension is higher than the product usability dimension for a product. Yet, enhancing the dimension of product usability can more effectively improve the product (C) 2015 Elsevier Ltd. All rights reserved.