 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaFeR-VLM: Toward Safety-aware Fine-grained Reasoning in Multimodal Models
Oct 08, 2025Multimodal Large Reasoning Models (MLRMs) demonstrate impressive cross-modal reasoning but often amplify safety risks under adversarial or unsafe prompts, a phenomenon we call the \textit{Reasoning Tax}. Existing defenses mainly act at the output level and do not constrain the reasoning process, leaving models exposed to implicit risks. In this paper, we propose SaFeR-VLM, a safety-aligned reinforcement learning framework that embeds safety directly into multimodal reasoning. The framework integrates four components: (I) QI-Safe-10K, a curated dataset emphasizing safety-critical and reasoning-sensitive cases; (II) safety-aware rollout, where unsafe generations undergo reflection and correction instead of being discarded; (III) structured reward modeling with multi-dimensional weighted criteria and explicit penalties for hallucinations and contradictions; and (IV) GRPO optimization, which reinforces both safe and corrected trajectories. This unified design shifts safety from a passive safeguard to an active driver of reasoning, enabling scalable and generalizable safety-aware reasoning. SaFeR-VLM further demonstrates robustness against both explicit and implicit risks, supporting dynamic and interpretable safety decisions beyond surface-level filtering. SaFeR-VLM-3B achieves average performance $70.13$ and $78.97$ on safety and helpfulness across six benchmarks, surpassing both same-scale and $>10\times$ larger models such as Skywork-R1V3-38B, Qwen2.5VL-72B, and GLM4.5V-106B. Remarkably, SaFeR-VLM-7B benefits from its increased scale to surpass GPT-5-mini and Gemini-2.5-Flash by \num{6.47} and \num{16.76} points respectively on safety metrics, achieving this improvement without any degradation in helpfulness performance. Our codes are available at https://github.com/HarveyYi/SaFeR-VLM.
G-Memory: Tracing Hierarchical Memory for Multi-Agent Systems
Jun 09, 2025Large language model (LLM)-powered multi-agent systems (MAS) have demonstrated cognitive and execution capabilities that far exceed those of single LLM agents, yet their capacity for self-evolution remains hampered by underdeveloped memory architectures. Upon close inspection, we are alarmed to discover that prevailing MAS memory mechanisms (1) are overly simplistic, completely disregarding the nuanced inter-agent collaboration trajectories, and (2) lack cross-trial and agent-specific customization, in stark contrast to the expressive memory developed for single agents. To bridge this gap, we introduce G-Memory, a hierarchical, agentic memory system for MAS inspired by organizational memory theory, which manages the lengthy MAS interaction via a three-tier graph hierarchy: insight, query, and interaction graphs. Upon receiving a new user query, G-Memory performs bi-directional memory traversal to retrieve both $\textit{high-level, generalizable insights}$ that enable the system to leverage cross-trial knowledge, and $\textit{fine-grained, condensed interaction trajectories}$ that compactly encode prior collaboration experiences. Upon task execution, the entire hierarchy evolves by assimilating new collaborative trajectories, nurturing the progressive evolution of agent teams. Extensive experiments across five benchmarks, three LLM backbones, and three popular MAS frameworks demonstrate that G-Memory improves success rates in embodied action and accuracy in knowledge QA by up to $20.89\%$ and $10.12\%$, respectively, without any modifications to the original frameworks. Our codes are available at https://github.com/bingreeky/GMemory.
UniErase: Unlearning Token as a Universal Erasure Primitive for Language Models
May 21, 2025Large language models require iterative updates to address challenges such as knowledge conflicts and outdated information (e.g., incorrect, private, or illegal contents). Machine unlearning provides a systematic methodology for targeted knowledge removal from trained models, enabling elimination of sensitive information influences. However, mainstream fine-tuning-based unlearning methods often fail to balance unlearning efficacy and model ability, frequently resulting in catastrophic model collapse under extensive knowledge removal. Meanwhile, in-context unlearning, which relies solely on contextual prompting without modifying the model's intrinsic mechanisms, suffers from limited generalizability and struggles to achieve true unlearning. In this work, we introduce UniErase, a novel unlearning paradigm that employs learnable parametric suffix (unlearning token) to steer language models toward targeted forgetting behaviors. UniErase operates through two key phases: (I) an optimization stage that binds desired unlearning outputs to the model's autoregressive probability distribution via token optimization, followed by (II) a lightweight model editing phase that activates the learned token to probabilistically induce specified forgetting objective. Serving as a new research direction for token learning to induce unlearning target, UniErase achieves state-of-the-art (SOTA) performance across batch, sequential, and precise unlearning under fictitious and real-world knowledge settings. Remarkably, in terms of TOFU benchmark, UniErase, modifying only around 3.66% of the LLM parameters, outperforms previous forgetting SOTA baseline by around 4.01 times for model ability with even better unlearning efficacy. Similarly, UniErase, maintaining more ability, also surpasses previous retaining SOTA by 35.96% for unlearning efficacy, showing dual top-tier performances in current unlearing domain.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
PV-VLM: A Multimodal Vision-Language Approach Incorporating Sky Images for Intra-Hour Photovoltaic Power Forecasting
Apr 18, 2025The rapid proliferation of solar energy has significantly expedited the integration of photovoltaic (PV) systems into contemporary power grids. Considering that the cloud dynamics frequently induce rapid fluctuations in solar irradiance, accurate intra-hour forecasting is critical for ensuring grid stability and facilitating effective energy management. To leverage complementary temporal, textual, and visual information, this paper has proposed PV-VLM, a multimodal forecasting framework that integrates temporal, textual, and visual information by three modules. The Time-Aware Module employed a PatchTST-inspired Transformer to capture both local and global dependencies in PV power time series. Meanwhile, the Prompt-Aware Module encodes textual prompts from historical statistics and dataset descriptors via a large language model. Additionally, the Vision-Aware Module utilizes a pretrained vision-language model to extract high-level semantic features from sky images, emphasizing cloud motion and irradiance fluctuations. The proposed PV-VLM is evaluated using data from a 30-kW rooftop array at Stanford University and through a transfer study on PV systems at the University of Wollongong in Australia. Comparative experiments reveal an average RMSE reduction of approximately 5% and a MAE improvement of nearly 6%, while the transfer study shows average RMSE and MAE reductions of about 7% and 9.5%, respectively. Overall, PV-VLM leverages complementary modalities to provide a robust solution for grid scheduling and energy market participation, enhancing the stability and reliability of PV integration.
A Novel Distributed PV Power Forecasting Approach Based on Time-LLM
Mar 08, 2025



Distributed photovoltaic (DPV) systems are essential for advancing renewable energy applications and achieving energy independence. Accurate DPV power forecasting can optimize power system planning and scheduling while significantly reducing energy loss, thus enhancing overall system efficiency and reliability. However, solar energy's intermittent nature and DPV systems' spatial distribution create significant forecasting challenges. Traditional methods often rely on costly external data, such as numerical weather prediction (NWP) and satellite images, which are difficult to scale for smaller DPV systems. To tackle this issue, this study has introduced an advanced large language model (LLM)-based time series forecasting framework Time-LLM to improve the DPV power forecasting accuracy and generalization ability. By reprogramming, the framework aligns historical power data with natural language modalities, facilitating efficient modeling of time-series data. Then Qwen2.5-3B model is integrated as the backbone LLM to process input data by leveraging its pattern recognition and inference abilities, achieving a balance between efficiency and performance. Finally, by using a flatten and linear projection layer, the LLM's high-dimensional output is transformed into the final forecasts. Experimental results indicate that Time-LLM outperforms leading recent advanced time series forecasting models, such as Transformer-based methods and MLP-based models, achieving superior accuracy in both short-term and long-term forecasting. Time-LLM also demonstrates exceptional adaptability in few-shot and zero-shot learning scenarios. To the best of the authors' knowledge, this study is the first attempt to explore the application of LLMs to DPV power forecasting, which can offer a scalable solution that eliminates reliance on costly external data sources and improve real-world forecasting accuracy.
AgentSafe: Safeguarding Large Language Model-based Multi-agent Systems via Hierarchical Data Management
Mar 06, 2025Large Language Model based multi-agent systems are revolutionizing autonomous communication and collaboration, yet they remain vulnerable to security threats like unauthorized access and data breaches. To address this, we introduce AgentSafe, a novel framework that enhances MAS security through hierarchical information management and memory protection. AgentSafe classifies information by security levels, restricting sensitive data access to authorized agents. AgentSafe incorporates two components: ThreatSieve, which secures communication by verifying information authority and preventing impersonation, and HierarCache, an adaptive memory management system that defends against unauthorized access and malicious poisoning, representing the first systematic defense for agent memory. Experiments across various LLMs show that AgentSafe significantly boosts system resilience, achieving defense success rates above 80% under adversarial conditions. Additionally, AgentSafe demonstrates scalability, maintaining robust performance as agent numbers and information complexity grow. Results underscore effectiveness of AgentSafe in securing MAS and its potential for real-world application.
LLM-Virus: Evolutionary Jailbreak Attack on Large Language Models
Dec 28, 2024



While safety-aligned large language models (LLMs) are increasingly used as the cornerstone for powerful systems such as multi-agent frameworks to solve complex real-world problems, they still suffer from potential adversarial queries, such as jailbreak attacks, which attempt to induce harmful content. Researching attack methods allows us to better understand the limitations of LLM and make trade-offs between helpfulness and safety. However, existing jailbreak attacks are primarily based on opaque optimization techniques (e.g. token-level gradient descent) and heuristic search methods like LLM refinement, which fall short in terms of transparency, transferability, and computational cost. In light of these limitations, we draw inspiration from the evolution and infection processes of biological viruses and propose LLM-Virus, a jailbreak attack method based on evolutionary algorithm, termed evolutionary jailbreak. LLM-Virus treats jailbreak attacks as both an evolutionary and transfer learning problem, utilizing LLMs as heuristic evolutionary operators to ensure high attack efficiency, transferability, and low time cost. Our experimental results on multiple safety benchmarks show that LLM-Virus achieves competitive or even superior performance compared to existing attack methods.
Multimodal 3D Brain Tumor Segmentation with Adversarial Training and Conditional Random Field
Nov 21, 2024Accurate brain tumor segmentation remains a challenging task due to structural complexity and great individual differences of gliomas. Leveraging the pre-eminent detail resilience of CRF and spatial feature extraction capacity of V-net, we propose a multimodal 3D Volume Generative Adversarial Network (3D-vGAN) for precise segmentation. The model utilizes Pseudo-3D for V-net improvement, adds conditional random field after generator and use original image as supplemental guidance. Results, using the BraTS-2018 dataset, show that 3D-vGAN outperforms classical segmentation models, including U-net, Gan, FCN and 3D V-net, reaching specificity over 99.8%.
* 13 pages, 7 figures, Annual Conference on Medical Image Understanding and Analysis (MIUA) 2024
NetSafe: Exploring the Topological Safety of Multi-agent Networks
Oct 21, 2024
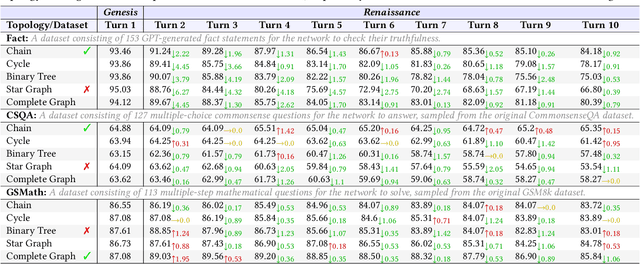
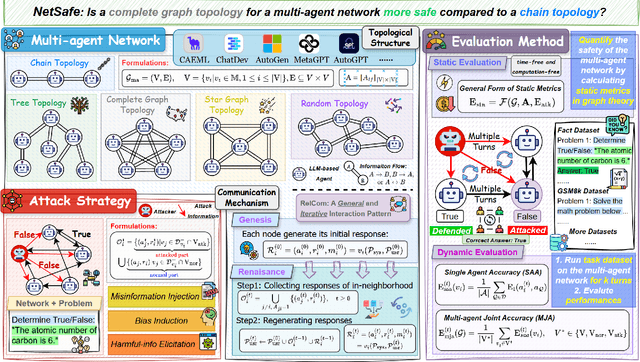
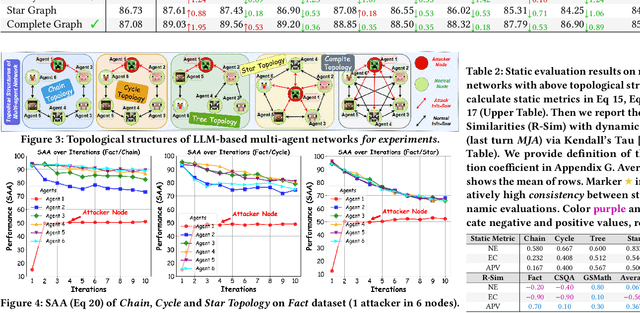
Large language models (LLMs) have empowered nodes within multi-agent networks with intelligence, showing growing applications in both academia and industry. However, how to prevent these networks from generating malicious information remains unexplored with previous research on single LLM's safety be challenging to transfer. In this paper, we focus on the safety of multi-agent networks from a topological perspective, investigating which topological properties contribute to safer networks. To this end, we propose a general framework, NetSafe along with an iterative RelCom interaction to unify existing diverse LLM-based agent frameworks, laying the foundation for generalized topological safety research. We identify several critical phenomena when multi-agent networks are exposed to attacks involving misinformation, bias, and harmful information, termed as Agent Hallucination and Aggregation Safety. Furthermore, we find that highly connected networks are more susceptible to the spread of adversarial attacks, with task performance in a Star Graph Topology decreasing by 29.7%. Besides, our proposed static metrics aligned more closely with real-world dynamic evaluations than traditional graph-theoretic metrics, indicating that networks with greater average distances from attackers exhibit enhanced safety. In conclusion, our work introduces a new topological perspective on the safety of LLM-based multi-agent networks and discovers several unreported phenomena, paving the way for future research to explore the safety of such networks.