 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan MLLMs Read Students' Minds? Unpacking Multimodal Error Analysis in Handwritten Math
Mar 26, 2026Assessing student handwritten scratchwork is crucial for personalized educational feedback but presents unique challenges due to diverse handwriting, complex layouts, and varied problem-solving approaches. Existing educational NLP primarily focuses on textual responses and neglects the complexity and multimodality inherent in authentic handwritten scratchwork. Current multimodal large language models (MLLMs) excel at visual reasoning but typically adopt an "examinee perspective", prioritizing generating correct answers rather than diagnosing student errors. To bridge these gaps, we introduce ScratchMath, a novel benchmark specifically designed for explaining and classifying errors in authentic handwritten mathematics scratchwork. Our dataset comprises 1,720 mathematics samples from Chinese primary and middle school students, supporting two key tasks: Error Cause Explanation (ECE) and Error Cause Classification (ECC), with seven defined error types. The dataset is meticulously annotated through rigorous human-machine collaborative approaches involving multiple stages of expert labeling, review, and verification. We systematically evaluate 16 leading MLLMs on ScratchMath, revealing significant performance gaps relative to human experts, especially in visual recognition and logical reasoning. Proprietary models notably outperform open-source models, with large reasoning models showing strong potential for error explanation. All evaluation data and frameworks are publicly available to facilitate further research.
ReIn: Conversational Error Recovery with Reasoning Inception
Feb 19, 2026Conversational agents powered by large language models (LLMs) with tool integration achieve strong performance on fixed task-oriented dialogue datasets but remain vulnerable to unanticipated, user-induced errors. Rather than focusing on error prevention, this work focuses on error recovery, which necessitates the accurate diagnosis of erroneous dialogue contexts and execution of proper recovery plans. Under realistic constraints precluding model fine-tuning or prompt modification due to significant cost and time requirements, we explore whether agents can recover from contextually flawed interactions and how their behavior can be adapted without altering model parameters and prompts. To this end, we propose Reasoning Inception (ReIn), a test-time intervention method that plants an initial reasoning into the agent's decision-making process. Specifically, an external inception module identifies predefined errors within the dialogue context and generates recovery plans, which are subsequently integrated into the agent's internal reasoning process to guide corrective actions, without modifying its parameters or system prompts. We evaluate ReIn by systematically simulating conversational failure scenarios that directly hinder successful completion of user goals: user's ambiguous and unsupported requests. Across diverse combinations of agent models and inception modules, ReIn substantially improves task success and generalizes to unseen error types. Moreover, it consistently outperforms explicit prompt-modification approaches, underscoring its utility as an efficient, on-the-fly method. In-depth analysis of its operational mechanism, particularly in relation to instruction hierarchy, indicates that jointly defining recovery tools with ReIn can serve as a safe and effective strategy for improving the resilience of conversational agents without modifying the backbone models or system prompts.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
MAC: A Multi-Agent Framework for Interactive User Clarification in Multi-turn Conversations
Dec 15, 2025Conversational agents often encounter ambiguous user requests, requiring an effective clarification to successfully complete tasks. While recent advancements in real-world applications favor multi-agent architectures to manage complex conversational scenarios efficiently, ambiguity resolution remains a critical and underexplored challenge--particularly due to the difficulty of determining which agent should initiate a clarification and how agents should coordinate their actions when faced with uncertain or incomplete user input. The fundamental questions of when to interrupt a user and how to formulate the optimal clarification query within the most optimal multi-agent settings remain open. In this paper, we propose MAC (Multi-Agent Clarification), an interactive multi-agent framework specifically optimized to resolve user ambiguities by strategically managing clarification dialogues. We first introduce a novel taxonomy categorizing user ambiguities to systematically guide clarification strategies. Then, we present MAC that autonomously coordinates multiple agents to interact synergistically with users. Empirical evaluations on MultiWOZ 2.4 demonstrate that enabling clarification at both levels increases task success rate 7.8\% (54.5 to 62.3) and reduces the average number of dialogue turns (6.53 to 4.86) by eliciting all required user information up front and minimizing repetition. Our findings highlight the importance of active user interaction and role-aware clarification for more reliable human-agent communication.
SpeakRL: Synergizing Reasoning, Speaking, and Acting in Language Models with Reinforcement Learning
Dec 15, 2025
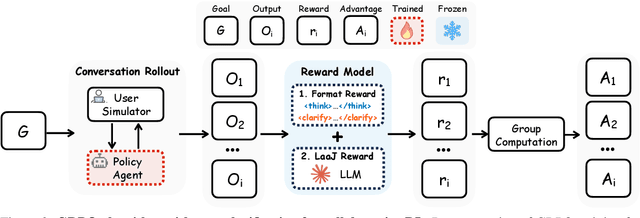
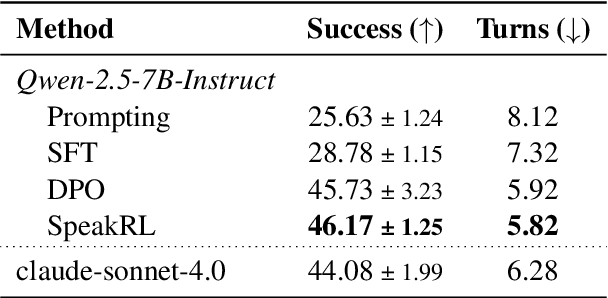
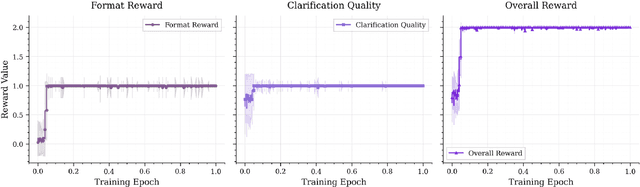
Effective human-agent collaboration is increasingly prevalent in real-world applications. Current trends in such collaborations are predominantly unidirectional, with users providing instructions or posing questions to agents, where agents respond directly without seeking necessary clarifications or confirmations. However, the evolving capabilities of these agents require more proactive engagement, where agents should dynamically participate in conversations to clarify user intents, resolve ambiguities, and adapt to changing circumstances. Existing prior work under-utilize the conversational capabilities of language models (LMs), thereby optimizing agents as better followers rather than effective speakers. In this work, we introduce SpeakRL, a reinforcement learning (RL) method that enhances agents' conversational capabilities by rewarding proactive interactions with users, such as asking right clarification questions when necessary. To support this, we curate SpeakER, a synthetic dataset that includes diverse scenarios from task-oriented dialogues, where tasks are resolved through interactive clarification questions. We present a systematic analysis of reward design for conversational proactivity and propose a principled reward formulation for teaching agents to balance asking with acting. Empirical evaluations demonstrate that our approach achieves a 20.14% absolute improvement in task completion over base models without increasing conversation turns even surpassing even much larger proprietary models, demonstrating the promise of clarification-centric user-agent interactions.
Multimodal Policy Internalization for Conversational Agents
Oct 10, 2025Modern conversational agents like ChatGPT and Alexa+ rely on predefined policies specifying metadata, response styles, and tool-usage rules. As these LLM-based systems expand to support diverse business and user queries, such policies, often implemented as in-context prompts, are becoming increasingly complex and lengthy, making faithful adherence difficult and imposing large fixed computational costs. With the rise of multimodal agents, policies that govern visual and multimodal behaviors are critical but remain understudied. Prior prompt-compression work mainly shortens task templates and demonstrations, while existing policy-alignment studies focus only on text-based safety rules. We introduce Multimodal Policy Internalization (MPI), a new task that internalizes reasoning-intensive multimodal policies into model parameters, enabling stronger policy-following without including the policy during inference. MPI poses unique data and algorithmic challenges. We build two datasets spanning synthetic and real-world decision-making and tool-using tasks and propose TriMPI, a three-stage training framework. TriMPI first injects policy knowledge via continual pretraining, then performs supervised finetuning, and finally applies PolicyRollout, a GRPO-style reinforcement learning extension that augments rollouts with policy-aware responses for grounded exploration. TriMPI achieves notable gains in end-to-end accuracy, generalization, and robustness to forgetting. As the first work on multimodal policy internalization, we provide datasets, training recipes, and comprehensive evaluations to foster future research. Project page: https://mikewangwzhl.github.io/TriMPI.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Memetic Search for Green Vehicle Routing Problem with Private Capacitated Refueling Stations
Apr 06, 2025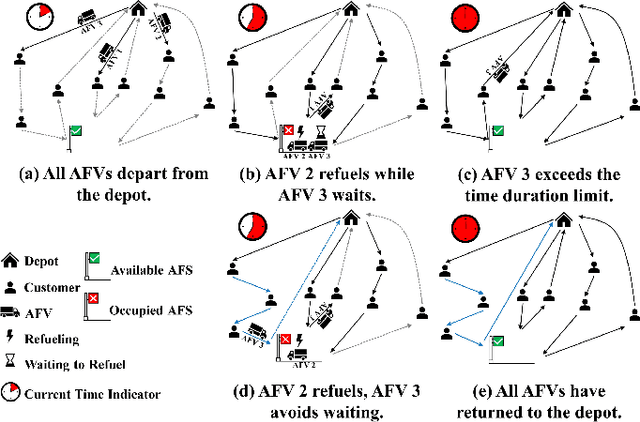
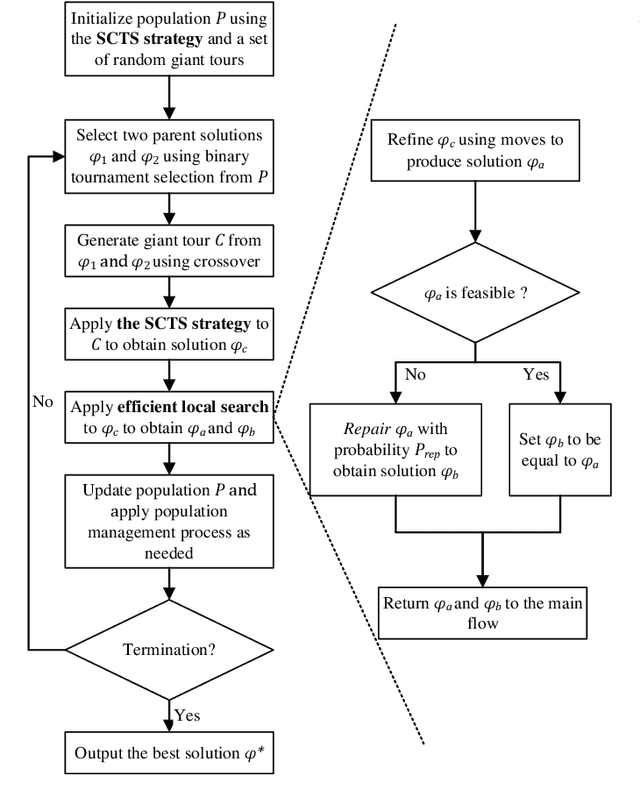
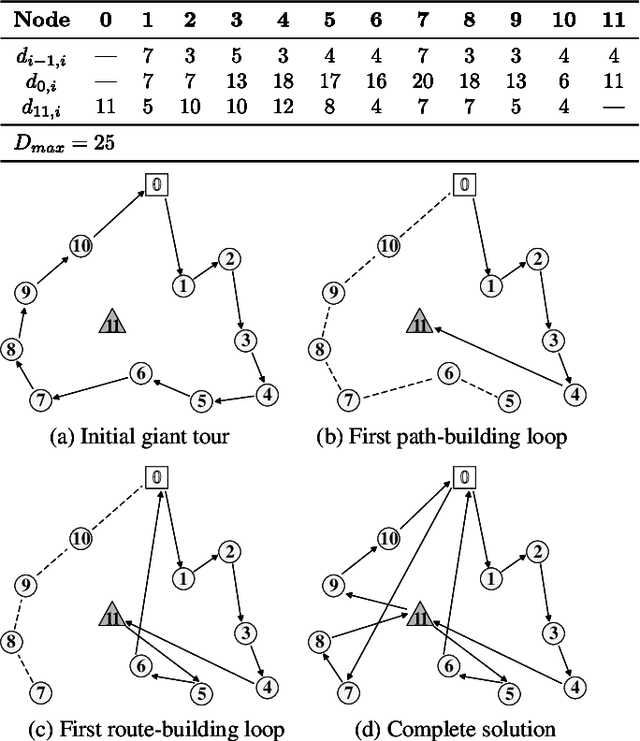
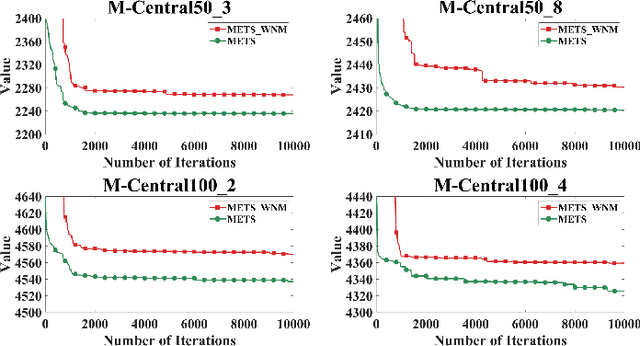
The green vehicle routing problem with private capacitated alternative fuel stations (GVRP-PCAFS) extends the traditional green vehicle routing problem by considering refueling stations limited capacity, where a limited number of vehicles can refuel simultaneously with additional vehicles must wait. This feature presents new challenges for route planning, as waiting times at stations must be managed while keeping route durations within limits and reducing total travel distance. This article presents METS, a novel memetic algorithm (MA) with separate constraint-based tour segmentation (SCTS) and efficient local search (ELS) for solving GVRP-PCAFS. METS combines global and local search effectively through three novelties. For global search, the SCTS strategy splits giant tours to generate diverse solutions, and the search process is guided by a comprehensive fitness evaluation function to dynamically control feasibility and diversity to produce solutions that are both diverse and near-feasible. For local search, ELS incorporates tailored move operators with constant-time move evaluation mechanisms, enabling efficient exploration of large solution neighborhoods. Experimental results demonstrate that METS discovers 31 new best-known solutions out of 40 instances in existing benchmark sets, achieving substantial improvements over current state-of-the-art methods. Additionally, a new large-scale benchmark set based on real-world logistics data is introduced to facilitate future research.
LLM-Virus: Evolutionary Jailbreak Attack on Large Language Models
Dec 28, 2024



While safety-aligned large language models (LLMs) are increasingly used as the cornerstone for powerful systems such as multi-agent frameworks to solve complex real-world problems, they still suffer from potential adversarial queries, such as jailbreak attacks, which attempt to induce harmful content. Researching attack methods allows us to better understand the limitations of LLM and make trade-offs between helpfulness and safety. However, existing jailbreak attacks are primarily based on opaque optimization techniques (e.g. token-level gradient descent) and heuristic search methods like LLM refinement, which fall short in terms of transparency, transferability, and computational cost. In light of these limitations, we draw inspiration from the evolution and infection processes of biological viruses and propose LLM-Virus, a jailbreak attack method based on evolutionary algorithm, termed evolutionary jailbreak. LLM-Virus treats jailbreak attacks as both an evolutionary and transfer learning problem, utilizing LLMs as heuristic evolutionary operators to ensure high attack efficiency, transferability, and low time cost. Our experimental results on multiple safety benchmarks show that LLM-Virus achieves competitive or even superior performance compared to existing attack methods.