 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Eval: Generalizable Multi-aspect Text Evaluation via Augmented Instruction Tuning with Auxiliary Evaluation Aspects
Nov 15, 2023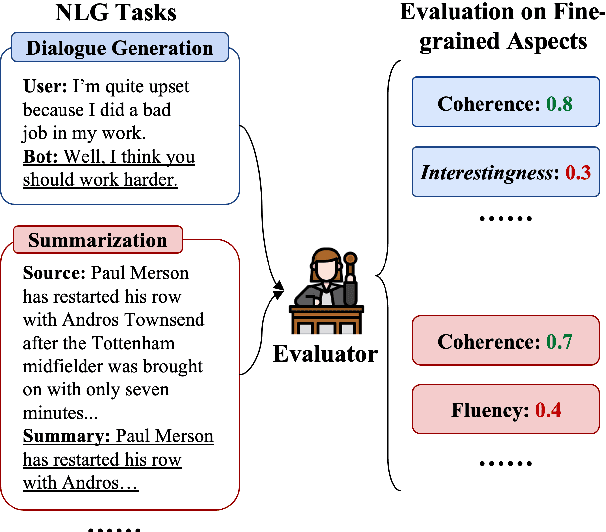
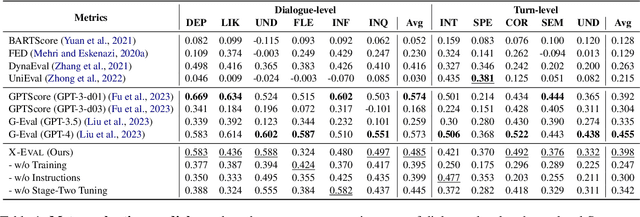
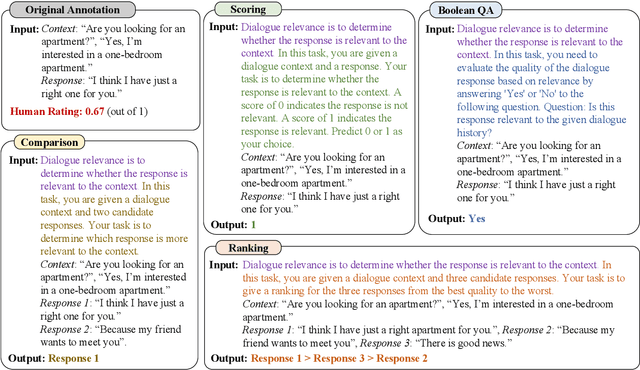
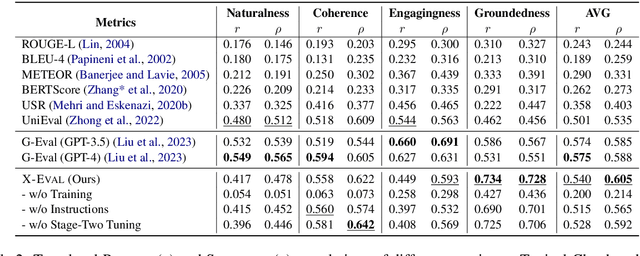
Natural Language Generation (NLG) typically involves evaluating the generated text in various aspects (e.g., consistency and naturalness) to obtain a comprehensive assessment. However, multi-aspect evaluation remains challenging as it may require the evaluator to generalize to any given evaluation aspect even if it's absent during training. In this paper, we introduce X-Eval, a two-stage instruction tuning framework to evaluate the text in both seen and unseen aspects customized by end users. X-Eval consists of two learning stages: the vanilla instruction tuning stage that improves the model's ability to follow evaluation instructions, and an enhanced instruction tuning stage that exploits the connections between fine-grained evaluation aspects to better assess text quality. To support the training of X-Eval, we collect AspectInstruct, the first instruction tuning dataset tailored for multi-aspect NLG evaluation spanning 27 diverse evaluation aspects with 65 tasks. To enhance task diversity, we devise an augmentation strategy that converts human rating annotations into diverse forms of NLG evaluation tasks, including scoring, comparison, ranking, and Boolean question answering. Extensive experiments across three essential categories of NLG tasks: dialogue generation, summarization, and data-to-text coupled with 21 aspects in meta-evaluation, demonstrate that our X-Eval enables even a lightweight language model to achieve a comparable if not higher correlation with human judgments compared to the state-of-the-art NLG evaluators, such as GPT-4.
RecMind: Large Language Model Powered Agent For Recommendation
Aug 28, 2023



Recent advancements in instructing Large Language Models (LLMs) to utilize external tools and execute multi-step plans have significantly enhanced their ability to solve intricate tasks, ranging from mathematical problems to creative writing. Yet, there remains a notable gap in studying the capacity of LLMs in responding to personalized queries such as a recommendation request. To bridge this gap, we have designed an LLM-powered autonomous recommender agent, RecMind, which is capable of providing precise personalized recommendations through careful planning, utilizing tools for obtaining external knowledge, and leveraging individual data. We propose a novel algorithm, Self-Inspiring, to improve the planning ability of the LLM agent. At each intermediate planning step, the LLM 'self-inspires' to consider all previously explored states to plan for next step. This mechanism greatly improves the model's ability to comprehend and utilize historical planning information for recommendation. We evaluate RecMind's performance in various recommendation scenarios, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Our experiment shows that RecMind outperforms existing zero/few-shot LLM-based recommendation methods in different recommendation tasks and achieves competitive performance to a recent model P5, which requires fully pre-train for the recommendation tasks.
KG-ECO: Knowledge Graph Enhanced Entity Correction for Query Rewriting
Feb 22, 2023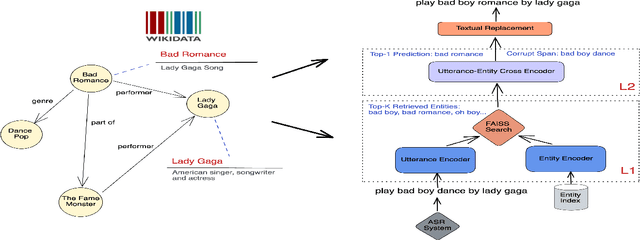

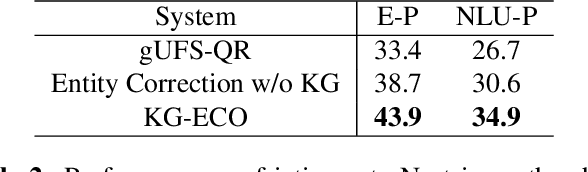
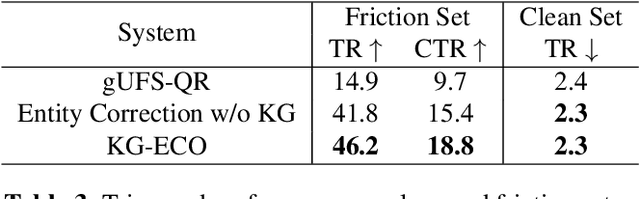
Query Rewriting (QR) plays a critical role in large-scale dialogue systems for reducing frictions. When there is an entity error, it imposes extra challenges for a dialogue system to produce satisfactory responses. In this work, we propose KG-ECO: Knowledge Graph enhanced Entity COrrection for query rewriting, an entity correction system with corrupt entity span detection and entity retrieval/re-ranking functionalities. To boost the model performance, we incorporate Knowledge Graph (KG) to provide entity structural information (neighboring entities encoded by graph neural networks) and textual information (KG entity descriptions encoded by RoBERTa). Experimental results show that our approach yields a clear performance gain over two baselines: utterance level QR and entity correction without utilizing KG information. The proposed system is particularly effective for few-shot learning cases where target entities are rarely seen in training or there is a KG relation between the target entity and other contextual entities in the query.
Low Latency ASR for Simultaneous Speech Translation
Mar 22, 2020

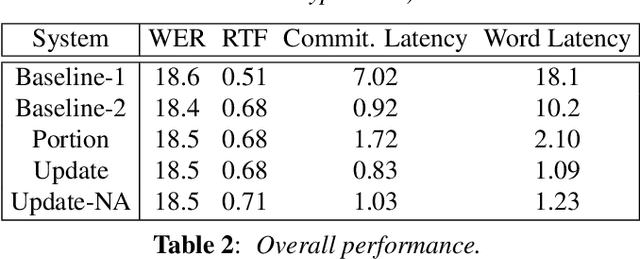
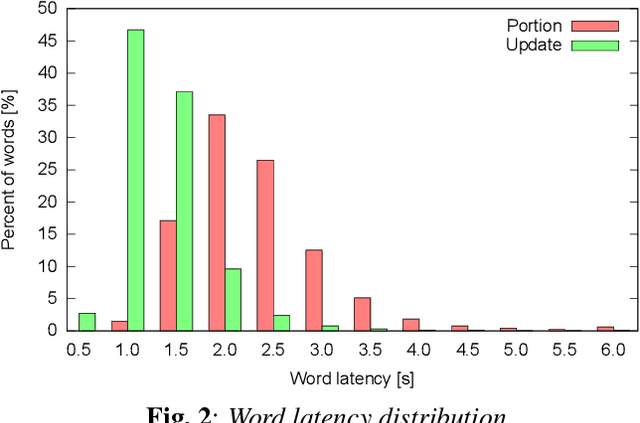
User studies have shown that reducing the latency of our simultaneous lecture translation system should be the most important goal. We therefore have worked on several techniques for reducing the latency for both components, the automatic speech recognition and the speech translation module. Since the commonly used commitment latency is not appropriate in our case of continuous stream decoding, we focused on word latency. We used it to analyze the performance of our current system and to identify opportunities for improvements. In order to minimize the latency we combined run-on decoding with a technique for identifying stable partial hypotheses when stream decoding and a protocol for dynamic output update that allows to revise the most recent parts of the transcription. This combination reduces the latency at word level, where the words are final and will never be updated again in the future, from 18.1s to 1.1s without sacrificing performance in terms of word error rate.
Data Augmentation using Pre-trained Transformer Models
Mar 04, 2020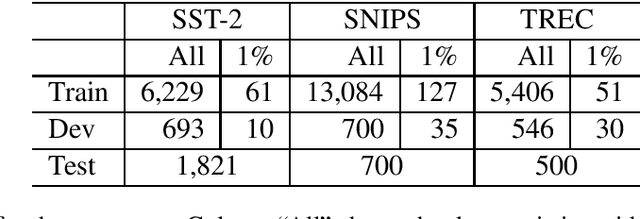

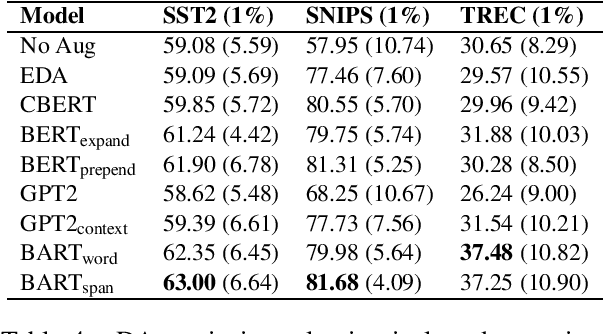
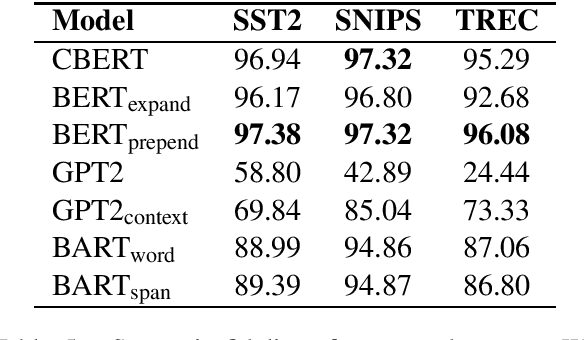
Language model based pre-trained models such as BERT have provided significant gains across different NLP tasks. In this paper, we study different types of pre-trained transformer based models such as auto-regressive models (GPT-2), auto-encoder models (BERT), and seq2seq models (BART) for conditional data augmentation. We show that prepending the class labels to text sequences provides a simple yet effective way to condition the pre-trained models for data augmentation. On three classification benchmarks, pre-trained Seq2Seq model outperforms other models. Further, we explore how different pre-trained model based data augmentation differs in-terms of data diversity, and how well such methods preserve the class-label information.
Efficient Semi-Supervised Learning for Natural Language Understanding by Optimizing Diversity
Oct 09, 2019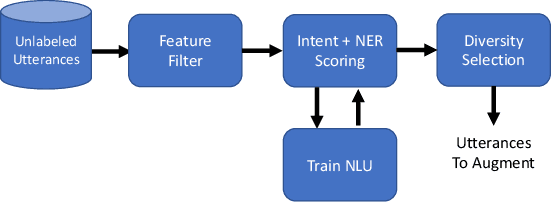
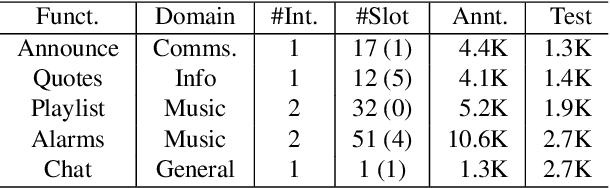
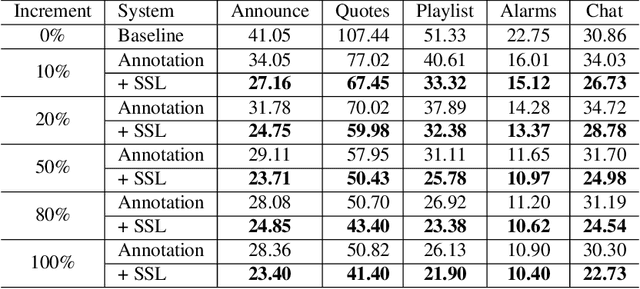
Expanding new functionalities efficiently is an ongoing challenge for single-turn task-oriented dialogue systems. In this work, we explore functionality-specific semi-supervised learning via self-training. We consider methods that augment training data automatically from unlabeled data sets in a functionality-targeted manner. In addition, we examine multiple techniques for efficient selection of augmented utterances to reduce training time and increase diversity. First, we consider paraphrase detection methods that attempt to find utterance variants of labeled training data with good coverage. Second, we explore sub-modular optimization based on n-grams features for utterance selection. Experiments show that functionality-specific self-training is very effective for improving system performance. In addition, methods optimizing diversity can reduce training data in many cases to 50% with little impact on performance.
Exploiting Linguistic Resources for Neural Machine Translation Using Multi-task Learning
Aug 03, 2017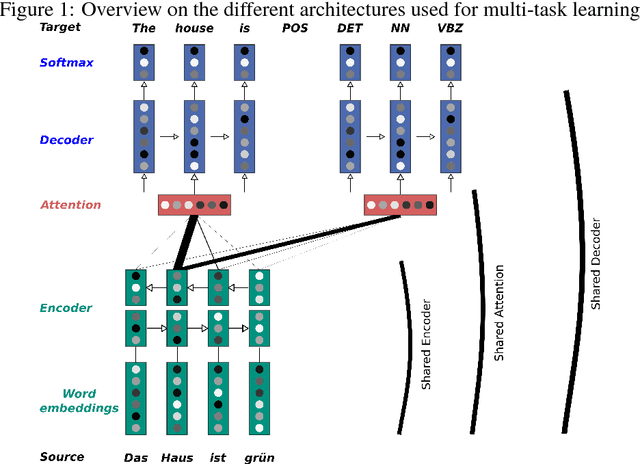

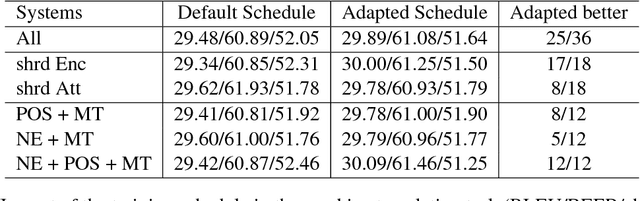

Linguistic resources such as part-of-speech (POS) tags have been extensively used in statistical machine translation (SMT) frameworks and have yielded better performances. However, usage of such linguistic annotations in neural machine translation (NMT) systems has been left under-explored. In this work, we show that multi-task learning is a successful and a easy approach to introduce an additional knowledge into an end-to-end neural attentional model. By jointly training several natural language processing (NLP) tasks in one system, we are able to leverage common information and improve the performance of the individual task. We analyze the impact of three design decisions in multi-task learning: the tasks used in training, the training schedule, and the degree of parameter sharing across the tasks, which is defined by the network architecture. The experiments are conducted for an German to English translation task. As additional linguistic resources, we exploit POS information and named-entities (NE). Experiments show that the translation quality can be improved by up to 1.5 BLEU points under the low-resource condition. The performance of the POS tagger is also improved using the multi-task learning scheme.
Analyzing Neural MT Search and Model Performance
Aug 02, 2017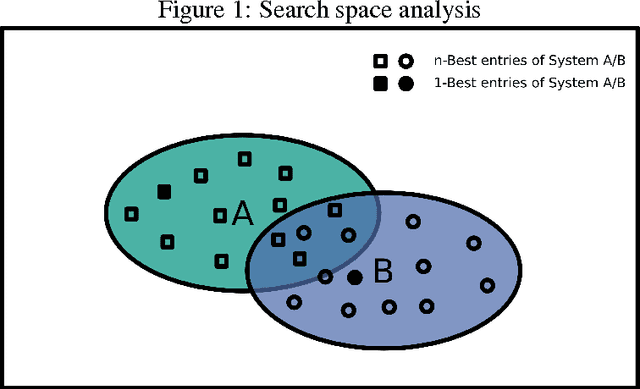
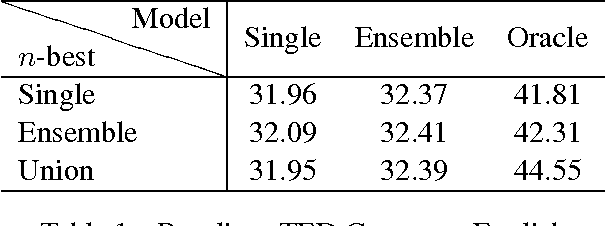

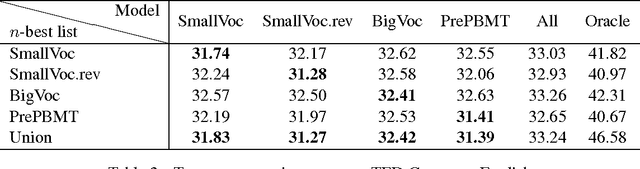
In this paper, we offer an in-depth analysis about the modeling and search performance. We address the question if a more complex search algorithm is necessary. Furthermore, we investigate the question if more complex models which might only be applicable during rescoring are promising. By separating the search space and the modeling using $n$-best list reranking, we analyze the influence of both parts of an NMT system independently. By comparing differently performing NMT systems, we show that the better translation is already in the search space of the translation systems with less performance. This results indicate that the current search algorithms are sufficient for the NMT systems. Furthermore, we could show that even a relatively small $n$-best list of $50$ hypotheses already contain notably better translations.
Pre-Translation for Neural Machine Translation
Oct 17, 2016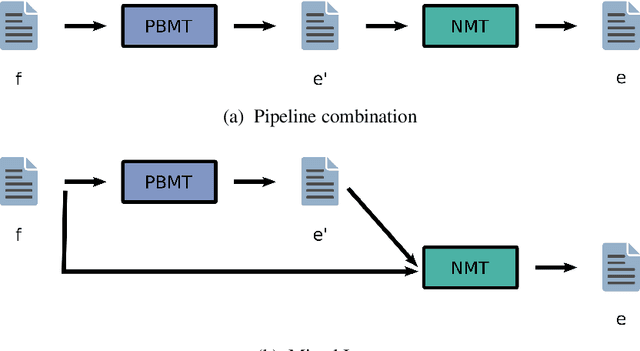
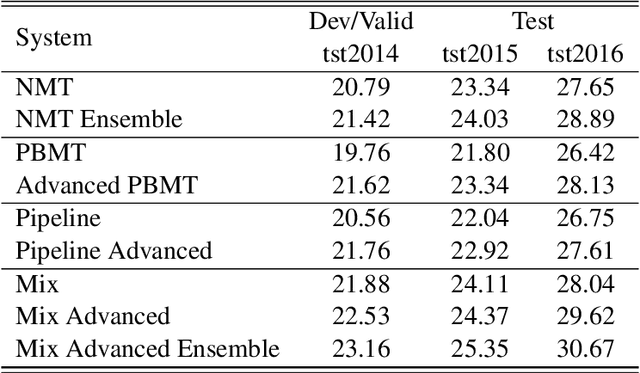
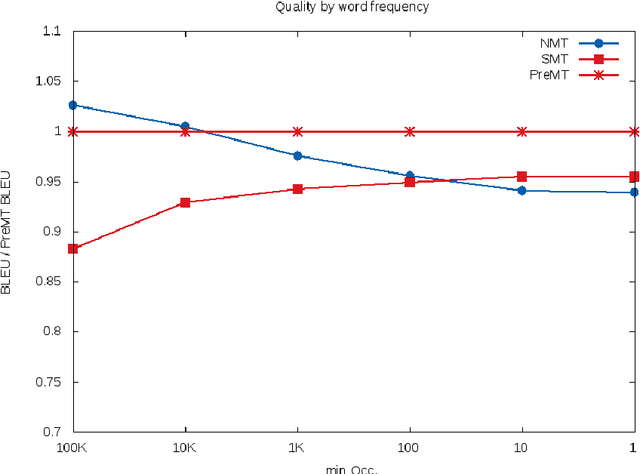

Recently, the development of neural machine translation (NMT) has significantly improved the translation quality of automatic machine translation. While most sentences are more accurate and fluent than translations by statistical machine translation (SMT)-based systems, in some cases, the NMT system produces translations that have a completely different meaning. This is especially the case when rare words occur. When using statistical machine translation, it has already been shown that significant gains can be achieved by simplifying the input in a preprocessing step. A commonly used example is the pre-reordering approach. In this work, we used phrase-based machine translation to pre-translate the input into the target language. Then a neural machine translation system generates the final hypothesis using the pre-translation. Thereby, we use either only the output of the phrase-based machine translation (PBMT) system or a combination of the PBMT output and the source sentence. We evaluate the technique on the English to German translation task. Using this approach we are able to outperform the PBMT system as well as the baseline neural MT system by up to 2 BLEU points. We analyzed the influence of the quality of the initial system on the final result.