 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Eval: Generalizable Multi-aspect Text Evaluation via Augmented Instruction Tuning with Auxiliary Evaluation Aspects
Paper and Code
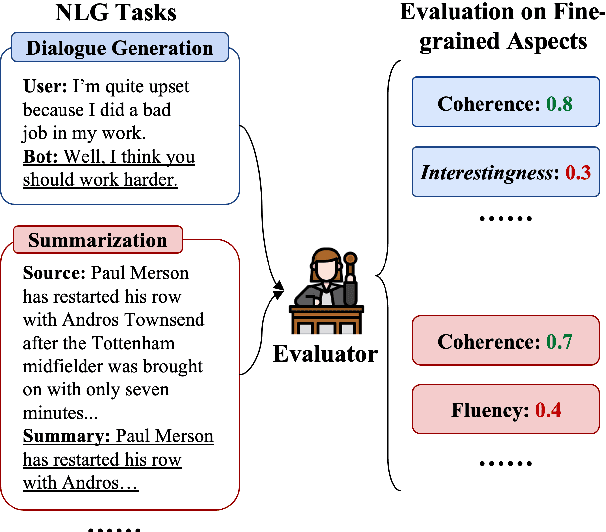
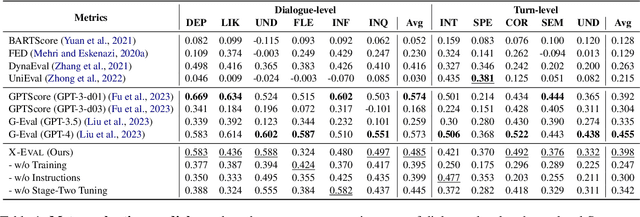
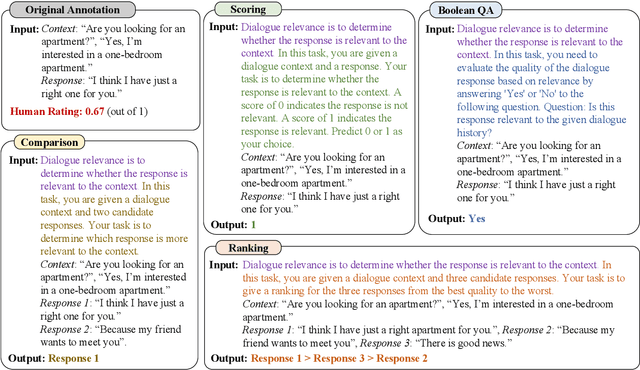
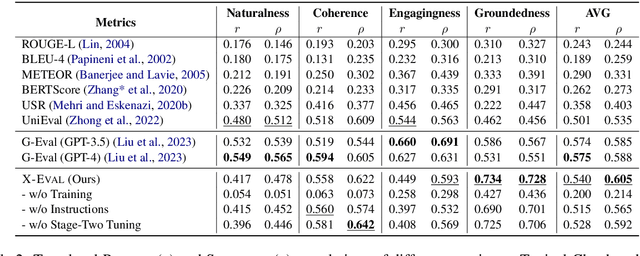
Natural Language Generation (NLG) typically involves evaluating the generated text in various aspects (e.g., consistency and naturalness) to obtain a comprehensive assessment. However, multi-aspect evaluation remains challenging as it may require the evaluator to generalize to any given evaluation aspect even if it's absent during training. In this paper, we introduce X-Eval, a two-stage instruction tuning framework to evaluate the text in both seen and unseen aspects customized by end users. X-Eval consists of two learning stages: the vanilla instruction tuning stage that improves the model's ability to follow evaluation instructions, and an enhanced instruction tuning stage that exploits the connections between fine-grained evaluation aspects to better assess text quality. To support the training of X-Eval, we collect AspectInstruct, the first instruction tuning dataset tailored for multi-aspect NLG evaluation spanning 27 diverse evaluation aspects with 65 tasks. To enhance task diversity, we devise an augmentation strategy that converts human rating annotations into diverse forms of NLG evaluation tasks, including scoring, comparison, ranking, and Boolean question answering. Extensive experiments across three essential categories of NLG tasks: dialogue generation, summarization, and data-to-text coupled with 21 aspects in meta-evaluation, demonstrate that our X-Eval enables even a lightweight language model to achieve a comparable if not higher correlation with human judgments compared to the state-of-the-art NLG evaluators, such as GPT-4.