 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Neural Machine Translation For Low-Resource Languages: French-, English- Vietnamese
Dec 16, 2020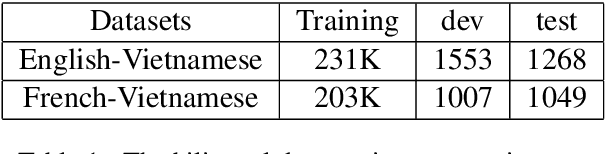
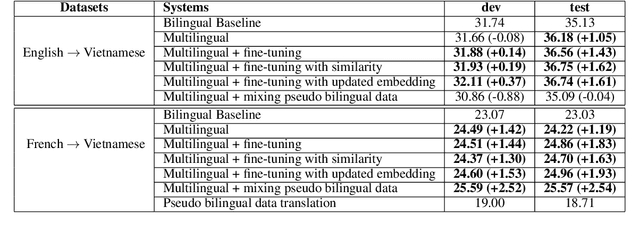
Prior works have demonstrated that a low-resource language pair can benefit from multilingual machine translation (MT) systems, which rely on many language pairs' joint training. This paper proposes two simple strategies to address the rare word issue in multilingual MT systems for two low-resource language pairs: French-Vietnamese and English-Vietnamese. The first strategy is about dynamical learning word similarity of tokens in the shared space among source languages while another one attempts to augment the translation ability of rare words through updating their embeddings during the training. Besides, we leverage monolingual data for multilingual MT systems to increase the amount of synthetic parallel corpora while dealing with the data sparsity problem. We have shown significant improvements of up to +1.62 and +2.54 BLEU points over the bilingual baseline systems for both language pairs and released our datasets for the research community.
Relative Positional Encoding for Speech Recognition and Direct Translation
May 20, 2020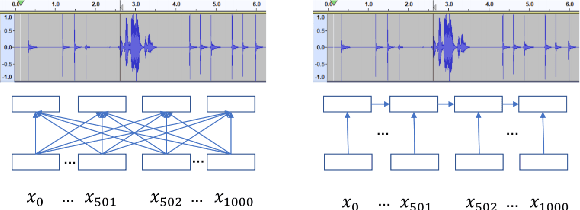
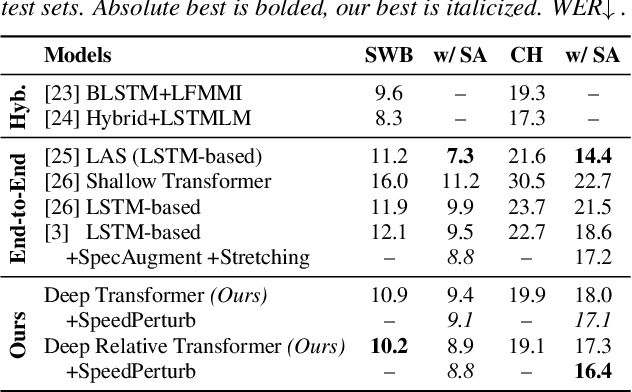


Transformer models are powerful sequence-to-sequence architectures that are capable of directly mapping speech inputs to transcriptions or translations. However, the mechanism for modeling positions in this model was tailored for text modeling, and thus is less ideal for acoustic inputs. In this work, we adapt the relative position encoding scheme to the Speech Transformer, where the key addition is relative distance between input states in the self-attention network. As a result, the network can better adapt to the variable distributions present in speech data. Our experiments show that our resulting model achieves the best recognition result on the Switchboard benchmark in the non-augmentation condition, and the best published result in the MuST-C speech translation benchmark. We also show that this model is able to better utilize synthetic data than the Transformer, and adapts better to variable sentence segmentation quality for speech translation.
Low Latency ASR for Simultaneous Speech Translation
Mar 22, 2020

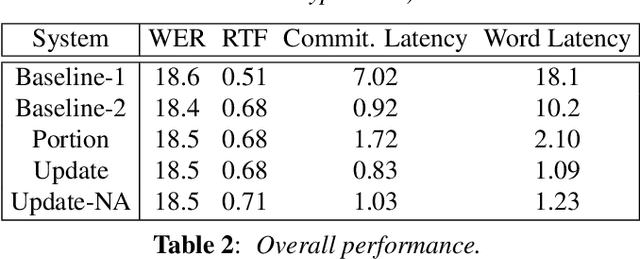
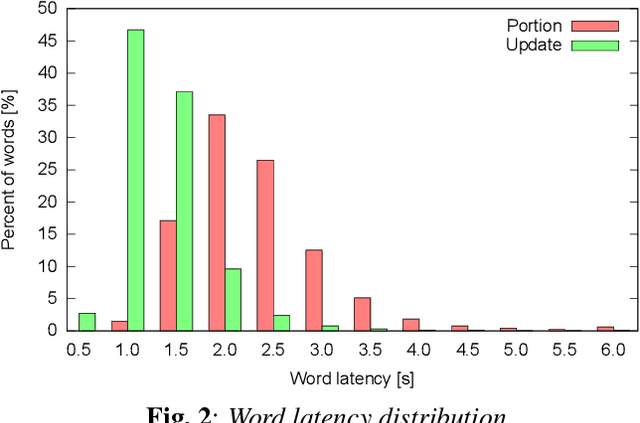
User studies have shown that reducing the latency of our simultaneous lecture translation system should be the most important goal. We therefore have worked on several techniques for reducing the latency for both components, the automatic speech recognition and the speech translation module. Since the commonly used commitment latency is not appropriate in our case of continuous stream decoding, we focused on word latency. We used it to analyze the performance of our current system and to identify opportunities for improvements. In order to minimize the latency we combined run-on decoding with a technique for identifying stable partial hypotheses when stream decoding and a protocol for dynamic output update that allows to revise the most recent parts of the transcription. This combination reduces the latency at word level, where the words are final and will never be updated again in the future, from 18.1s to 1.1s without sacrificing performance in terms of word error rate.
How Transformer Revitalizes Character-based Neural Machine Translation: An Investigation on Japanese-Vietnamese Translation Systems
Oct 17, 2019
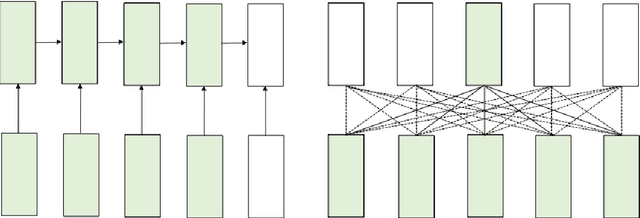
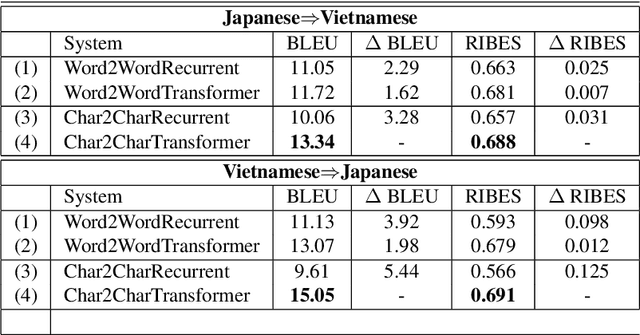
While translating between East Asian languages, many works have discovered clear advantages of using characters as the translation unit. Unfortunately, traditional recurrent neural machine translation systems hinder the practical usage of those character-based systems due to their architectural limitations. They are unfavorable in handling extremely long sequences as well as highly restricted in parallelizing the computations. In this paper, we demonstrate that the new transformer architecture can perform character-based translation better than the recurrent one. We conduct experiments on a low-resource language pair: Japanese-Vietnamese. Our models considerably outperform the state-of-the-art systems which employ word-based recurrent architectures.
Overcoming the Rare Word Problem for Low-Resource Language Pairs in Neural Machine Translation
Oct 17, 2019



Among the six challenges of neural machine translation (NMT) coined by (Koehn and Knowles, 2017), rare-word problem is considered the most severe one, especially in translation of low-resource languages. In this paper, we propose three solutions to address the rare words in neural machine translation systems. First, we enhance source context to predict the target words by connecting directly the source embeddings to the output of the attention component in NMT. Second, we propose an algorithm to learn morphology of unknown words for English in supervised way in order to minimize the adverse effect of rare-word problem. Finally, we exploit synonymous relation from the WordNet to overcome out-of-vocabulary (OOV) problem of NMT. We evaluate our approaches on two low-resource language pairs: English-Vietnamese and Japanese-Vietnamese. In our experiments, we have achieved significant improvements of up to roughly +1.0 BLEU points in both language pairs.
Improving Zero-shot Translation with Language-Independent Constraints
Jun 20, 2019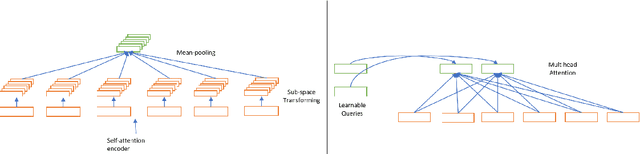
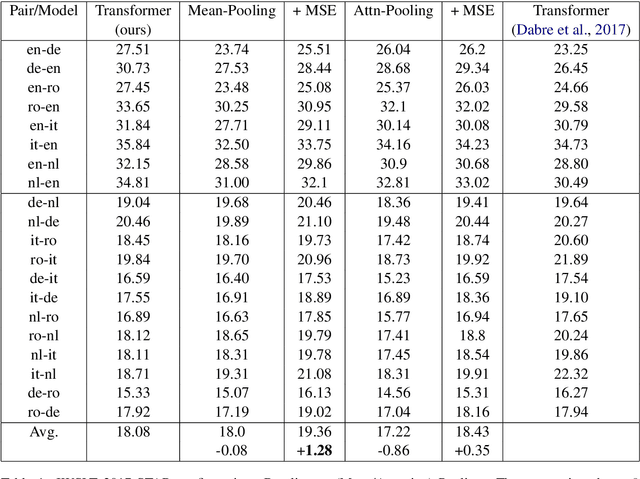

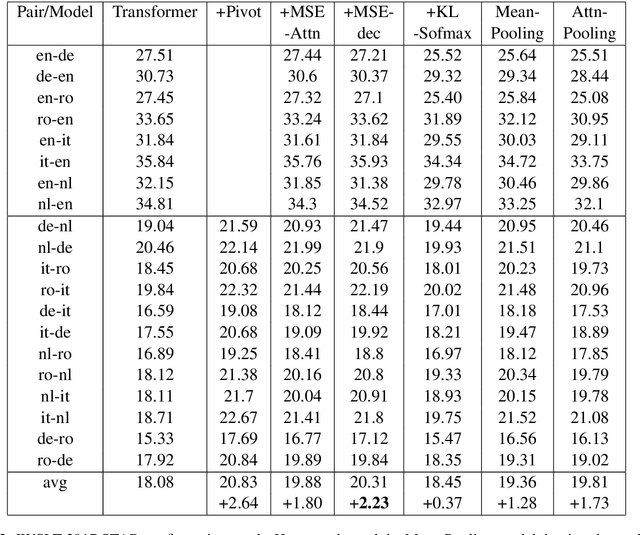
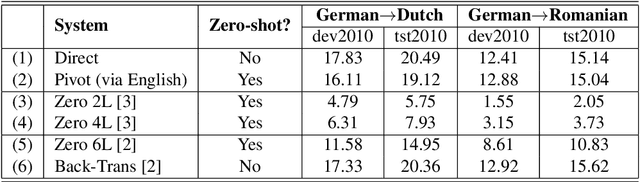
An important concern in training multilingual neural machine translation (NMT) is to translate between language pairs unseen during training, i.e zero-shot translation. Improving this ability kills two birds with one stone by providing an alternative to pivot translation which also allows us to better understand how the model captures information between languages. In this work, we carried out an investigation on this capability of the multilingual NMT models. First, we intentionally create an encoder architecture which is independent with respect to the source language. Such experiments shed light on the ability of NMT encoders to learn multilingual representations, in general. Based on such proof of concept, we were able to design regularization methods into the standard Transformer model, so that the whole architecture becomes more robust in zero-shot conditions. We investigated the behaviour of such models on the standard IWSLT 2017 multilingual dataset. We achieved an average improvement of 2.23 BLEU points across 12 language pairs compared to the zero-shot performance of a state-of-the-art multilingual system. Additionally, we carry out further experiments in which the effect is confirmed even for language pairs with multiple intermediate pivots.
Low-Latency Neural Speech Translation
Aug 01, 2018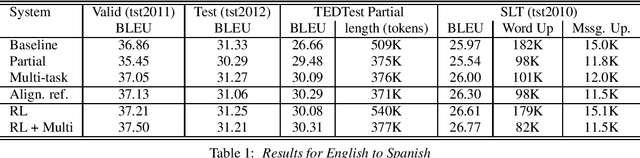
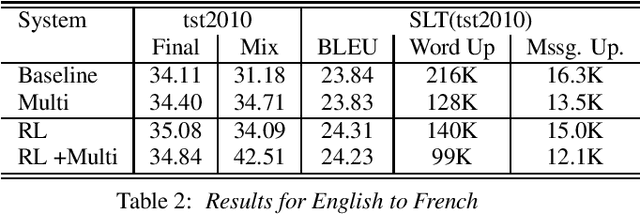
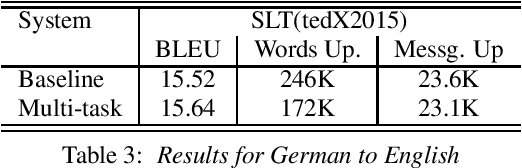
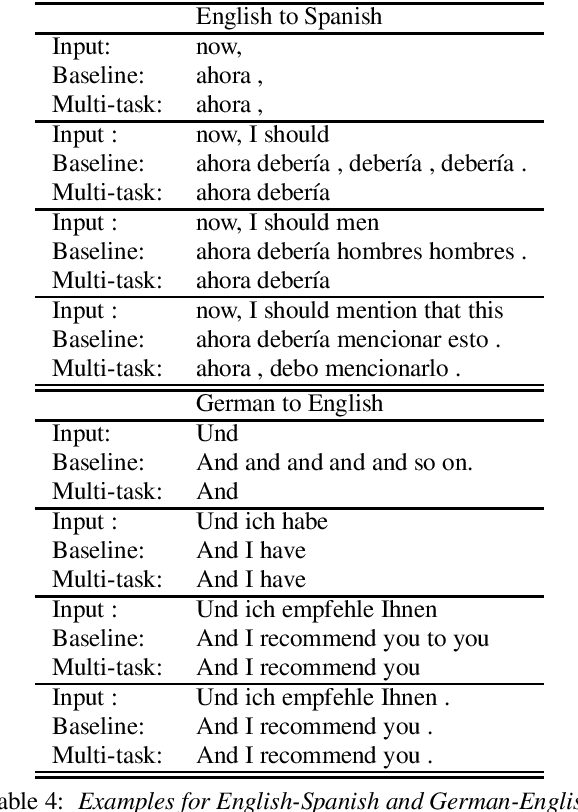
Through the development of neural machine translation, the quality of machine translation systems has been improved significantly. By exploiting advancements in deep learning, systems are now able to better approximate the complex mapping from source sentences to target sentences. But with this ability, new challenges also arise. An example is the translation of partial sentences in low-latency speech translation. Since the model has only seen complete sentences in training, it will always try to generate a complete sentence, though the input may only be a partial sentence. We show that NMT systems can be adapted to scenarios where no task-specific training data is available. Furthermore, this is possible without losing performance on the original training data. We achieve this by creating artificial data and by using multi-task learning. After adaptation, we are able to reduce the number of corrections displayed during incremental output construction by 45%, without a decrease in translation quality.
Combining Advanced Methods in Japanese-Vietnamese Neural Machine Translation
May 18, 2018
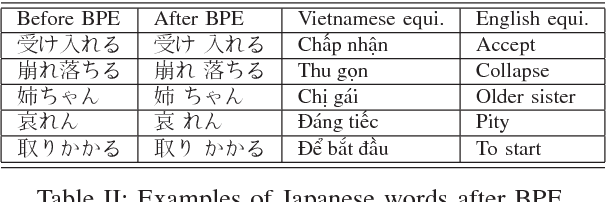
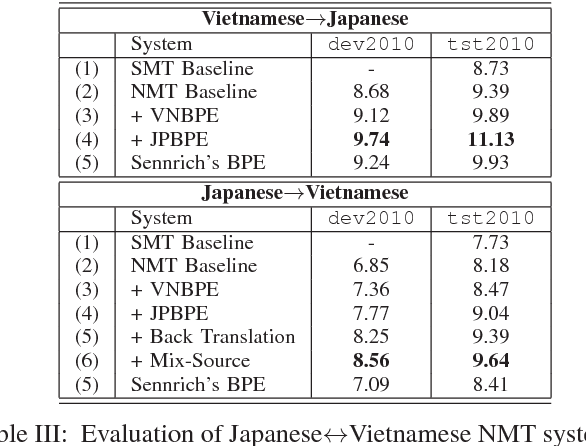
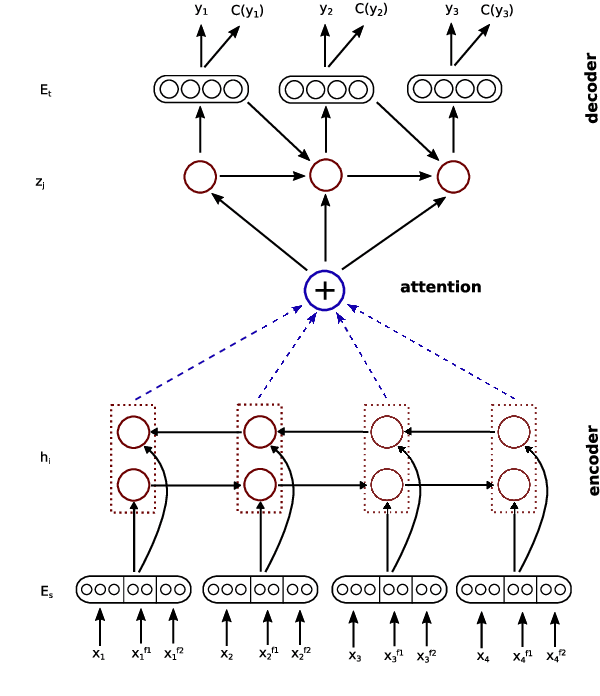
Neural machine translation (NMT) systems have recently obtained state-of-the art in many machine translation systems between popular language pairs because of the availability of data. For low-resourced language pairs, there are few researches in this field due to the lack of bilingual data. In this paper, we attempt to build the first NMT systems for a low-resourced language pairs:Japanese-Vietnamese. We have also shown significant improvements when combining advanced methods to reduce the adverse impacts of data sparsity and improve the quality of NMT systems. In addition, we proposed a variant of Byte-Pair Encoding algorithm to perform effective word segmentation for Vietnamese texts and alleviate the rare-word problem that persists in NMT systems.
Effective Strategies in Zero-Shot Neural Machine Translation
Nov 22, 2017
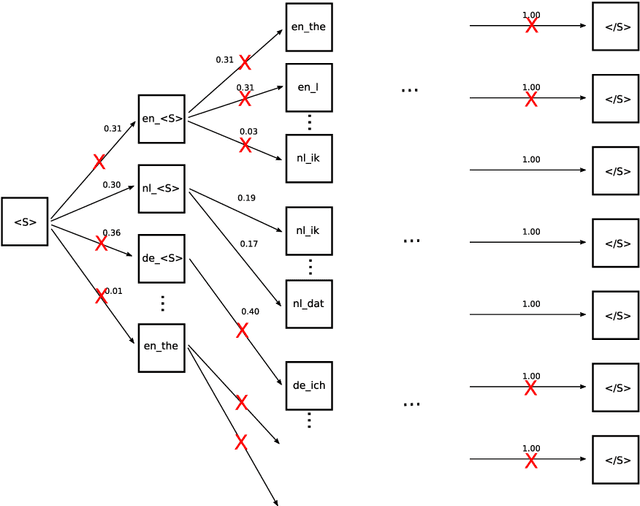
In this paper, we proposed two strategies which can be applied to a multilingual neural machine translation system in order to better tackle zero-shot scenarios despite not having any parallel corpus. The experiments show that they are effective in terms of both performance and computing resources, especially in multilingual translation of unbalanced data in real zero-resourced condition when they alleviate the language bias problem.
Analyzing Neural MT Search and Model Performance
Aug 02, 2017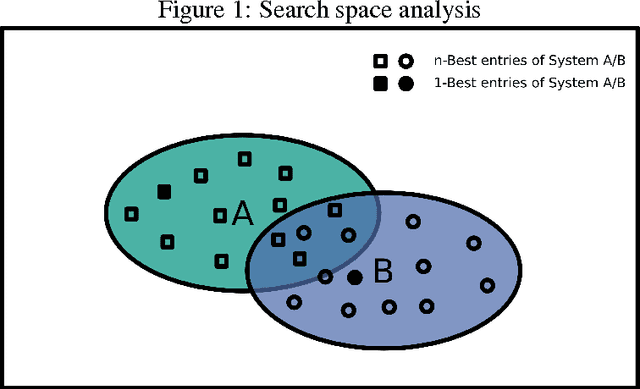
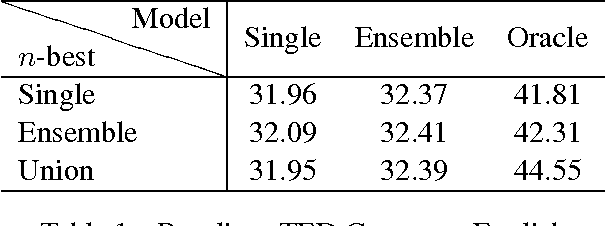

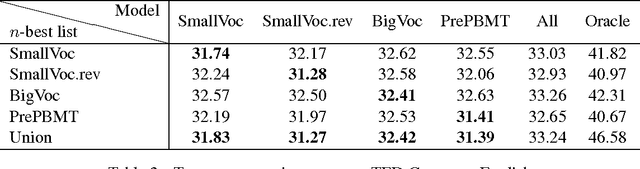
In this paper, we offer an in-depth analysis about the modeling and search performance. We address the question if a more complex search algorithm is necessary. Furthermore, we investigate the question if more complex models which might only be applicable during rescoring are promising. By separating the search space and the modeling using $n$-best list reranking, we analyze the influence of both parts of an NMT system independently. By comparing differently performing NMT systems, we show that the better translation is already in the search space of the translation systems with less performance. This results indicate that the current search algorithms are sufficient for the NMT systems. Furthermore, we could show that even a relatively small $n$-best list of $50$ hypotheses already contain notably better translations.