 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Neural Machine Translation For Low-Resource Languages: French-, English- Vietnamese
Dec 16, 2020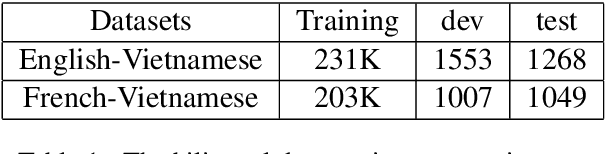
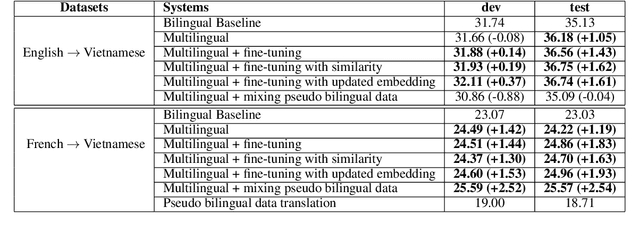
Prior works have demonstrated that a low-resource language pair can benefit from multilingual machine translation (MT) systems, which rely on many language pairs' joint training. This paper proposes two simple strategies to address the rare word issue in multilingual MT systems for two low-resource language pairs: French-Vietnamese and English-Vietnamese. The first strategy is about dynamical learning word similarity of tokens in the shared space among source languages while another one attempts to augment the translation ability of rare words through updating their embeddings during the training. Besides, we leverage monolingual data for multilingual MT systems to increase the amount of synthetic parallel corpora while dealing with the data sparsity problem. We have shown significant improvements of up to +1.62 and +2.54 BLEU points over the bilingual baseline systems for both language pairs and released our datasets for the research community.
How Transformer Revitalizes Character-based Neural Machine Translation: An Investigation on Japanese-Vietnamese Translation Systems
Oct 17, 2019
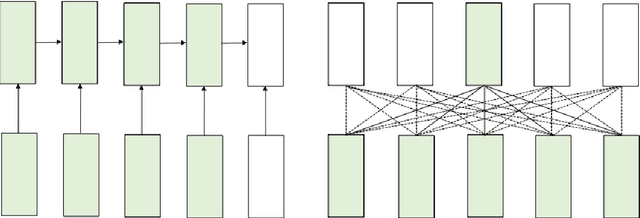
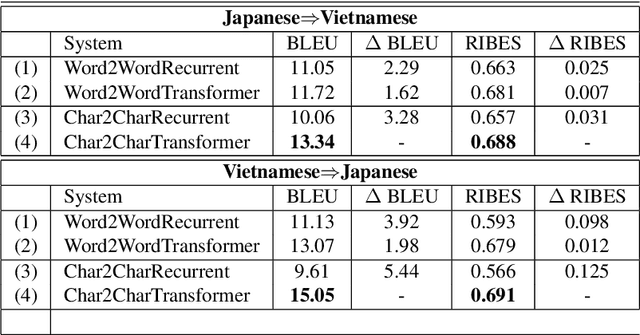
While translating between East Asian languages, many works have discovered clear advantages of using characters as the translation unit. Unfortunately, traditional recurrent neural machine translation systems hinder the practical usage of those character-based systems due to their architectural limitations. They are unfavorable in handling extremely long sequences as well as highly restricted in parallelizing the computations. In this paper, we demonstrate that the new transformer architecture can perform character-based translation better than the recurrent one. We conduct experiments on a low-resource language pair: Japanese-Vietnamese. Our models considerably outperform the state-of-the-art systems which employ word-based recurrent architectures.
Overcoming the Rare Word Problem for Low-Resource Language Pairs in Neural Machine Translation
Oct 17, 2019



Among the six challenges of neural machine translation (NMT) coined by (Koehn and Knowles, 2017), rare-word problem is considered the most severe one, especially in translation of low-resource languages. In this paper, we propose three solutions to address the rare words in neural machine translation systems. First, we enhance source context to predict the target words by connecting directly the source embeddings to the output of the attention component in NMT. Second, we propose an algorithm to learn morphology of unknown words for English in supervised way in order to minimize the adverse effect of rare-word problem. Finally, we exploit synonymous relation from the WordNet to overcome out-of-vocabulary (OOV) problem of NMT. We evaluate our approaches on two low-resource language pairs: English-Vietnamese and Japanese-Vietnamese. In our experiments, we have achieved significant improvements of up to roughly +1.0 BLEU points in both language pairs.
Combining Advanced Methods in Japanese-Vietnamese Neural Machine Translation
May 18, 2018
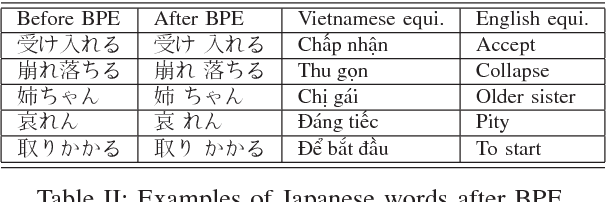
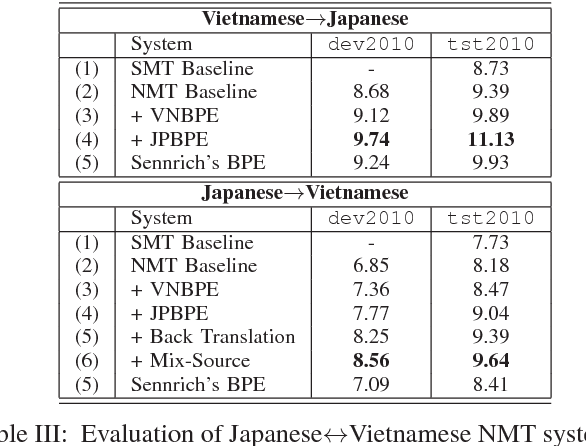
Neural machine translation (NMT) systems have recently obtained state-of-the art in many machine translation systems between popular language pairs because of the availability of data. For low-resourced language pairs, there are few researches in this field due to the lack of bilingual data. In this paper, we attempt to build the first NMT systems for a low-resourced language pairs:Japanese-Vietnamese. We have also shown significant improvements when combining advanced methods to reduce the adverse impacts of data sparsity and improve the quality of NMT systems. In addition, we proposed a variant of Byte-Pair Encoding algorithm to perform effective word segmentation for Vietnamese texts and alleviate the rare-word problem that persists in NMT systems.