 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Forgetting: Machine Unlearning Elicits Controllable Side Behaviors and Capabilities
Jan 29, 2026We consider representation misdirection (RM), a class of LLM unlearning methods that achieves forgetting by manipulating the forget-representations, that is, latent representations of forget samples. Despite being important, the roles of target vectors used in RM, however, remain underexplored. Here, we approach and revisit RM through the lens of the linear representation hypothesis. Specifically, if one can somehow identify a one-dimensional representation corresponding to a high-level concept, the linear representation hypothesis enables linear operations on this concept vector within the forget-representation space. Under this view, we hypothesize that, beyond forgetting, machine unlearning elicits controllable side behaviors and stronger side capabilities corresponding to the high-level concept. Our hypothesis is empirically validated across a wide range of tasks, including behavioral control (e.g., controlling unlearned models' truth, sentiment, and refusal) and capability enhancement (e.g., improving unlearned models' in-context learning capability). Our findings reveal that this fairly attractive phenomenon could be either a hidden risk if misused or a mechanism that can be harnessed for developing models that require stronger capabilities and controllable behaviors.
Can Legislation Be Made Machine-Readable in PROLEG?
Jan 04, 2026The anticipated positive social impact of regulatory processes requires both the accuracy and efficiency of their application. Modern artificial intelligence technologies, including natural language processing and machine-assisted reasoning, hold great promise for addressing this challenge. We present a framework to address the challenge of tools for regulatory application, based on current state-of-the-art (SOTA) methods for natural language processing (large language models or LLMs) and formalization of legal reasoning (the legal representation system PROLEG). As an example, we focus on Article 6 of the European General Data Protection Regulation (GDPR). In our framework, a single LLM prompt simultaneously transforms legal text into if-then rules and a corresponding PROLEG encoding, which are then validated and refined by legal domain experts. The final output is an executable PROLEG program that can produce human-readable explanations for instances of GDPR decisions. We describe processes to support the end-to-end transformation of a segment of a regulatory document (Article 6 from GDPR), including the prompting frame to guide an LLM to "compile" natural language text to if-then rules, then to further "compile" the vetted if-then rules to PROLEG. Finally, we produce an instance that shows the PROLEG execution. We conclude by summarizing the value of this approach and note observed limitations with suggestions to further develop such technologies for capturing and deploying regulatory frameworks.
Finetuning LLMs for Automatic Form Interaction on Web-Browser in Selenium Testing Framework
Nov 19, 2025Automated web application testing is a critical component of modern software development, with frameworks like Selenium widely adopted for validating functionality through browser automation. Among the essential aspects of such testing is the ability to interact with and validate web forms, a task that requires syntactically correct, executable scripts with high coverage of input fields. Despite its importance, this task remains underexplored in the context of large language models (LLMs), and no public benchmark or dataset exists to evaluate LLMs on form interaction generation systematically. This paper introduces a novel method for training LLMs to generate high-quality test cases in Selenium, specifically targeting form interaction testing. We curate both synthetic and human-annotated datasets for training and evaluation, covering diverse real-world forms and testing scenarios. We define clear metrics for syntax correctness, script executability, and input field coverage. Our empirical study demonstrates that our approach significantly outperforms strong baselines, including GPT-4o and other popular LLMs, across all evaluation metrics. Our work lays the groundwork for future research on LLM-based web testing and provides resources to support ongoing progress in this area.
VLSP 2025 MLQA-TSR Challenge: Vietnamese Multimodal Legal Question Answering on Traffic Sign Regulation
Oct 23, 2025This paper presents the VLSP 2025 MLQA-TSR - the multimodal legal question answering on traffic sign regulation shared task at VLSP 2025. VLSP 2025 MLQA-TSR comprises two subtasks: multimodal legal retrieval and multimodal question answering. The goal is to advance research on Vietnamese multimodal legal text processing and to provide a benchmark dataset for building and evaluating intelligent systems in multimodal legal domains, with a focus on traffic sign regulation in Vietnam. The best-reported results on VLSP 2025 MLQA-TSR are an F2 score of 64.55% for multimodal legal retrieval and an accuracy of 86.30% for multimodal question answering.
NOWJ@COLIEE 2025: A Multi-stage Framework Integrating Embedding Models and Large Language Models for Legal Retrieval and Entailment
Sep 09, 2025This paper presents the methodologies and results of the NOWJ team's participation across all five tasks at the COLIEE 2025 competition, emphasizing advancements in the Legal Case Entailment task (Task 2). Our comprehensive approach systematically integrates pre-ranking models (BM25, BERT, monoT5), embedding-based semantic representations (BGE-m3, LLM2Vec), and advanced Large Language Models (Qwen-2, QwQ-32B, DeepSeek-V3) for summarization, relevance scoring, and contextual re-ranking. Specifically, in Task 2, our two-stage retrieval system combined lexical-semantic filtering with contextualized LLM analysis, achieving first place with an F1 score of 0.3195. Additionally, in other tasks--including Legal Case Retrieval, Statute Law Retrieval, Legal Textual Entailment, and Legal Judgment Prediction--we demonstrated robust performance through carefully engineered ensembles and effective prompt-based reasoning strategies. Our findings highlight the potential of hybrid models integrating traditional IR techniques with contemporary generative models, providing a valuable reference for future advancements in legal information processing.
Improving the Robustness of Representation Misdirection for Large Language Model Unlearning
Jan 31, 2025Representation Misdirection (RM) and variants are established large language model (LLM) unlearning methods with state-of-the-art performance. In this paper, we show that RM methods inherently reduce models' robustness, causing them to misbehave even when a single non-adversarial forget-token is in the retain-query. Toward understanding underlying causes, we reframe the unlearning process as backdoor attacks and defenses: forget-tokens act as backdoor triggers that, when activated in retain-queries, cause disruptions in RM models' behaviors, similar to successful backdoor attacks. To mitigate this vulnerability, we propose Random Noise Augmentation -- a model and method agnostic approach with theoretical guarantees for improving the robustness of RM methods. Extensive experiments demonstrate that RNA significantly improves the robustness of RM models while enhancing the unlearning performances.
ZeFaV: Boosting Large Language Models for Zero-shot Fact Verification
Nov 18, 2024In this paper, we propose ZeFaV - a zero-shot based fact-checking verification framework to enhance the performance on fact verification task of large language models by leveraging the in-context learning ability of large language models to extract the relations among the entities within a claim, re-organized the information from the evidence in a relationally logical form, and combine the above information with the original evidence to generate the context from which our fact-checking model provide verdicts for the input claims. We conducted empirical experiments to evaluate our approach on two multi-hop fact-checking datasets including HoVer and FEVEROUS, and achieved potential results results comparable to other state-of-the-art fact verification task methods.
A Mutual Inclusion Mechanism for Precise Boundary Segmentation in Medical Images
Apr 12, 2024In medical imaging, accurate image segmentation is crucial for quantifying diseases, assessing prognosis, and evaluating treatment outcomes. However, existing methods lack an in-depth integration of global and local features, failing to pay special attention to abnormal regions and boundary details in medical images. To this end, we present a novel deep learning-based approach, MIPC-Net, for precise boundary segmentation in medical images. Our approach, inspired by radiologists' working patterns, features two distinct modules: (i) \textbf{Mutual Inclusion of Position and Channel Attention (MIPC) module}: To enhance the precision of boundary segmentation in medical images, we introduce the MIPC module, which enhances the focus on channel information when extracting position features and vice versa; (ii) \textbf{GL-MIPC-Residue}: To improve the restoration of medical images, we propose the GL-MIPC-Residue, a global residual connection that enhances the integration of the encoder and decoder by filtering out invalid information and restoring the most effective information lost during the feature extraction process. We evaluate the performance of the proposed model using metrics such as Dice coefficient (DSC) and Hausdorff Distance (HD) on three publicly accessible datasets: Synapse, ISIC2018-Task, and Segpc. Our ablation study shows that each module contributes to improving the quality of segmentation results. Furthermore, with the assistance of both modules, our approach outperforms state-of-the-art methods across all metrics on the benchmark datasets, notably achieving a 2.23mm reduction in HD on the Synapse dataset, strongly evidencing our model's enhanced capability for precise image boundary segmentation. Codes will be available at https://github.com/SUN-1024/MIPC-Net.
VLSP 2023 -- LTER: A Summary of the Challenge on Legal Textual Entailment Recognition
Mar 06, 2024
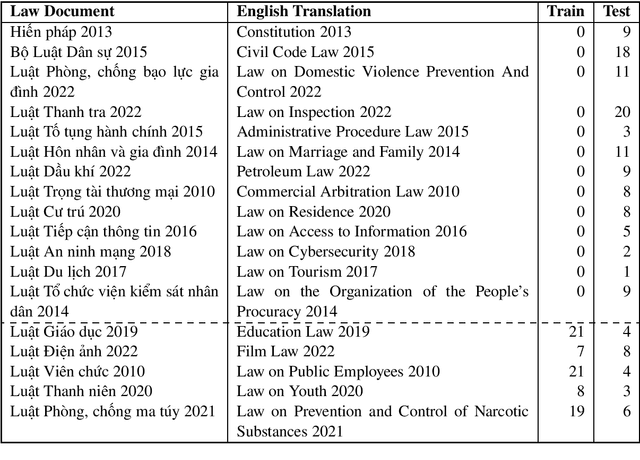


In this new era of rapid AI development, especially in language processing, the demand for AI in the legal domain is increasingly critical. In the context where research in other languages such as English, Japanese, and Chinese has been well-established, we introduce the first fundamental research for the Vietnamese language in the legal domain: legal textual entailment recognition through the Vietnamese Language and Speech Processing workshop. In analyzing participants' results, we discuss certain linguistic aspects critical in the legal domain that pose challenges that need to be addressed.
Employing Label Models on ChatGPT Answers Improves Legal Text Entailment Performance
Jan 31, 2024The objective of legal text entailment is to ascertain whether the assertions in a legal query logically follow from the information provided in one or multiple legal articles. ChatGPT, a large language model, is robust in many natural language processing tasks, including legal text entailment: when we set the temperature = 0 (the ChatGPT answers are deterministic) and prompt the model, it achieves 70.64% accuracy on COLIEE 2022 dataset, which outperforms the previous SOTA of 67.89%. On the other hand, if the temperature is larger than zero, ChatGPT answers are not deterministic, leading to inconsistent answers and fluctuating results. We propose to leverage label models (a fundamental component of weak supervision techniques) to integrate the provisional answers by ChatGPT into consolidated labels. By that way, we treat ChatGPT provisional answers as noisy predictions which can be consolidated by label models. The experimental results demonstrate that this approach can attain an accuracy of 76.15%, marking a significant improvement of 8.26% over the prior state-of-the-art benchmark. Additionally, we perform an analysis of the instances where ChatGPT produces incorrect answers, then we classify the errors, offering insights that could guide potential enhancements for future research endeavors.