 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Approaches for Legal Text Processing
Feb 13, 2022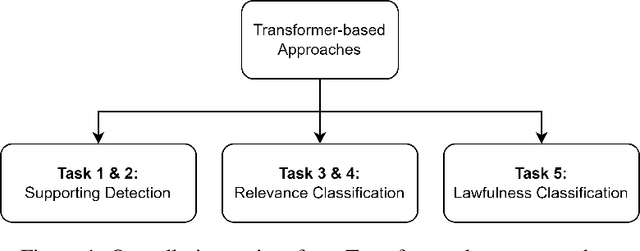

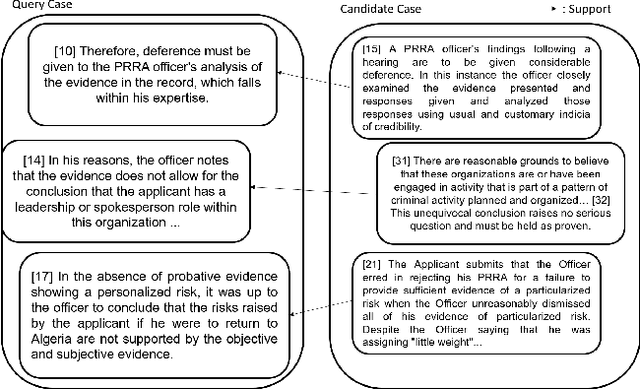
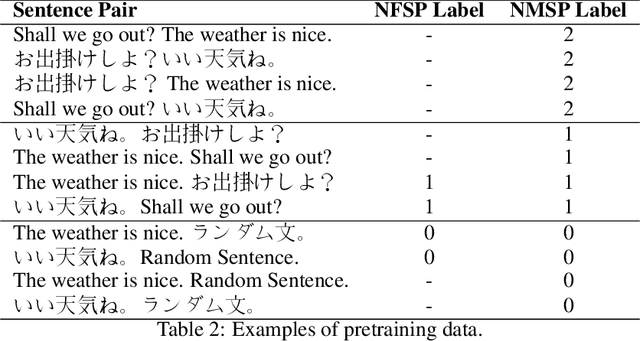
In this paper, we introduce our approaches using Transformer-based models for different problems of the COLIEE 2021 automatic legal text processing competition. Automated processing of legal documents is a challenging task because of the characteristics of legal documents as well as the limitation of the amount of data. With our detailed experiments, we found that Transformer-based pretrained language models can perform well with automated legal text processing problems with appropriate approaches. We describe in detail the processing steps for each task such as problem formulation, data processing and augmentation, pretraining, finetuning. In addition, we introduce to the community two pretrained models that take advantage of parallel translations in legal domain, NFSP and NMSP. In which, NFSP achieves the state-of-the-art result in Task 5 of the competition. Although the paper focuses on technical reporting, the novelty of its approaches can also be an useful reference in automated legal document processing using Transformer-based models.
HYDRA -- Hyper Dependency Representation Attentions
Sep 11, 2021
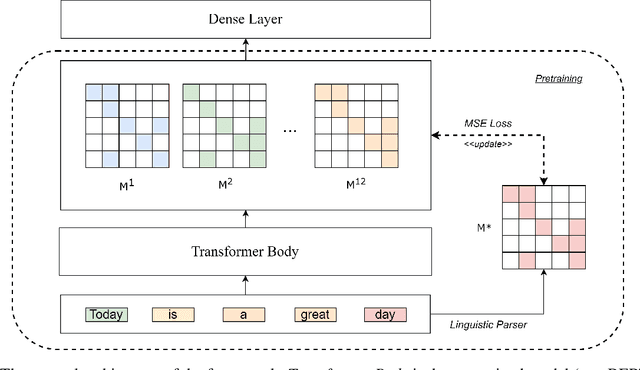
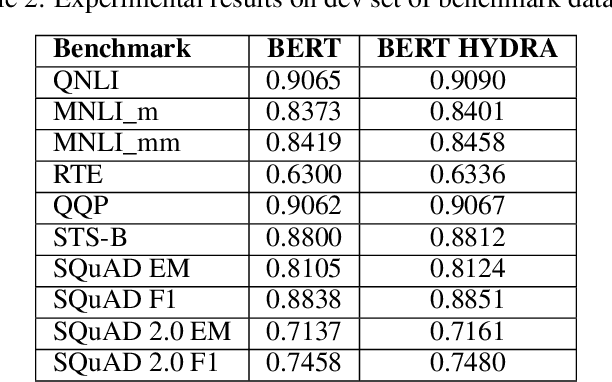
Attention is all we need as long as we have enough data. Even so, it is sometimes not easy to determine how much data is enough while the models are becoming larger and larger. In this paper, we propose HYDRA heads, lightweight pretrained linguistic self-attention heads to inject knowledge into transformer models without pretraining them again. Our approach is a balanced paradigm between leaving the models to learn unsupervised and forcing them to conform to linguistic knowledge rigidly as suggested in previous studies. Our experiment proves that the approach is not only the boost performance of the model but also lightweight and architecture friendly. We empirically verify our framework on benchmark datasets to show the contribution of linguistic knowledge to a transformer model. This is a promising result for a new approach to transferring knowledge from linguistic resources into transformer-based models.