 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Digital Twins of Different Human Organs for Personalized Healthcare
Jan 16, 2026Digital twins are virtual replicas of physical entities and are poised to transform personalized medicine through the real-time simulation and prediction of human physiology. Translating this paradigm from engineering to biomedicine requires overcoming profound challenges, including anatomical variability, multi-scale biological processes, and the integration of multi-physics phenomena. This survey systematically reviews methodologies for building digital twins of human organs, structured around a pipeline decoupled into anatomical twinning (capturing patient-specific geometry and structure) and functional twinning (simulating multi-scale physiology from cellular to organ-level function). We categorize approaches both by organ-specific properties and by technical paradigm, with particular emphasis on multi-scale and multi-physics integration. A key focus is the role of artificial intelligence (AI), especially physics-informed AI, in enhancing model fidelity, scalability, and personalization. Furthermore, we discuss the critical challenges of clinical validation and translational pathways. This study not only charts a roadmap for overcoming current bottlenecks in single-organ twins but also outlines the promising, albeit ambitious, future of interconnected multi-organ digital twins for whole-body precision healthcare.
VLSP 2025 MLQA-TSR Challenge: Vietnamese Multimodal Legal Question Answering on Traffic Sign Regulation
Oct 23, 2025This paper presents the VLSP 2025 MLQA-TSR - the multimodal legal question answering on traffic sign regulation shared task at VLSP 2025. VLSP 2025 MLQA-TSR comprises two subtasks: multimodal legal retrieval and multimodal question answering. The goal is to advance research on Vietnamese multimodal legal text processing and to provide a benchmark dataset for building and evaluating intelligent systems in multimodal legal domains, with a focus on traffic sign regulation in Vietnam. The best-reported results on VLSP 2025 MLQA-TSR are an F2 score of 64.55% for multimodal legal retrieval and an accuracy of 86.30% for multimodal question answering.
VLSP 2023 -- LTER: A Summary of the Challenge on Legal Textual Entailment Recognition
Mar 06, 2024
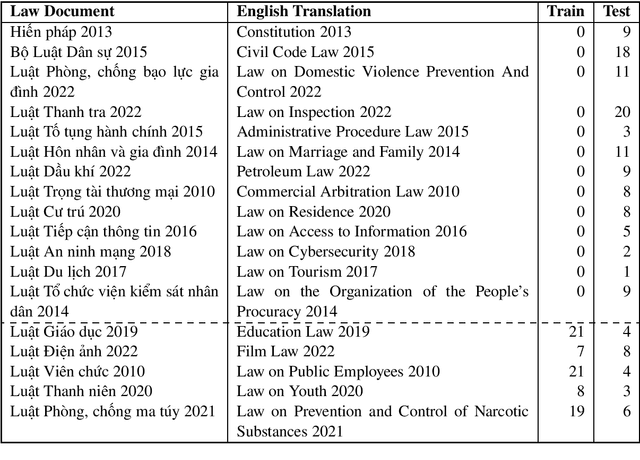


In this new era of rapid AI development, especially in language processing, the demand for AI in the legal domain is increasingly critical. In the context where research in other languages such as English, Japanese, and Chinese has been well-established, we introduce the first fundamental research for the Vietnamese language in the legal domain: legal textual entailment recognition through the Vietnamese Language and Speech Processing workshop. In analyzing participants' results, we discuss certain linguistic aspects critical in the legal domain that pose challenges that need to be addressed.
Encoded Summarization: Summarizing Documents into Continuous Vector Space for Legal Case Retrieval
Sep 15, 2023We present our method for tackling a legal case retrieval task by introducing our method of encoding documents by summarizing them into continuous vector space via our phrase scoring framework utilizing deep neural networks. On the other hand, we explore the benefits from combining lexical features and latent features generated with neural networks. Our experiments show that lexical features and latent features generated with neural networks complement each other to improve the retrieval system performance. Furthermore, our experimental results suggest the importance of case summarization in different aspects: using provided summaries and performing encoded summarization. Our approach achieved F1 of 65.6% and 57.6% on the experimental datasets of legal case retrieval tasks.
Law to Binary Tree -- An Formal Interpretation of Legal Natural Language
Dec 16, 2022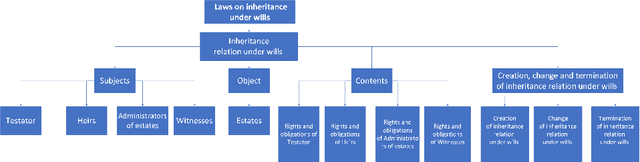
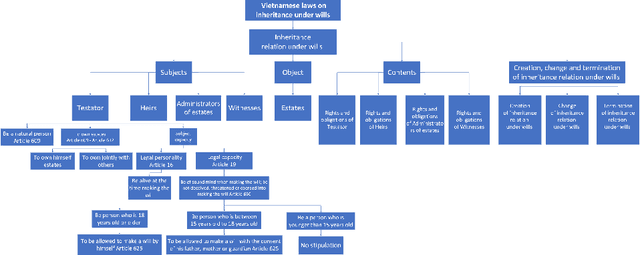
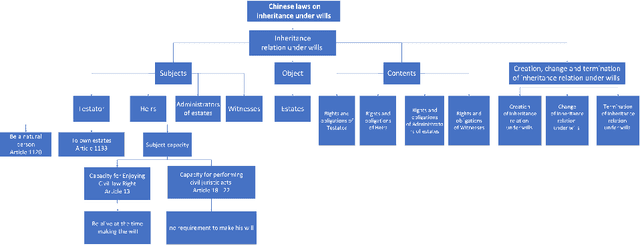
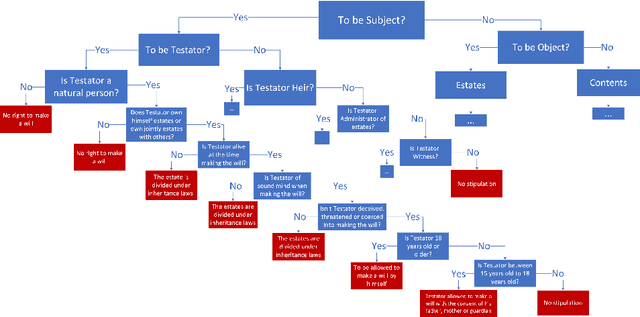
Knowledge representation and reasoning in law are essential to facilitate the automation of legal analysis and decision-making tasks. In this paper, we propose a new approach based on legal science, specifically legal taxonomy, for representing and reasoning with legal documents. Our approach interprets the regulations in legal documents as binary trees, which facilitates legal reasoning systems to make decisions and resolve logical contradictions. The advantages of this approach are twofold. First, legal reasoning can be performed on the basis of the binary tree representation of the regulations. Second, the binary tree representation of the regulations is more understandable than the existing sentence-based representations. We provide an example of how our approach can be used to interpret the regulations in a legal document.
Transformer-based Approaches for Legal Text Processing
Feb 13, 2022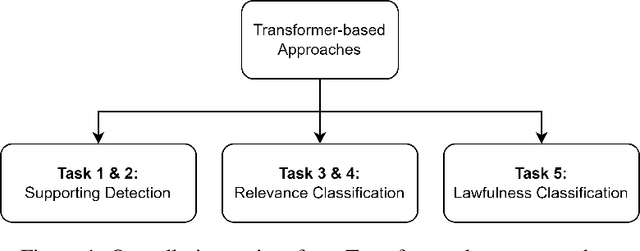

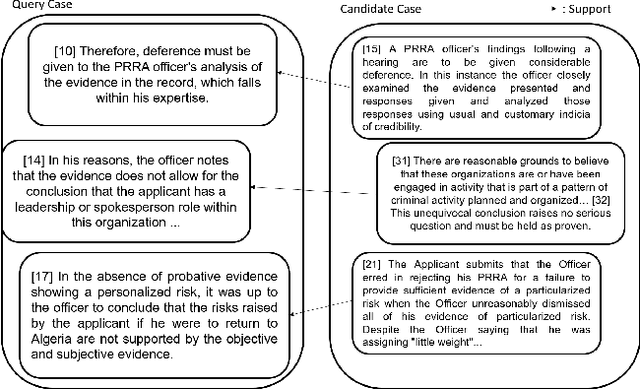
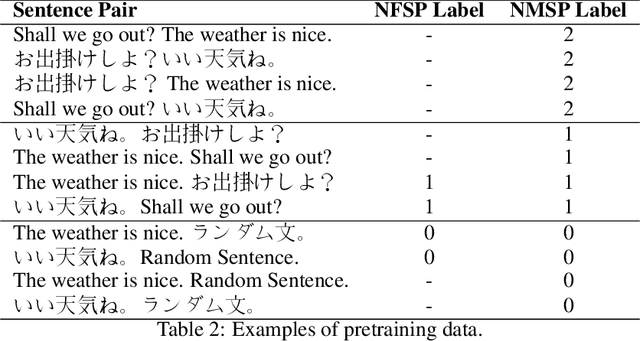
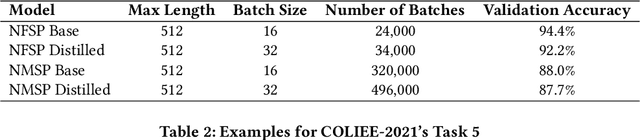
In this paper, we introduce our approaches using Transformer-based models for different problems of the COLIEE 2021 automatic legal text processing competition. Automated processing of legal documents is a challenging task because of the characteristics of legal documents as well as the limitation of the amount of data. With our detailed experiments, we found that Transformer-based pretrained language models can perform well with automated legal text processing problems with appropriate approaches. We describe in detail the processing steps for each task such as problem formulation, data processing and augmentation, pretraining, finetuning. In addition, we introduce to the community two pretrained models that take advantage of parallel translations in legal domain, NFSP and NMSP. In which, NFSP achieves the state-of-the-art result in Task 5 of the competition. Although the paper focuses on technical reporting, the novelty of its approaches can also be an useful reference in automated legal document processing using Transformer-based models.
HYDRA -- Hyper Dependency Representation Attentions
Sep 11, 2021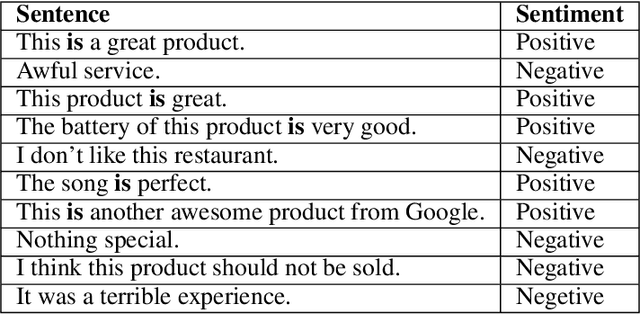
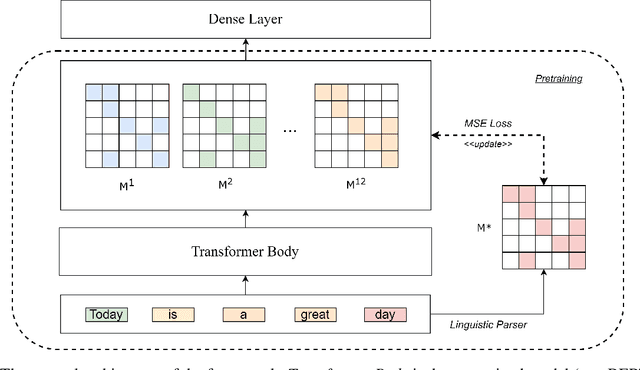
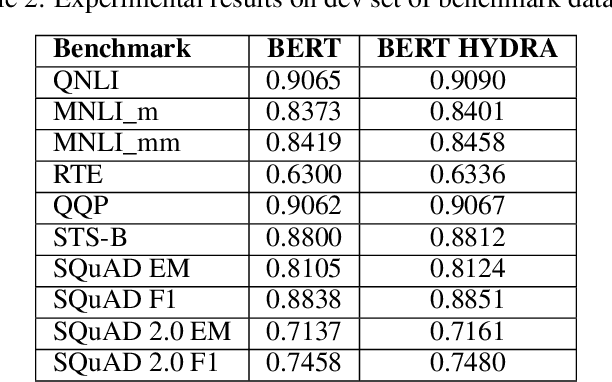
Attention is all we need as long as we have enough data. Even so, it is sometimes not easy to determine how much data is enough while the models are becoming larger and larger. In this paper, we propose HYDRA heads, lightweight pretrained linguistic self-attention heads to inject knowledge into transformer models without pretraining them again. Our approach is a balanced paradigm between leaving the models to learn unsupervised and forcing them to conform to linguistic knowledge rigidly as suggested in previous studies. Our experiment proves that the approach is not only the boost performance of the model but also lightweight and architecture friendly. We empirically verify our framework on benchmark datasets to show the contribution of linguistic knowledge to a transformer model. This is a promising result for a new approach to transferring knowledge from linguistic resources into transformer-based models.
JNLP Team: Deep Learning Approaches for Legal Processing Tasks in COLIEE 2021
Jun 25, 2021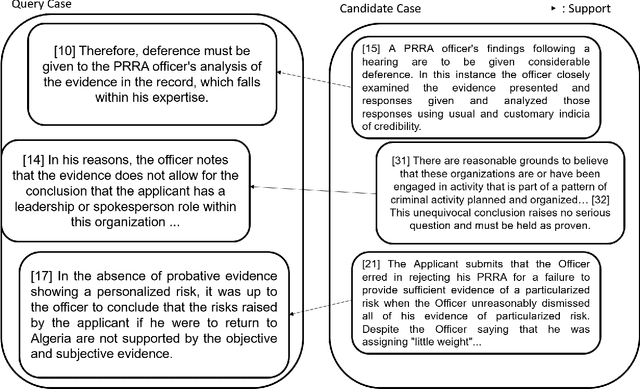



COLIEE is an annual competition in automatic computerized legal text processing. Automatic legal document processing is an ambitious goal, and the structure and semantics of the law are often far more complex than everyday language. In this article, we survey and report our methods and experimental results in using deep learning in legal document processing. The results show the difficulties as well as potentials in this family of approaches.
ParaLaw Nets -- Cross-lingual Sentence-level Pretraining for Legal Text Processing
Jun 25, 2021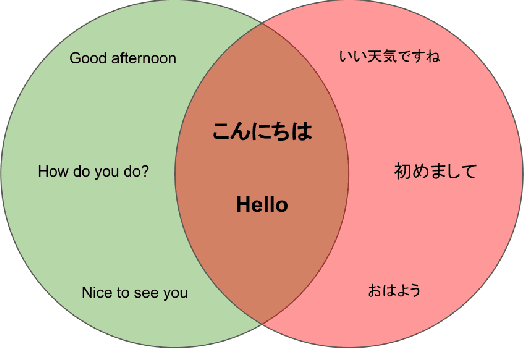


Ambiguity is a characteristic of natural language, which makes expression ideas flexible. However, in a domain that requires accurate statements, it becomes a barrier. Specifically, a single word can have many meanings and multiple words can have the same meaning. When translating a text into a foreign language, the translator needs to determine the exact meaning of each element in the original sentence to produce the correct translation sentence. From that observation, in this paper, we propose ParaLaw Nets, a pretrained model family using sentence-level cross-lingual information to reduce ambiguity and increase the performance in legal text processing. This approach achieved the best result in the Question Answering task of COLIEE-2021.
DeepLight: Robust & Unobtrusive Real-time Screen-Camera Communication for Real-World Displays
May 11, 2021
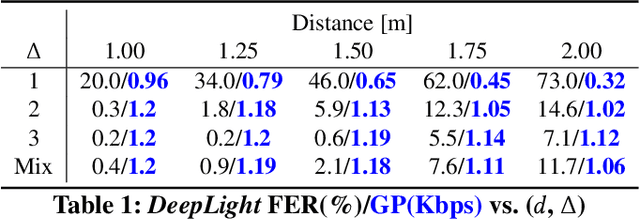

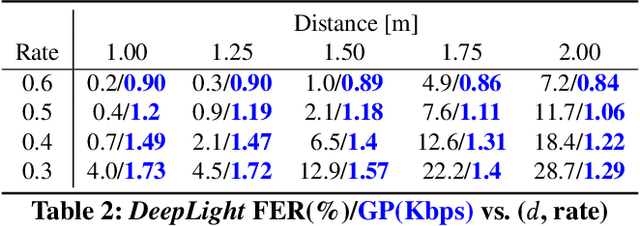
The paper introduces a novel, holistic approach for robust Screen-Camera Communication (SCC), where video content on a screen is visually encoded in a human-imperceptible fashion and decoded by a camera capturing images of such screen content. We first show that state-of-the-art SCC techniques have two key limitations for in-the-wild deployment: (a) the decoding accuracy drops rapidly under even modest screen extraction errors from the captured images, and (b) they generate perceptible flickers on common refresh rate screens even with minimal modulation of pixel intensity. To overcome these challenges, we introduce DeepLight, a system that incorporates machine learning (ML) models in the decoding pipeline to achieve humanly-imperceptible, moderately high SCC rates under diverse real-world conditions. Deep-Light's key innovation is the design of a Deep Neural Network (DNN) based decoder that collectively decodes all the bits spatially encoded in a display frame, without attempting to precisely isolate the pixels associated with each encoded bit. In addition, DeepLight supports imperceptible encoding by selectively modulating the intensity of only the Blue channel, and provides reasonably accurate screen extraction (IoU values >= 83%) by using state-of-the-art object detection DNN pipelines. We show that a fully functional DeepLight system is able to robustly achieve high decoding accuracy (frame error rate < 0.2) and moderately-high data goodput (>=0.95Kbps) using a human-held smartphone camera, even over larger screen-camera distances (approx =2m).