 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLSP 2023 -- LTER: A Summary of the Challenge on Legal Textual Entailment Recognition
Mar 06, 2024
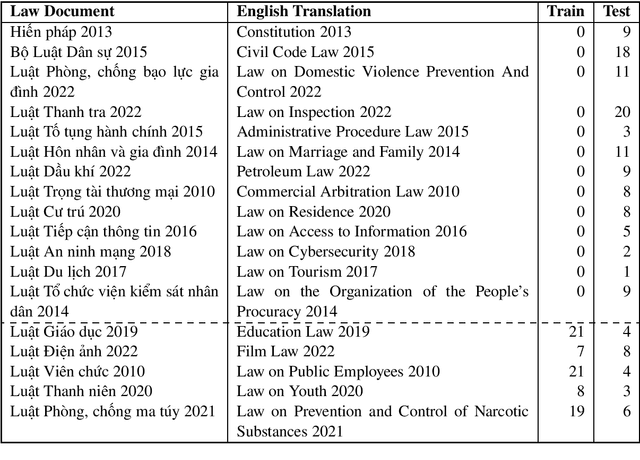


In this new era of rapid AI development, especially in language processing, the demand for AI in the legal domain is increasingly critical. In the context where research in other languages such as English, Japanese, and Chinese has been well-established, we introduce the first fundamental research for the Vietnamese language in the legal domain: legal textual entailment recognition through the Vietnamese Language and Speech Processing workshop. In analyzing participants' results, we discuss certain linguistic aspects critical in the legal domain that pose challenges that need to be addressed.
SPBERT: An Efficient Pre-training BERT on SPARQL Queries for Question Answering over Knowledge Graphs
Jun 30, 2021
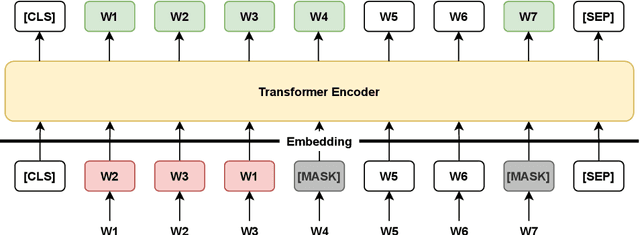
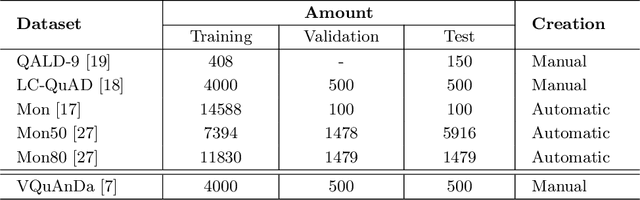
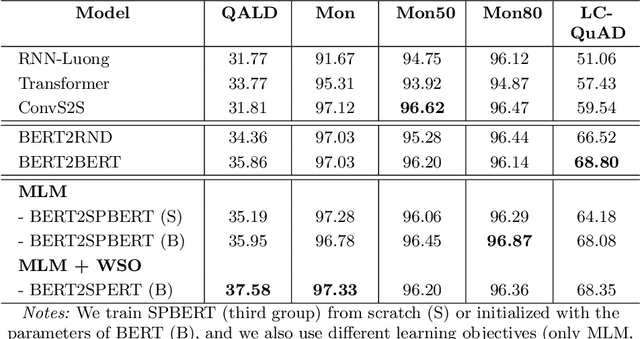
In this paper, we propose SPBERT, a transformer-based language model pre-trained on massive SPARQL query logs. By incorporating masked language modeling objectives and the word structural objective, SPBERT can learn general-purpose representations in both natural language and SPARQL query language. We investigate how SPBERT and encoder-decoder architecture can be adapted for Knowledge-based QA corpora. We conduct exhaustive experiments on two additional tasks, including SPARQL Query Construction and Answer Verbalization Generation. The experimental results show that SPBERT can obtain promising results, achieving state-of-the-art BLEU scores on several of these tasks.
Leveraging Transfer Learning for Reliable Intelligence Identification on Vietnamese SNSs (ReINTEL)
Dec 16, 2020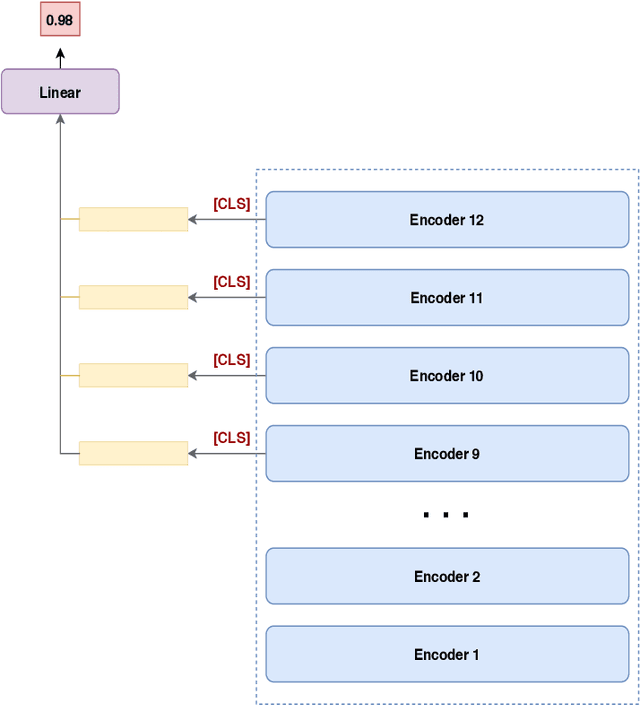
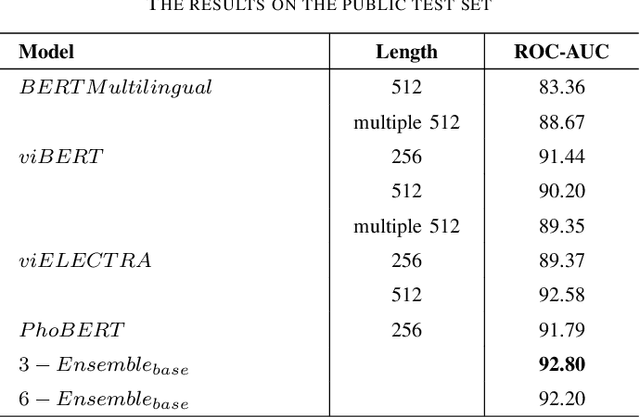
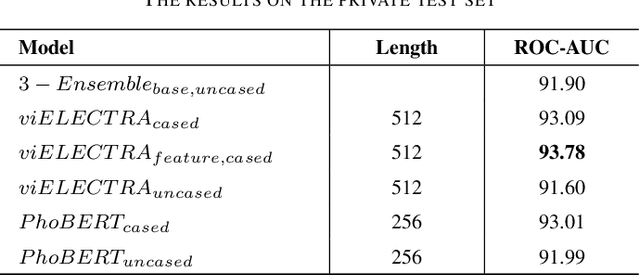
This paper proposed several transformer-based approaches for Reliable Intelligence Identification on Vietnamese social network sites at VLSP 2020 evaluation campaign. We exploit both of monolingual and multilingual pre-trained models. Besides, we utilize the ensemble method to improve the robustness of different approaches. Our team achieved a score of 0.9378 at ROC-AUC metric in the private test set which is competitive to other participants.