 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice EHR: Introducing Multimodal Audio Data for Health
Apr 02, 2024

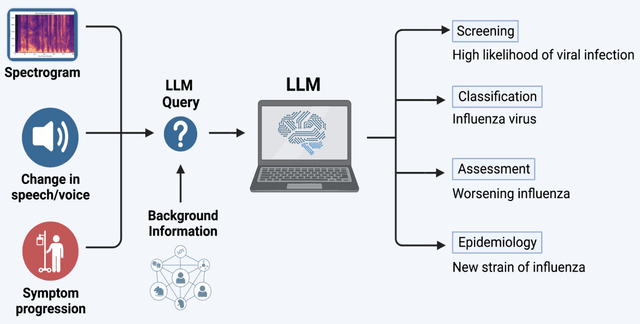
Large AI models trained on audio data may have the potential to rapidly classify patients, enhancing medical decision-making and potentially improving outcomes through early detection. Existing technologies depend on limited datasets using expensive recording equipment in high-income, English-speaking countries. This challenges deployment in resource-constrained, high-volume settings where audio data may have a profound impact. This report introduces a novel data type and a corresponding collection system that captures health data through guided questions using only a mobile/web application. This application ultimately results in an audio electronic health record (voice EHR) which may contain complex biomarkers of health from conventional voice/respiratory features, speech patterns, and language with semantic meaning - compensating for the typical limitations of unimodal clinical datasets. This report introduces a consortium of partners for global work, presents the application used for data collection, and showcases the potential of informative voice EHR to advance the scalability and diversity of audio AI.
Harnessing PubMed User Query Logs for Post Hoc Explanations of Recommended Similar Articles
Feb 05, 2024



Searching for a related article based on a reference article is an integral part of scientific research. PubMed, like many academic search engines, has a "similar articles" feature that recommends articles relevant to the current article viewed by a user. Explaining recommended items can be of great utility to users, particularly in the literature search process. With more than a million biomedical papers being published each year, explaining the recommended similar articles would facilitate researchers and clinicians in searching for related articles. Nonetheless, the majority of current literature recommendation systems lack explanations for their suggestions. We employ a post hoc approach to explaining recommendations by identifying relevant tokens in the titles of similar articles. Our major contribution is building PubCLogs by repurposing 5.6 million pairs of coclicked articles from PubMed's user query logs. Using our PubCLogs dataset, we train the Highlight Similar Article Title (HSAT), a transformer-based model designed to select the most relevant parts of the title of a similar article, based on the title and abstract of a seed article. HSAT demonstrates strong performance in our empirical evaluations, achieving an F1 score of 91.72 percent on the PubCLogs test set, considerably outperforming several baselines including BM25 (70.62), MPNet (67.11), MedCPT (62.22), GPT-3.5 (46.00), and GPT-4 (64.89). Additional evaluations on a separate, manually annotated test set further verifies HSAT's performance. Moreover, participants of our user study indicate a preference for HSAT, due to its superior balance between conciseness and comprehensiveness. Our study suggests that repurposing user query logs of academic search engines can be a promising way to train state-of-the-art models for explaining literature recommendation.
VieSum: How Robust Are Transformer-based Models on Vietnamese Summarization?
Oct 08, 2021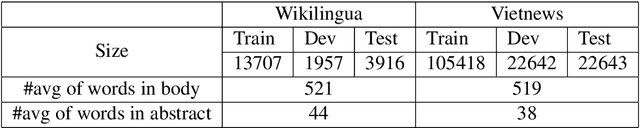

Text summarization is a challenging task within natural language processing that involves text generation from lengthy input sequences. While this task has been widely studied in English, there is very limited research on summarization for Vietnamese text. In this paper, we investigate the robustness of transformer-based encoder-decoder architectures for Vietnamese abstractive summarization. Leveraging transfer learning and self-supervised learning, we validate the performance of the methods on two Vietnamese datasets.
SPBERT: An Efficient Pre-training BERT on SPARQL Queries for Question Answering over Knowledge Graphs
Jun 30, 2021
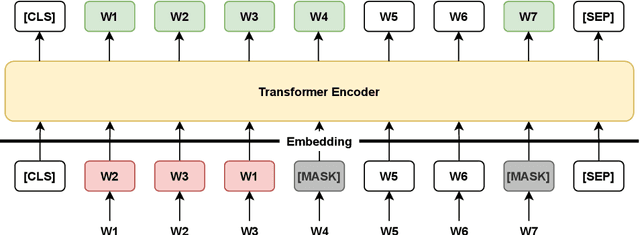
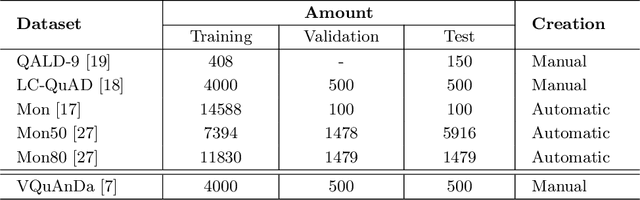
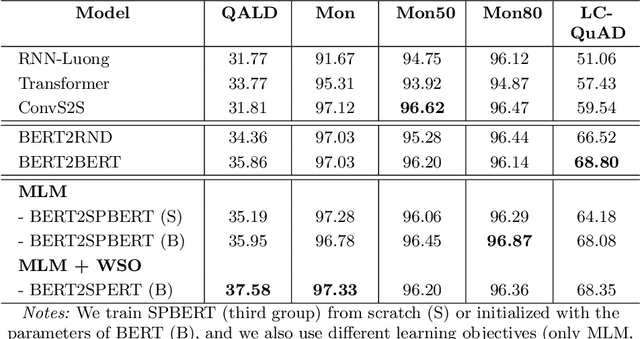
In this paper, we propose SPBERT, a transformer-based language model pre-trained on massive SPARQL query logs. By incorporating masked language modeling objectives and the word structural objective, SPBERT can learn general-purpose representations in both natural language and SPARQL query language. We investigate how SPBERT and encoder-decoder architecture can be adapted for Knowledge-based QA corpora. We conduct exhaustive experiments on two additional tasks, including SPARQL Query Construction and Answer Verbalization Generation. The experimental results show that SPBERT can obtain promising results, achieving state-of-the-art BLEU scores on several of these tasks.
CoTexT: Multi-task Learning with Code-Text Transformer
Jun 09, 2021

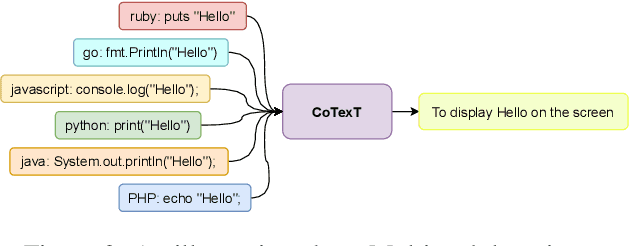
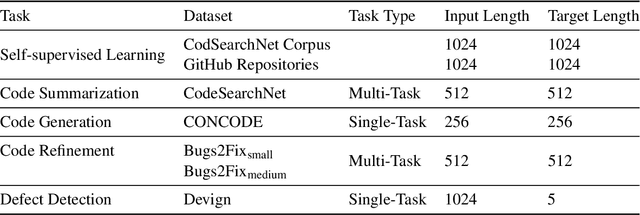
We present CoTexT, a pre-trained, transformer-based encoder-decoder model that learns the representative context between natural language (NL) and programming language (PL). Using self-supervision, CoTexT is pre-trained on large programming language corpora to learn a general understanding of language and code. CoTexT supports downstream NL-PL tasks such as code summarizing/documentation, code generation, defect detection, and code debugging. We train CoTexT on different combinations of available PL corpus including both "bimodal" and "unimodal" data. Here, bimodal data is the combination of text and corresponding code snippets, whereas unimodal data is merely code snippets. We first evaluate CoTexT with multi-task learning: we perform Code Summarization on 6 different programming languages and Code Refinement on both small and medium size featured in the CodeXGLUE dataset. We further conduct extensive experiments to investigate CoTexT on other tasks within the CodeXGlue dataset, including Code Generation and Defect Detection. We consistently achieve SOTA results in these tasks, demonstrating the versatility of our models.