 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVieSum: How Robust Are Transformer-based Models on Vietnamese Summarization?
Oct 08, 2021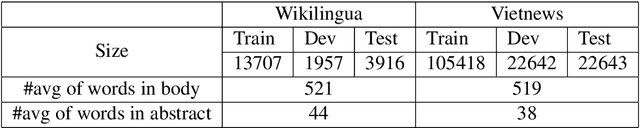

Text summarization is a challenging task within natural language processing that involves text generation from lengthy input sequences. While this task has been widely studied in English, there is very limited research on summarization for Vietnamese text. In this paper, we investigate the robustness of transformer-based encoder-decoder architectures for Vietnamese abstractive summarization. Leveraging transfer learning and self-supervised learning, we validate the performance of the methods on two Vietnamese datasets.
CoTexT: Multi-task Learning with Code-Text Transformer
Jun 09, 2021

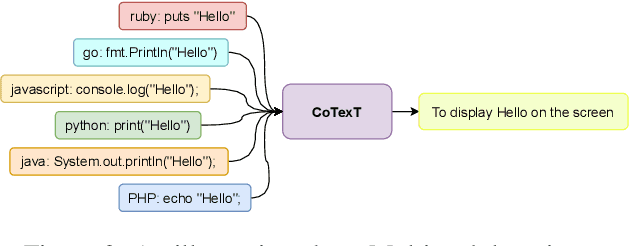
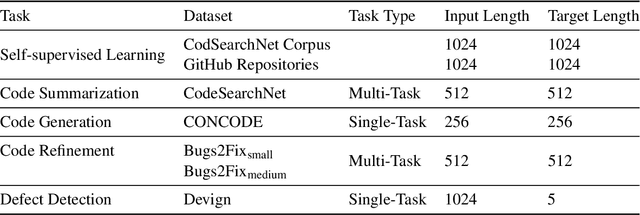
We present CoTexT, a pre-trained, transformer-based encoder-decoder model that learns the representative context between natural language (NL) and programming language (PL). Using self-supervision, CoTexT is pre-trained on large programming language corpora to learn a general understanding of language and code. CoTexT supports downstream NL-PL tasks such as code summarizing/documentation, code generation, defect detection, and code debugging. We train CoTexT on different combinations of available PL corpus including both "bimodal" and "unimodal" data. Here, bimodal data is the combination of text and corresponding code snippets, whereas unimodal data is merely code snippets. We first evaluate CoTexT with multi-task learning: we perform Code Summarization on 6 different programming languages and Code Refinement on both small and medium size featured in the CodeXGLUE dataset. We further conduct extensive experiments to investigate CoTexT on other tasks within the CodeXGlue dataset, including Code Generation and Defect Detection. We consistently achieve SOTA results in these tasks, demonstrating the versatility of our models.
SciFive: a text-to-text transformer model for biomedical literature
May 28, 2021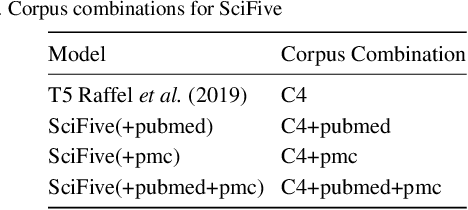
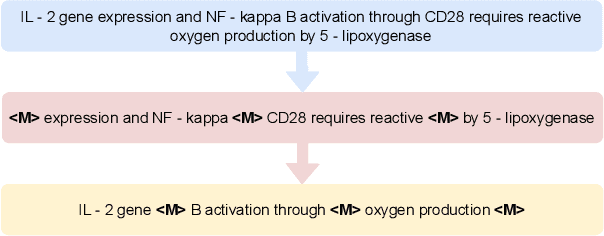
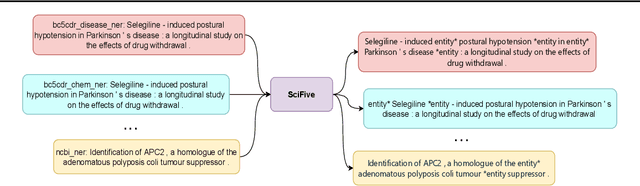
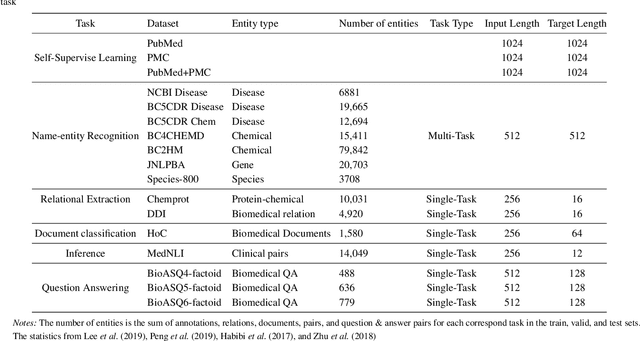
In this report, we introduce SciFive, a domain-specific T5 model that has been pre-trained on large biomedical corpora. Our model outperforms the current SOTA methods (i.e. BERT, BioBERT, Base T5) on tasks in named entity relation, relation extraction, natural language inference, and question-answering. We show that text-generation methods have significant potential in a broad array of biomedical NLP tasks, particularly those requiring longer, more complex outputs. Our results support the exploration of more difficult text generation tasks and the development of new methods in this area