 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience-Guided Adaptation of Inference-Time Reasoning Strategies
Nov 14, 2025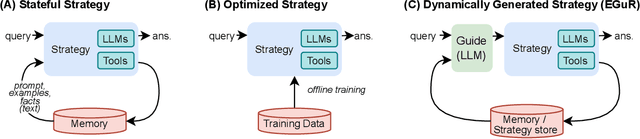
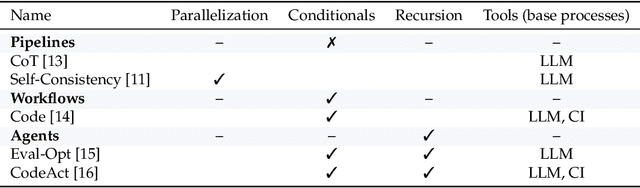

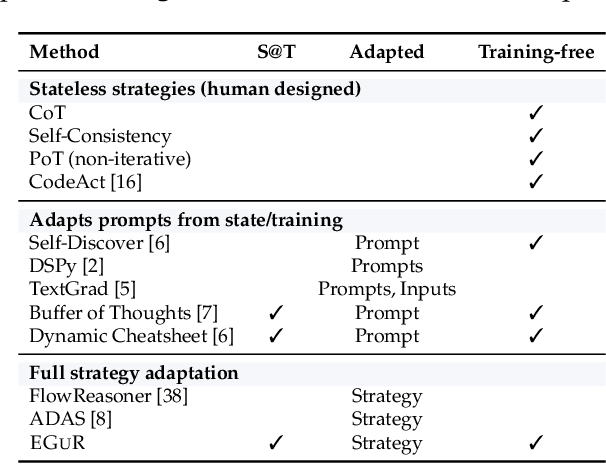
Enabling agentic AI systems to adapt their problem-solving approaches based on post-training interactions remains a fundamental challenge. While systems that update and maintain a memory at inference time have been proposed, existing designs only steer the system by modifying textual input to a language model or agent, which means that they cannot change sampling parameters, remove tools, modify system prompts, or switch between agentic and workflow paradigms. On the other hand, systems that adapt more flexibly require offline optimization and remain static once deployed. We present Experience-Guided Reasoner (EGuR), which generates tailored strategies -- complete computational procedures involving LLM calls, tools, sampling parameters, and control logic -- dynamically at inference time based on accumulated experience. We achieve this using an LLM-based meta-strategy -- a strategy that outputs strategies -- enabling adaptation of all strategy components (prompts, sampling parameters, tool configurations, and control logic). EGuR operates through two components: a Guide generates multiple candidate strategies conditioned on the current problem and structured memory of past experiences, while a Consolidator integrates execution feedback to improve future strategy generation. This produces complete, ready-to-run strategies optimized for each problem, which can be cached, retrieved, and executed as needed without wasting resources. Across five challenging benchmarks (AIME 2025, 3-SAT, and three Big Bench Extra Hard tasks), EGuR achieves up to 14% accuracy improvements over the strongest baselines while reducing computational costs by up to 111x, with both metrics improving as the system gains experience.
e1: Learning Adaptive Control of Reasoning Effort
Oct 30, 2025Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training.
Towards a theory of learning dynamics in deep state space models
Jul 10, 2024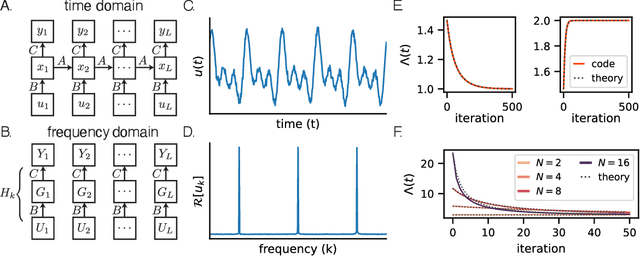
State space models (SSMs) have shown remarkable empirical performance on many long sequence modeling tasks, but a theoretical understanding of these models is still lacking. In this work, we study the learning dynamics of linear SSMs to understand how covariance structure in data, latent state size, and initialization affect the evolution of parameters throughout learning with gradient descent. We show that focusing on the learning dynamics in the frequency domain affords analytical solutions under mild assumptions, and we establish a link between one-dimensional SSMs and the dynamics of deep linear feed-forward networks. Finally, we analyze how latent state over-parameterization affects convergence time and describe future work in extending our results to the study of deep SSMs with nonlinear connections. This work is a step toward a theory of learning dynamics in deep state space models.
Voice EHR: Introducing Multimodal Audio Data for Health
Apr 02, 2024
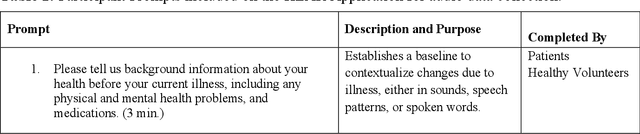

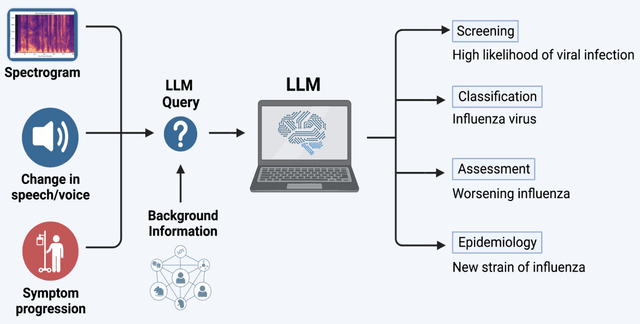
Large AI models trained on audio data may have the potential to rapidly classify patients, enhancing medical decision-making and potentially improving outcomes through early detection. Existing technologies depend on limited datasets using expensive recording equipment in high-income, English-speaking countries. This challenges deployment in resource-constrained, high-volume settings where audio data may have a profound impact. This report introduces a novel data type and a corresponding collection system that captures health data through guided questions using only a mobile/web application. This application ultimately results in an audio electronic health record (voice EHR) which may contain complex biomarkers of health from conventional voice/respiratory features, speech patterns, and language with semantic meaning - compensating for the typical limitations of unimodal clinical datasets. This report introduces a consortium of partners for global work, presents the application used for data collection, and showcases the potential of informative voice EHR to advance the scalability and diversity of audio AI.
Critical Learning Periods Emerge Even in Deep Linear Networks
Aug 23, 2023



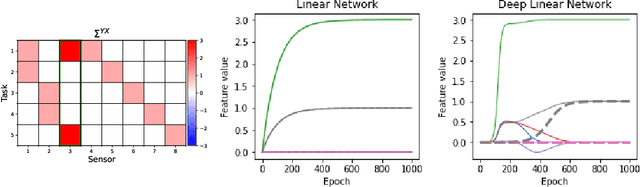
Critical learning periods are periods early in development where temporary sensory deficits can have a permanent effect on behavior and learned representations. Despite the radical differences between biological and artificial networks, critical learning periods have been empirically observed in both systems. This suggests that critical periods may be fundamental to learning and not an accident of biology. Yet, why exactly critical periods emerge in deep networks is still an open question, and in particular it is unclear whether the critical periods observed in both systems depend on particular architectural or optimization details. To isolate the key underlying factors, we focus on deep linear network models, and show that, surprisingly, such networks also display much of the behavior seen in biology and artificial networks, while being amenable to analytical treatment. We show that critical periods depend on the depth of the model and structure of the data distribution. We also show analytically and in simulations that the learning of features is tied to competition between sources. Finally, we extend our analysis to multi-task learning to show that pre-training on certain tasks can damage the transfer performance on new tasks, and show how this depends on the relationship between tasks and the duration of the pre-training stage. To the best of our knowledge, our work provides the first analytically tractable model that sheds light into why critical learning periods emerge in biological and artificial networks.
Critical Learning Periods for Multisensory Integration in Deep Networks
Oct 06, 2022
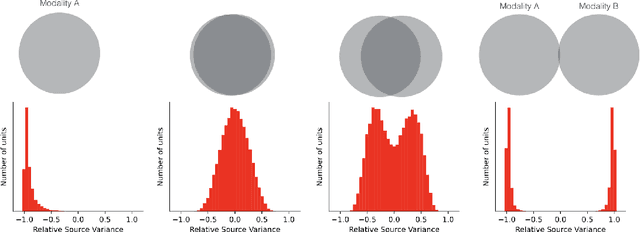
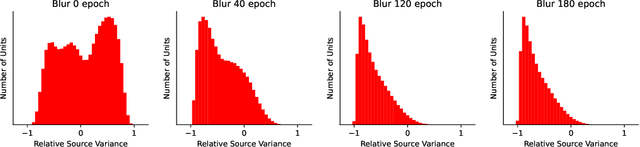
We show that the ability of a neural network to integrate information from diverse sources hinges critically on being exposed to properly correlated signals during the early phases of training. Interfering with the learning process during this initial stage can permanently impair the development of a skill, both in artificial and biological systems where the phenomenon is known as critical learning period. We show that critical periods arise from the complex and unstable early transient dynamics, which are decisive of final performance of the trained system and their learned representations. This evidence challenges the view, engendered by analysis of wide and shallow networks, that early learning dynamics of neural networks are simple, akin to those of a linear model. Indeed, we show that even deep linear networks exhibit critical learning periods for multi-source integration, while shallow networks do not. To better understand how the internal representations change according to disturbances or sensory deficits, we introduce a new measure of source sensitivity, which allows us to track the inhibition and integration of sources during training. Our analysis of inhibition suggests cross-source reconstruction as a natural auxiliary training objective, and indeed we show that architectures trained with cross-sensor reconstruction objectives are remarkably more resilient to critical periods. Our findings suggest that the recent success in self-supervised multi-modal training compared to previous supervised efforts may be in part due to more robust learning dynamics and not solely due to better architectures and/or more data.
Gacs-Korner Common Information Variational Autoencoder
May 24, 2022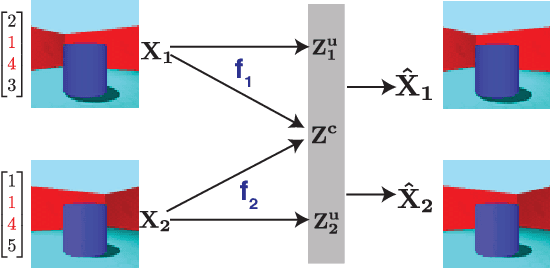

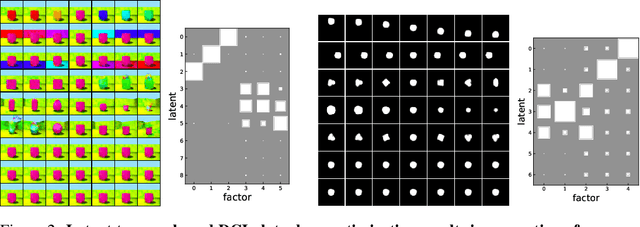

We propose a notion of common information that allows one to quantify and separate the information that is shared between two random variables from the information that is unique to each. Our notion of common information is a variational relaxation of the G\'acs-K\"orner common information, which we recover as a special case, but is more amenable to optimization and can be approximated empirically using samples from the underlying distribution. We then provide a method to partition and quantify the common and unique information using a simple modification of a traditional variational auto-encoder. Empirically, we demonstrate that our formulation allows us to learn semantically meaningful common and unique factors of variation even on high-dimensional data such as images and videos. Moreover, on datasets where ground-truth latent factors are known, we show that we can accurately quantify the common information between the random variables. Additionally, we show that the auto-encoder that we learn recovers semantically meaningful disentangled factors of variation, even though we do not explicitly optimize for it.
Usable Information and Evolution of Optimal Representations During Training
Oct 06, 2020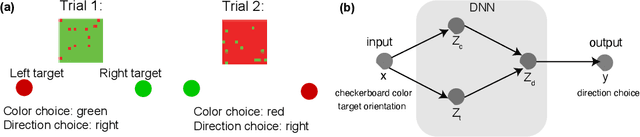
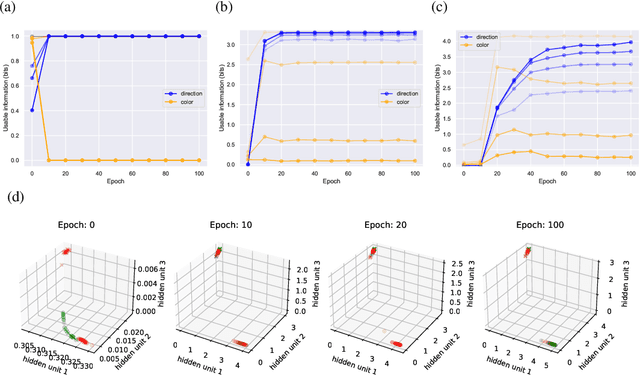
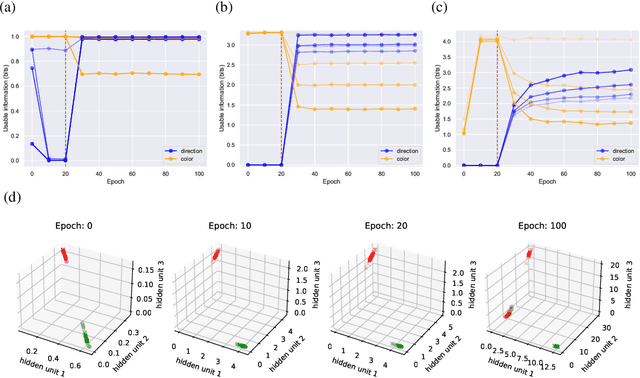
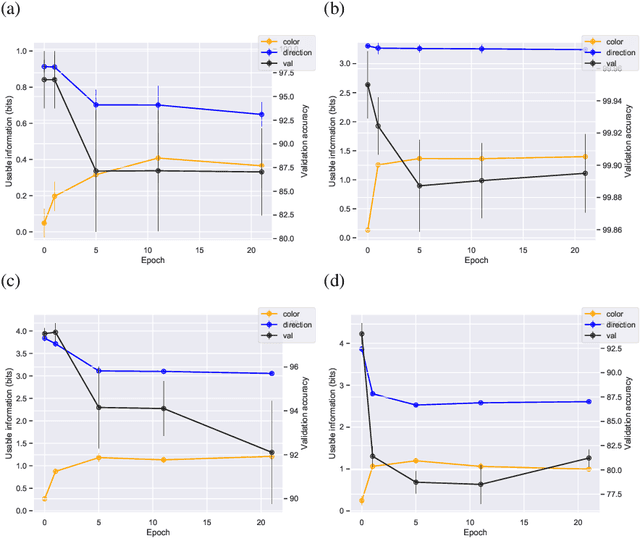
We introduce a notion of usable information contained in the representation learned by a deep network, and use it to study how optimal representations for the task emerge during training, and how they adapt to different tasks. We use this to characterize the transient dynamics of deep neural networks on perceptual decision-making tasks inspired by neuroscience literature. In particular, we show that both the random initialization and the implicit regularization from Stochastic Gradient Descent play an important role in learning minimal sufficient representations for the task. If the network is not randomly initialized, we show that the training may not recover an optimal representation, increasing the chance of overfitting.