 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITSELF: Attention Guided Fine-Grained Alignment for Vision-Language Retrieval
Jan 03, 2026Vision Language Models (VLMs) have rapidly advanced and show strong promise for text-based person search (TBPS), a task that requires capturing fine-grained relationships between images and text to distinguish individuals. Previous methods address these challenges through local alignment, yet they are often prone to shortcut learning and spurious correlations, yielding misalignment. Moreover, injecting prior knowledge can distort intra-modality structure. Motivated by our finding that encoder attention surfaces spatially precise evidence from the earliest training epochs, and to alleviate these issues, we introduceITSELF, an attention-guided framework for implicit local alignment. At its core, Guided Representation with Attentive Bank (GRAB) converts the model's own attention into an Attentive Bank of high-saliency tokens and applies local objectives on this bank, learning fine-grained correspondences without extra supervision. To make the selection reliable and non-redundant, we introduce Multi-Layer Attention for Robust Selection (MARS), which aggregates attention across layers and performs diversity-aware top-k selection; and Adaptive Token Scheduler (ATS), which schedules the retention budget from coarse to fine over training, preserving context early while progressively focusing on discriminative details. Extensive experiments on three widely used TBPS benchmarks showstate-of-the-art performance and strong cross-dataset generalization, confirming the effectiveness and robustness of our approach without additional prior supervision. Our project is publicly available at https://trhuuloc.github.io/itself
MADTempo: An Interactive System for Multi-Event Temporal Video Retrieval with Query Augmentation
Dec 15, 2025



The rapid expansion of video content across online platforms has accelerated the need for retrieval systems capable of understanding not only isolated visual moments but also the temporal structure of complex events. Existing approaches often fall short in modeling temporal dependencies across multiple events and in handling queries that reference unseen or rare visual concepts. To address these challenges, we introduce MADTempo, a video retrieval framework developed by our team, AIO_Trinh, that unifies temporal search with web-scale visual grounding. Our temporal search mechanism captures event-level continuity by aggregating similarity scores across sequential video segments, enabling coherent retrieval of multi-event queries. Complementarily, a Google Image Search-based fallback module expands query representations with external web imagery, effectively bridging gaps in pretrained visual embeddings and improving robustness against out-of-distribution (OOD) queries. Together, these components advance the temporal reasoning and generalization capabilities of modern video retrieval systems, paving the way for more semantically aware and adaptive retrieval across large-scale video corpora.
HDC: Hierarchical Distillation for Multi-level Noisy Consistency in Semi-Supervised Fetal Ultrasound Segmentation
Apr 14, 2025Transvaginal ultrasound is a critical imaging modality for evaluating cervical anatomy and detecting physiological changes. However, accurate segmentation of cervical structures remains challenging due to low contrast, shadow artifacts, and fuzzy boundaries. While convolutional neural networks (CNNs) have shown promising results in medical image segmentation, their performance is often limited by the need for large-scale annotated datasets - an impractical requirement in clinical ultrasound imaging. Semi-supervised learning (SSL) offers a compelling solution by leveraging unlabeled data, but existing teacher-student frameworks often suffer from confirmation bias and high computational costs. We propose HDC, a novel semi-supervised segmentation framework that integrates Hierarchical Distillation and Consistency learning within a multi-level noise mean-teacher framework. Unlike conventional approaches that rely solely on pseudo-labeling, we introduce a hierarchical distillation mechanism that guides feature-level learning via two novel objectives: (1) Correlation Guidance Loss to align feature representations between the teacher and main student branch, and (2) Mutual Information Loss to stabilize representations between the main and noisy student branches. Our framework reduces model complexity while improving generalization. Extensive experiments on two fetal ultrasound datasets, FUGC and PSFH, demonstrate that our method achieves competitive performance with significantly lower computational overhead than existing multi-teacher models.
IGL-DT: Iterative Global-Local Feature Learning with Dual-Teacher Semantic Segmentation Framework under Limited Annotation Scheme
Apr 14, 2025



Semi-Supervised Semantic Segmentation (SSSS) aims to improve segmentation accuracy by leveraging a small set of labeled images alongside a larger pool of unlabeled data. Recent advances primarily focus on pseudo-labeling, consistency regularization, and co-training strategies. However, existing methods struggle to balance global semantic representation with fine-grained local feature extraction. To address this challenge, we propose a novel tri-branch semi-supervised segmentation framework incorporating a dual-teacher strategy, named IGL-DT. Our approach employs SwinUnet for high-level semantic guidance through Global Context Learning and ResUnet for detailed feature refinement via Local Regional Learning. Additionally, a Discrepancy Learning mechanism mitigates over-reliance on a single teacher, promoting adaptive feature learning. Extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches, achieving superior segmentation performance across various data regimes.
Cycle Training with Semi-Supervised Domain Adaptation: Bridging Accuracy and Efficiency for Real-Time Mobile Scene Detection
Apr 12, 2025Nowadays, smartphones are ubiquitous, and almost everyone owns one. At the same time, the rapid development of AI has spurred extensive research on applying deep learning techniques to image classification. However, due to the limited resources available on mobile devices, significant challenges remain in balancing accuracy with computational efficiency. In this paper, we propose a novel training framework called Cycle Training, which adopts a three-stage training process that alternates between exploration and stabilization phases to optimize model performance. Additionally, we incorporate Semi-Supervised Domain Adaptation (SSDA) to leverage the power of large models and unlabeled data, thereby effectively expanding the training dataset. Comprehensive experiments on the CamSSD dataset for mobile scene detection demonstrate that our framework not only significantly improves classification accuracy but also ensures real-time inference efficiency. Specifically, our method achieves a 94.00% in Top-1 accuracy and a 99.17% in Top-3 accuracy and runs inference in just 1.61ms using CPU, demonstrating its suitability for real-world mobile deployment.
A Lightweight Moment Retrieval System with Global Re-Ranking and Robust Adaptive Bidirectional Temporal Search
Apr 12, 2025



The exponential growth of digital video content has posed critical challenges in moment-level video retrieval, where existing methodologies struggle to efficiently localize specific segments within an expansive video corpus. Current retrieval systems are constrained by computational inefficiencies, temporal context limitations, and the intrinsic complexity of navigating video content. In this paper, we address these limitations through a novel Interactive Video Corpus Moment Retrieval framework that integrates a SuperGlobal Reranking mechanism and Adaptive Bidirectional Temporal Search (ABTS), strategically optimizing query similarity, temporal stability, and computational resources. By preprocessing a large corpus of videos using a keyframe extraction model and deduplication technique through image hashing, our approach provides a scalable solution that significantly reduces storage requirements while maintaining high localization precision across diverse video repositories.
Towards Efficient and Robust Moment Retrieval System: A Unified Framework for Multi-Granularity Models and Temporal Reranking
Apr 11, 2025Long-form video understanding presents significant challenges for interactive retrieval systems, as conventional methods struggle to process extensive video content efficiently. Existing approaches often rely on single models, inefficient storage, unstable temporal search, and context-agnostic reranking, limiting their effectiveness. This paper presents a novel framework to enhance interactive video retrieval through four key innovations: (1) an ensemble search strategy that integrates coarse-grained (CLIP) and fine-grained (BEIT3) models to improve retrieval accuracy, (2) a storage optimization technique that reduces redundancy by selecting representative keyframes via TransNetV2 and deduplication, (3) a temporal search mechanism that localizes video segments using dual queries for start and end points, and (4) a temporal reranking approach that leverages neighboring frame context to stabilize rankings. Evaluated on known-item search and question-answering tasks, our framework demonstrates substantial improvements in retrieval precision, efficiency, and user interpretability, offering a robust solution for real-world interactive video retrieval applications.
Improving Generalization in Visual Reasoning via Self-Ensemble
Oct 28, 2024



The cognitive faculty of visual reasoning necessitates the integration of multimodal perceptual processing and commonsense and external knowledge of the world. In recent years, a plethora of large vision-language models (LVLMs) have been proposed, demonstrating outstanding power and exceptional proficiency in commonsense reasoning across diverse domains and tasks. Nevertheless, training such LVLMs requires a lot of costly resources. Recent approaches, instead of training LVLMs from scratch on various large datasets, focus on exploring ways to take advantage of the capabilities of many different LVLMs, such as ensemble methods. In this work, we propose self-ensemble, a novel method that improves the generalization and visual reasoning of the model without updating any parameters, a training-free method. Our key insight is that we realized that LVLM itself can ensemble without the need for any other LVLMs, which helps to unlock their internal capabilities. Extensive experiments on various benchmarks demonstrate the effectiveness of our method in achieving state-of-the-art (SOTA) performance on SketchyVQA, Outside Knowledge VQA, and out-of-distribution VQA tasks.
Leveraging Transfer Learning for Reliable Intelligence Identification on Vietnamese SNSs (ReINTEL)
Dec 16, 2020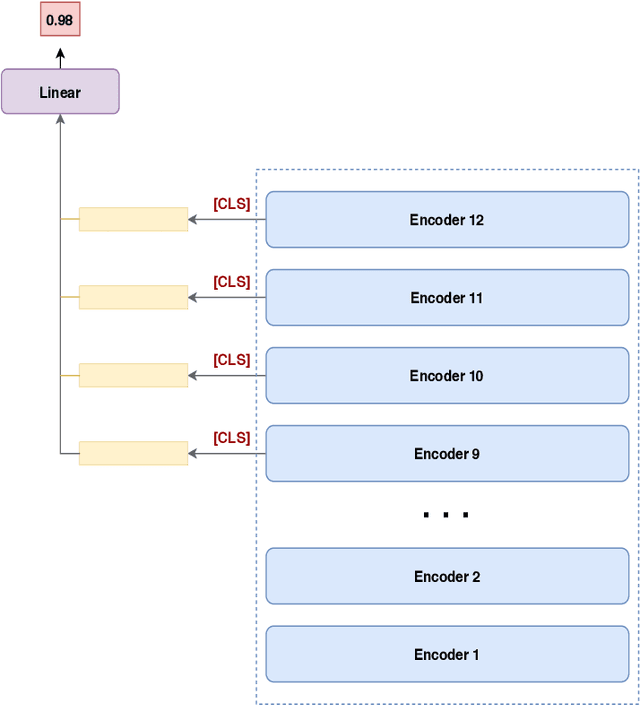
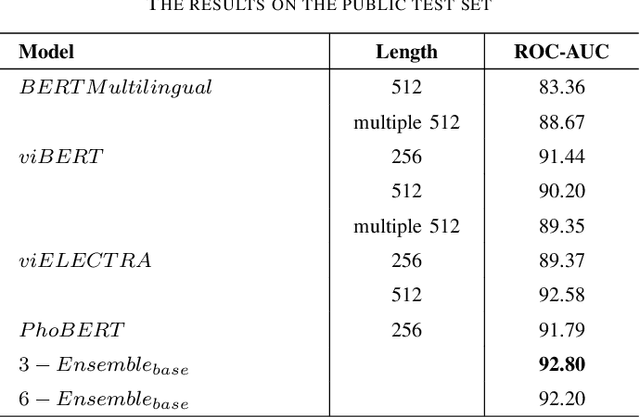
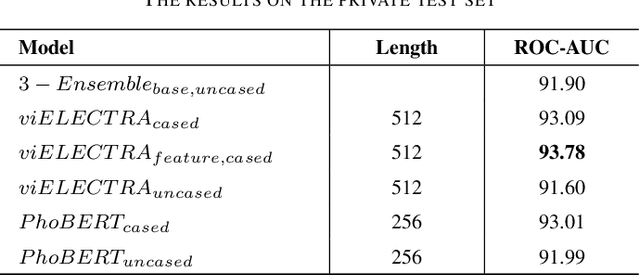
This paper proposed several transformer-based approaches for Reliable Intelligence Identification on Vietnamese social network sites at VLSP 2020 evaluation campaign. We exploit both of monolingual and multilingual pre-trained models. Besides, we utilize the ensemble method to improve the robustness of different approaches. Our team achieved a score of 0.9378 at ROC-AUC metric in the private test set which is competitive to other participants.