 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Motion Pattern: An Empirical Study of Physical Forces for Human Motion Understanding
Dec 23, 2025



Human motion understanding has advanced rapidly through vision-based progress in recognition, tracking, and captioning. However, most existing methods overlook physical cues such as joint actuation forces that are fundamental in biomechanics. This gap motivates our study: if and when do physically inferred forces enhance motion understanding? By incorporating forces into established motion understanding pipelines, we systematically evaluate their impact across baseline models on 3 major tasks: gait recognition, action recognition, and fine-grained video captioning. Across 8 benchmarks, incorporating forces yields consistent performance gains; for example, on CASIA-B, Rank-1 gait recognition accuracy improved from 89.52% to 90.39% (+0.87), with larger gain observed under challenging conditions: +2.7% when wearing a coat and +3.0% at the side view. On Gait3D, performance also increases from 46.0% to 47.3% (+1.3). In action recognition, CTR-GCN achieved +2.00% on Penn Action, while high-exertion classes like punching/slapping improved by +6.96%. Even in video captioning, Qwen2.5-VL's ROUGE-L score rose from 0.310 to 0.339 (+0.029), indicating that physics-inferred forces enhance temporal grounding and semantic richness. These results demonstrate that force cues can substantially complement visual and kinematic features under dynamic, occluded, or appearance-varying conditions.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
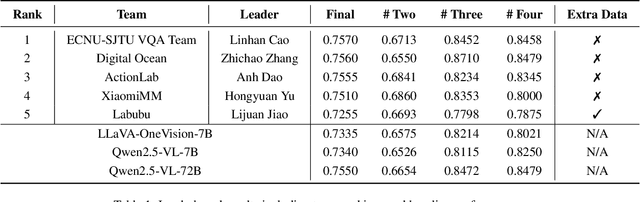
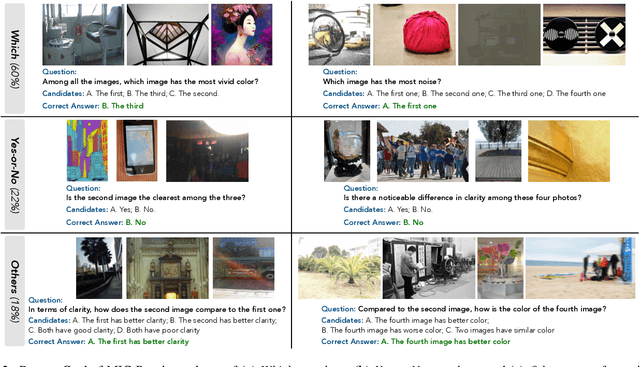
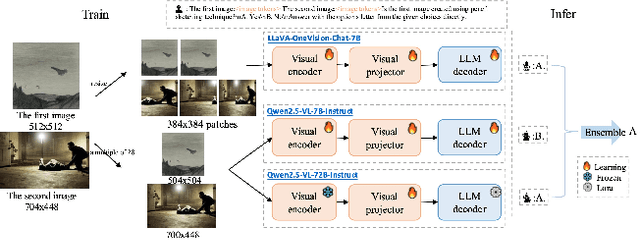
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
IndustryEQA: Pushing the Frontiers of Embodied Question Answering in Industrial Scenarios
May 27, 2025Existing Embodied Question Answering (EQA) benchmarks primarily focus on household environments, often overlooking safety-critical aspects and reasoning processes pertinent to industrial settings. This drawback limits the evaluation of agent readiness for real-world industrial applications. To bridge this, we introduce IndustryEQA, the first benchmark dedicated to evaluating embodied agent capabilities within safety-critical warehouse scenarios. Built upon the NVIDIA Isaac Sim platform, IndustryEQA provides high-fidelity episodic memory videos featuring diverse industrial assets, dynamic human agents, and carefully designed hazardous situations inspired by real-world safety guidelines. The benchmark includes rich annotations covering six categories: equipment safety, human safety, object recognition, attribute recognition, temporal understanding, and spatial understanding. Besides, it also provides extra reasoning evaluation based on these categories. Specifically, it comprises 971 question-answer pairs generated from small warehouse and 373 pairs from large ones, incorporating scenarios with and without human. We further propose a comprehensive evaluation framework, including various baseline models, to assess their general perception and reasoning abilities in industrial environments. IndustryEQA aims to steer EQA research towards developing more robust, safety-aware, and practically applicable embodied agents for complex industrial environments. Benchmark and codes are available.
Cycle Training with Semi-Supervised Domain Adaptation: Bridging Accuracy and Efficiency for Real-Time Mobile Scene Detection
Apr 12, 2025Nowadays, smartphones are ubiquitous, and almost everyone owns one. At the same time, the rapid development of AI has spurred extensive research on applying deep learning techniques to image classification. However, due to the limited resources available on mobile devices, significant challenges remain in balancing accuracy with computational efficiency. In this paper, we propose a novel training framework called Cycle Training, which adopts a three-stage training process that alternates between exploration and stabilization phases to optimize model performance. Additionally, we incorporate Semi-Supervised Domain Adaptation (SSDA) to leverage the power of large models and unlabeled data, thereby effectively expanding the training dataset. Comprehensive experiments on the CamSSD dataset for mobile scene detection demonstrate that our framework not only significantly improves classification accuracy but also ensures real-time inference efficiency. Specifically, our method achieves a 94.00% in Top-1 accuracy and a 99.17% in Top-3 accuracy and runs inference in just 1.61ms using CPU, demonstrating its suitability for real-world mobile deployment.
Towards Efficient and Robust Moment Retrieval System: A Unified Framework for Multi-Granularity Models and Temporal Reranking
Apr 11, 2025Long-form video understanding presents significant challenges for interactive retrieval systems, as conventional methods struggle to process extensive video content efficiently. Existing approaches often rely on single models, inefficient storage, unstable temporal search, and context-agnostic reranking, limiting their effectiveness. This paper presents a novel framework to enhance interactive video retrieval through four key innovations: (1) an ensemble search strategy that integrates coarse-grained (CLIP) and fine-grained (BEIT3) models to improve retrieval accuracy, (2) a storage optimization technique that reduces redundancy by selecting representative keyframes via TransNetV2 and deduplication, (3) a temporal search mechanism that localizes video segments using dual queries for start and end points, and (4) a temporal reranking approach that leverages neighboring frame context to stabilize rankings. Evaluated on known-item search and question-answering tasks, our framework demonstrates substantial improvements in retrieval precision, efficiency, and user interpretability, offering a robust solution for real-world interactive video retrieval applications.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025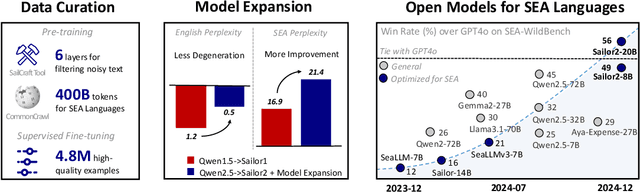
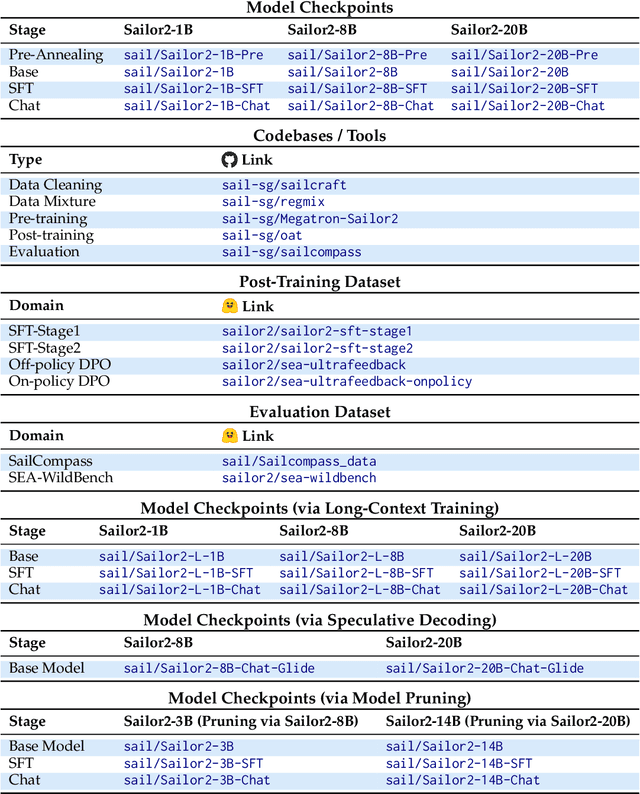

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
Visual Large Language Models for Generalized and Specialized Applications
Jan 06, 2025



Visual-language models (VLM) have emerged as a powerful tool for learning a unified embedding space for vision and language. Inspired by large language models, which have demonstrated strong reasoning and multi-task capabilities, visual large language models (VLLMs) are gaining increasing attention for building general-purpose VLMs. Despite the significant progress made in VLLMs, the related literature remains limited, particularly from a comprehensive application perspective, encompassing generalized and specialized applications across vision (image, video, depth), action, and language modalities. In this survey, we focus on the diverse applications of VLLMs, examining their using scenarios, identifying ethics consideration and challenges, and discussing future directions for their development. By synthesizing these contents, we aim to provide a comprehensive guide that will pave the way for future innovations and broader applications of VLLMs. The paper list repository is available: https://github.com/JackYFL/awesome-VLLMs.
LiteGPT: Large Vision-Language Model for Joint Chest X-ray Localization and Classification Task
Jul 16, 2024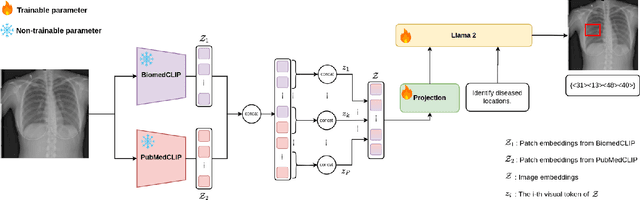

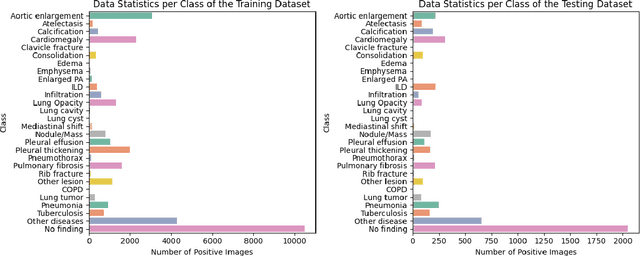

Vision-language models have been extensively explored across a wide range of tasks, achieving satisfactory performance; however, their application in medical imaging remains underexplored. In this work, we propose a unified framework - LiteGPT - for the medical imaging. We leverage multiple pre-trained visual encoders to enrich information and enhance the performance of vision-language models. To the best of our knowledge, this is the first study to utilize vision-language models for the novel task of joint localization and classification in medical images. Besides, we are pioneers in providing baselines for disease localization in chest X-rays. Finally, we set new state-of-the-art performance in the image classification task on the well-benchmarked VinDr-CXR dataset. All code and models are publicly available online: https://github.com/leduckhai/LiteGPT
Facial Affective Behavior Analysis with Instruction Tuning
Apr 07, 2024


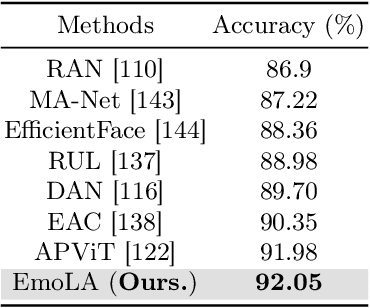
Facial affective behavior analysis (FABA) is crucial for understanding human mental states from images. However, traditional approaches primarily deploy models to discriminate among discrete emotion categories, and lack the fine granularity and reasoning capability for complex facial behaviors. The advent of Multi-modal Large Language Models (MLLMs) has been proven successful in general visual understanding tasks. However, directly harnessing MLLMs for FABA is challenging due to the scarcity of datasets and benchmarks, neglecting facial prior knowledge, and low training efficiency. To address these challenges, we introduce (i) an instruction-following dataset for two FABA tasks, e.g., emotion and action unit recognition, (ii) a benchmark FABA-Bench with a new metric considering both recognition and generation ability, and (iii) a new MLLM "EmoLA" as a strong baseline to the community. Our initiative on the dataset and benchmarks reveal the nature and rationale of facial affective behaviors, i.e., fine-grained facial movement, interpretability, and reasoning. Moreover, to build an effective and efficient FABA MLLM, we introduce a facial prior expert module with face structure knowledge and a low-rank adaptation module into pre-trained MLLM. We conduct extensive experiments on FABA-Bench and four commonly-used FABA datasets. The results demonstrate that the proposed facial prior expert can boost the performance and EmoLA achieves the best results on our FABA-Bench. On commonly-used FABA datasets, EmoLA is competitive rivaling task-specific state-of-the-art models.