 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteGPT: Large Vision-Language Model for Joint Chest X-ray Localization and Classification Task
Paper and Code
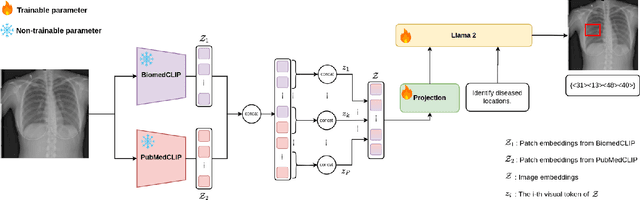

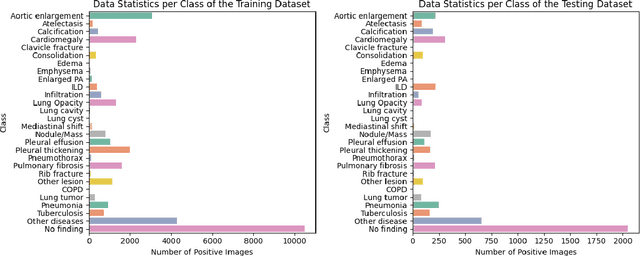

Vision-language models have been extensively explored across a wide range of tasks, achieving satisfactory performance; however, their application in medical imaging remains underexplored. In this work, we propose a unified framework - LiteGPT - for the medical imaging. We leverage multiple pre-trained visual encoders to enrich information and enhance the performance of vision-language models. To the best of our knowledge, this is the first study to utilize vision-language models for the novel task of joint localization and classification in medical images. Besides, we are pioneers in providing baselines for disease localization in chest X-rays. Finally, we set new state-of-the-art performance in the image classification task on the well-benchmarked VinDr-CXR dataset. All code and models are publicly available online: https://github.com/leduckhai/LiteGPT