 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLENDER: Blended Text Embeddings and Diffusion Residuals for Intra-Class Image Synthesis in Deep Metric Learning
Jan 28, 2026The rise of Deep Generative Models (DGM) has enabled the generation of high-quality synthetic data. When used to augment authentic data in Deep Metric Learning (DML), these synthetic samples enhance intra-class diversity and improve the performance of downstream DML tasks. We introduce BLenDeR, a diffusion sampling method designed to increase intra-class diversity for DML in a controllable way by leveraging set-theory inspired union and intersection operations on denoising residuals. The union operation encourages any attribute present across multiple prompts, while the intersection extracts the common direction through a principal component surrogate. These operations enable controlled synthesis of diverse attribute combinations within each class, addressing key limitations of existing generative approaches. Experiments on standard DML benchmarks demonstrate that BLenDeR consistently outperforms state-of-the-art baselines across multiple datasets and backbones. Specifically, BLenDeR achieves 3.7% increase in Recall@1 on CUB-200 and a 1.8% increase on Cars-196, compared to state-of-the-art baselines under standard experimental settings.
Uni-Hand: Universal Hand Motion Forecasting in Egocentric Views
Nov 18, 2025Forecasting how human hands move in egocentric views is critical for applications like augmented reality and human-robot policy transfer. Recently, several hand trajectory prediction (HTP) methods have been developed to generate future possible hand waypoints, which still suffer from insufficient prediction targets, inherent modality gaps, entangled hand-head motion, and limited validation in downstream tasks. To address these limitations, we present a universal hand motion forecasting framework considering multi-modal input, multi-dimensional and multi-target prediction patterns, and multi-task affordances for downstream applications. We harmonize multiple modalities by vision-language fusion, global context incorporation, and task-aware text embedding injection, to forecast hand waypoints in both 2D and 3D spaces. A novel dual-branch diffusion is proposed to concurrently predict human head and hand movements, capturing their motion synergy in egocentric vision. By introducing target indicators, the prediction model can forecast the specific joint waypoints of the wrist or the fingers, besides the widely studied hand center points. In addition, we enable Uni-Hand to additionally predict hand-object interaction states (contact/separation) to facilitate downstream tasks better. As the first work to incorporate downstream task evaluation in the literature, we build novel benchmarks to assess the real-world applicability of hand motion forecasting algorithms. The experimental results on multiple publicly available datasets and our newly proposed benchmarks demonstrate that Uni-Hand achieves the state-of-the-art performance in multi-dimensional and multi-target hand motion forecasting. Extensive validation in multiple downstream tasks also presents its impressive human-robot policy transfer to enable robotic manipulation, and effective feature enhancement for action anticipation/recognition.
Novel Diffusion Models for Multimodal 3D Hand Trajectory Prediction
Apr 10, 2025Predicting hand motion is critical for understanding human intentions and bridging the action space between human movements and robot manipulations. Existing hand trajectory prediction (HTP) methods forecast the future hand waypoints in 3D space conditioned on past egocentric observations. However, such models are only designed to accommodate 2D egocentric video inputs. There is a lack of awareness of multimodal environmental information from both 2D and 3D observations, hindering the further improvement of 3D HTP performance. In addition, these models overlook the synergy between hand movements and headset camera egomotion, either predicting hand trajectories in isolation or encoding egomotion only from past frames. To address these limitations, we propose novel diffusion models (MMTwin) for multimodal 3D hand trajectory prediction. MMTwin is designed to absorb multimodal information as input encompassing 2D RGB images, 3D point clouds, past hand waypoints, and text prompt. Besides, two latent diffusion models, the egomotion diffusion and the HTP diffusion as twins, are integrated into MMTwin to predict camera egomotion and future hand trajectories concurrently. We propose a novel hybrid Mamba-Transformer module as the denoising model of the HTP diffusion to better fuse multimodal features. The experimental results on three publicly available datasets and our self-recorded data demonstrate that our proposed MMTwin can predict plausible future 3D hand trajectories compared to the state-of-the-art baselines, and generalizes well to unseen environments. The code and pretrained models will be released at https://github.com/IRMVLab/MMTwin.
Window Token Concatenation for Efficient Visual Large Language Models
Apr 05, 2025To effectively reduce the visual tokens in Visual Large Language Models (VLLMs), we propose a novel approach called Window Token Concatenation (WiCo). Specifically, we employ a sliding window to concatenate spatially adjacent visual tokens. However, directly concatenating these tokens may group diverse tokens into one, and thus obscure some fine details. To address this challenge, we propose fine-tuning the last few layers of the vision encoder to adaptively adjust the visual tokens, encouraging that those within the same window exhibit similar features. To further enhance the performance on fine-grained visual understanding tasks, we introduce WiCo+, which decomposes the visual tokens in later layers of the LLM. Such a design enjoys the merits of the large perception field of the LLM for fine-grained visual understanding while keeping a small number of visual tokens for efficient inference. We perform extensive experiments on both coarse- and fine-grained visual understanding tasks based on LLaVA-1.5 and Shikra, showing better performance compared with existing token reduction projectors. The code is available: https://github.com/JackYFL/WiCo.
Visual Large Language Models for Generalized and Specialized Applications
Jan 06, 2025



Visual-language models (VLM) have emerged as a powerful tool for learning a unified embedding space for vision and language. Inspired by large language models, which have demonstrated strong reasoning and multi-task capabilities, visual large language models (VLLMs) are gaining increasing attention for building general-purpose VLMs. Despite the significant progress made in VLLMs, the related literature remains limited, particularly from a comprehensive application perspective, encompassing generalized and specialized applications across vision (image, video, depth), action, and language modalities. In this survey, we focus on the diverse applications of VLLMs, examining their using scenarios, identifying ethics consideration and challenges, and discussing future directions for their development. By synthesizing these contents, we aim to provide a comprehensive guide that will pave the way for future innovations and broader applications of VLLMs. The paper list repository is available: https://github.com/JackYFL/awesome-VLLMs.
Exploiting VLM Localizability and Semantics for Open Vocabulary Action Detection
Nov 17, 2024



Action detection aims to detect (recognize and localize) human actions spatially and temporally in videos. Existing approaches focus on the closed-set setting where an action detector is trained and tested on videos from a fixed set of action categories. However, this constrained setting is not viable in an open world where test videos inevitably come beyond the trained action categories. In this paper, we address the practical yet challenging Open-Vocabulary Action Detection (OVAD) problem. It aims to detect any action in test videos while training a model on a fixed set of action categories. To achieve such an open-vocabulary capability, we propose a novel method OpenMixer that exploits the inherent semantics and localizability of large vision-language models (VLM) within the family of query-based detection transformers (DETR). Specifically, the OpenMixer is developed by spatial and temporal OpenMixer blocks (S-OMB and T-OMB), and a dynamically fused alignment (DFA) module. The three components collectively enjoy the merits of strong generalization from pre-trained VLMs and end-to-end learning from DETR design. Moreover, we established OVAD benchmarks under various settings, and the experimental results show that the OpenMixer performs the best over baselines for detecting seen and unseen actions. We release the codes, models, and dataset splits at https://github.com/Cogito2012/OpenMixer.
Learning to Localize Actions in Instructional Videos with LLM-Based Multi-Pathway Text-Video Alignment
Sep 22, 2024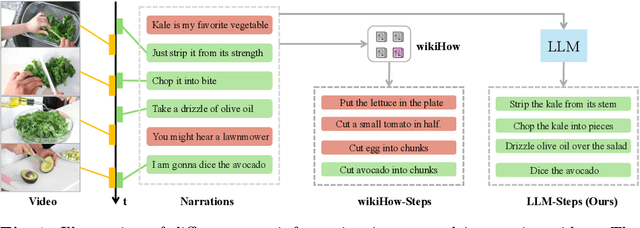



Learning to localize temporal boundaries of procedure steps in instructional videos is challenging due to the limited availability of annotated large-scale training videos. Recent works focus on learning the cross-modal alignment between video segments and ASR-transcripted narration texts through contrastive learning. However, these methods fail to account for the alignment noise, i.e., irrelevant narrations to the instructional task in videos and unreliable timestamps in narrations. To address these challenges, this work proposes a novel training framework. Motivated by the strong capabilities of Large Language Models (LLMs) in procedure understanding and text summarization, we first apply an LLM to filter out task-irrelevant information and summarize task-related procedure steps (LLM-steps) from narrations. To further generate reliable pseudo-matching between the LLM-steps and the video for training, we propose the Multi-Pathway Text-Video Alignment (MPTVA) strategy. The key idea is to measure alignment between LLM-steps and videos via multiple pathways, including: (1) step-narration-video alignment using narration timestamps, (2) direct step-to-video alignment based on their long-term semantic similarity, and (3) direct step-to-video alignment focusing on short-term fine-grained semantic similarity learned from general video domains. The results from different pathways are fused to generate reliable pseudo step-video matching. We conducted extensive experiments across various tasks and problem settings to evaluate our proposed method. Our approach surpasses state-of-the-art methods in three downstream tasks: procedure step grounding, step localization, and narration grounding by 5.9\%, 3.1\%, and 2.8\%.
MADiff: Motion-Aware Mamba Diffusion Models for Hand Trajectory Prediction on Egocentric Videos
Sep 04, 2024



Understanding human intentions and actions through egocentric videos is important on the path to embodied artificial intelligence. As a branch of egocentric vision techniques, hand trajectory prediction plays a vital role in comprehending human motion patterns, benefiting downstream tasks in extended reality and robot manipulation. However, capturing high-level human intentions consistent with reasonable temporal causality is challenging when only egocentric videos are available. This difficulty is exacerbated under camera egomotion interference and the absence of affordance labels to explicitly guide the optimization of hand waypoint distribution. In this work, we propose a novel hand trajectory prediction method dubbed MADiff, which forecasts future hand waypoints with diffusion models. The devised denoising operation in the latent space is achieved by our proposed motion-aware Mamba, where the camera wearer's egomotion is integrated to achieve motion-driven selective scan (MDSS). To discern the relationship between hands and scenarios without explicit affordance supervision, we leverage a foundation model that fuses visual and language features to capture high-level semantics from video clips. Comprehensive experiments conducted on five public datasets with the existing and our proposed new evaluation metrics demonstrate that MADiff predicts comparably reasonable hand trajectories compared to the state-of-the-art baselines, and achieves real-time performance. We will release our code and pretrained models of MADiff at the project page: https://irmvlab.github.io/madiff.github.io.
Facial Affective Behavior Analysis with Instruction Tuning
Apr 07, 2024


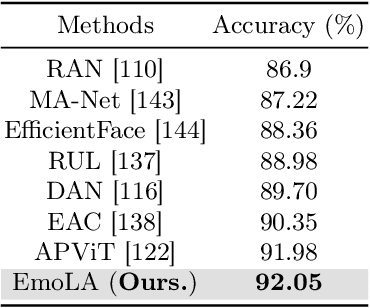
Facial affective behavior analysis (FABA) is crucial for understanding human mental states from images. However, traditional approaches primarily deploy models to discriminate among discrete emotion categories, and lack the fine granularity and reasoning capability for complex facial behaviors. The advent of Multi-modal Large Language Models (MLLMs) has been proven successful in general visual understanding tasks. However, directly harnessing MLLMs for FABA is challenging due to the scarcity of datasets and benchmarks, neglecting facial prior knowledge, and low training efficiency. To address these challenges, we introduce (i) an instruction-following dataset for two FABA tasks, e.g., emotion and action unit recognition, (ii) a benchmark FABA-Bench with a new metric considering both recognition and generation ability, and (iii) a new MLLM "EmoLA" as a strong baseline to the community. Our initiative on the dataset and benchmarks reveal the nature and rationale of facial affective behaviors, i.e., fine-grained facial movement, interpretability, and reasoning. Moreover, to build an effective and efficient FABA MLLM, we introduce a facial prior expert module with face structure knowledge and a low-rank adaptation module into pre-trained MLLM. We conduct extensive experiments on FABA-Bench and four commonly-used FABA datasets. The results demonstrate that the proposed facial prior expert can boost the performance and EmoLA achieves the best results on our FABA-Bench. On commonly-used FABA datasets, EmoLA is competitive rivaling task-specific state-of-the-art models.
Latent Space Energy-based Model for Fine-grained Open Set Recognition
Sep 19, 2023Fine-grained open-set recognition (FineOSR) aims to recognize images belonging to classes with subtle appearance differences while rejecting images of unknown classes. A recent trend in OSR shows the benefit of generative models to discriminative unknown detection. As a type of generative model, energy-based models (EBM) are the potential for hybrid modeling of generative and discriminative tasks. However, most existing EBMs suffer from density estimation in high-dimensional space, which is critical to recognizing images from fine-grained classes. In this paper, we explore the low-dimensional latent space with energy-based prior distribution for OSR in a fine-grained visual world. Specifically, based on the latent space EBM, we propose an attribute-aware information bottleneck (AIB), a residual attribute feature aggregation (RAFA) module, and an uncertainty-based virtual outlier synthesis (UVOS) module to improve the expressivity, granularity, and density of the samples in fine-grained classes, respectively. Our method is flexible to take advantage of recent vision transformers for powerful visual classification and generation. The method is validated on both fine-grained and general visual classification datasets while preserving the capability of generating photo-realistic fake images with high resolution.