 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
May 25, 2026Sparse-view 3D reconstruction is increasingly addressed with feed-forward splatting networks that predict explicit primitives directly from images. Yet most existing methods remain centered on Gaussian primitives and expose surfaces only indirectly: extracting a usable mesh for downstream simulation, physics reasoning, or embodied interaction still requires expensive post-hoc steps that break the feed-forward promise. This limitation is especially pronounced in pose-free settings, where scene structure and camera parameters must be estimated jointly from sparse observations. We present TriSplat, a feed-forward reconstruction network that represents scenes with oriented triangle primitives and directly exports simulation-ready mesh scenes from a single forward pass. Given input images, the network predicts local 3D point maps, triangle attributes, camera poses, and optional intrinsics. Rather than regressing triangle orientation as an unconstrained latent variable, our approach constructs geometry normals from the predicted point maps, refines them with an image-conditioned normal head, and converts them into stable local frames for triangle parameterization. A mono-normal bootstrap schedule further stabilizes early training, while opacity and blur scheduling progressively sharpens the learned surface representation for direct mesh extraction. Experiments on RealEstate10K and DL3DV show that this representation produces more geometry-faithful reconstructions than Gaussian feed-forward baselines while maintaining competitive novel-view rendering quality. Because the rendering primitives are themselves surface triangles, the output can be directly ingested by physics engines, collision detectors, and standard rendering pipelines without any conversion, making it a practical simulation-ready solution for feed-forward 3D scene reconstruction.
Controllable Egocentric Video Generation via Occlusion-Aware Sparse 3D Hand Joints
Mar 12, 2026Motion-controllable video generation is crucial for egocentric applications in virtual reality and embodied AI. However, existing methods often struggle to achieve 3D-consistent fine-grained hand articulation. By adopting on 2D trajectories or implicit poses, they collapse 3D geometry into spatially ambiguous signals or over rely on human-centric priors. Under severe egocentric occlusions, this causes motion inconsistencies and hallucinated artifacts, as well as preventing cross-embodiment generalization to robotic hands. To address these limitations, we propose a novel framework that generates egocentric videos from a single reference frame, leveraging sparse 3D hand joints as embodiment-agnostic control signals with clear semantic and geometric structures. We introduce an efficient control module that resolves occlusion ambiguities while fully preserving 3D information. Specifically, it extracts occlusion-aware features from the source reference frame by penalizing unreliable visual signals from hidden joints, and employs a 3D-based weighting mechanism to robustly handle dynamically occluded target joints during motion propagation. Concurrently, the module directly injects 3D geometric embeddings into the latent space to strictly enforce structural consistency. To facilitate robust training and evaluation, we develop an automated annotation pipeline that yields over one million high-quality egocentric video clips paired with precise hand trajectories. Additionally, we register humanoid kinematic and camera data to construct a cross-embodiment benchmark. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art baselines, generating high-fidelity egocentric videos with realistic interactions and exhibiting exceptional cross-embodiment generalization to robotic hands.
ReCoSplat: Autoregressive Feed-Forward Gaussian Splatting Using Render-and-Compare
Mar 10, 2026Online novel view synthesis remains challenging, requiring robust scene reconstruction from sequential, often unposed, observations. We present ReCoSplat, an autoregressive feed-forward Gaussian Splatting model supporting posed or unposed inputs, with or without camera intrinsics. While assembling local Gaussians using camera poses scales better than canonical-space prediction, it creates a dilemma during training: using ground-truth poses ensures stability but causes a distribution mismatch when predicted poses are used at inference. To address this, we introduce a Render-and-Compare (ReCo) module. ReCo renders the current reconstruction from the predicted viewpoint and compares it with the incoming observation, providing a stable conditioning signal that compensates for pose errors. To support long sequences, we propose a hybrid KV cache compression strategy combining early-layer truncation with chunk-level selective retention, reducing the KV cache size by over 90% for 100+ frames. ReCoSplat achieves state-of-the-art performance across different input settings on both in- and out-of-distribution benchmarks. Code and pretrained models will be released. Our project page is at https://freemancheng.com/ReCoSplat .
YoNoSplat: You Only Need One Model for Feedforward 3D Gaussian Splatting
Nov 10, 2025Fast and flexible 3D scene reconstruction from unstructured image collections remains a significant challenge. We present YoNoSplat, a feedforward model that reconstructs high-quality 3D Gaussian Splatting representations from an arbitrary number of images. Our model is highly versatile, operating effectively with both posed and unposed, calibrated and uncalibrated inputs. YoNoSplat predicts local Gaussians and camera poses for each view, which are aggregated into a global representation using either predicted or provided poses. To overcome the inherent difficulty of jointly learning 3D Gaussians and camera parameters, we introduce a novel mixing training strategy. This approach mitigates the entanglement between the two tasks by initially using ground-truth poses to aggregate local Gaussians and gradually transitioning to a mix of predicted and ground-truth poses, which prevents both training instability and exposure bias. We further resolve the scale ambiguity problem by a novel pairwise camera-distance normalization scheme and by embedding camera intrinsics into the network. Moreover, YoNoSplat also predicts intrinsic parameters, making it feasible for uncalibrated inputs. YoNoSplat demonstrates exceptional efficiency, reconstructing a scene from 100 views (at 280x518 resolution) in just 2.69 seconds on an NVIDIA GH200 GPU. It achieves state-of-the-art performance on standard benchmarks in both pose-free and pose-dependent settings. Our project page is at https://botaoye.github.io/yonosplat/.
HoliGS: Holistic Gaussian Splatting for Embodied View Synthesis
Jun 24, 2025We propose HoliGS, a novel deformable Gaussian splatting framework that addresses embodied view synthesis from long monocular RGB videos. Unlike prior 4D Gaussian splatting and dynamic NeRF pipelines, which struggle with training overhead in minute-long captures, our method leverages invertible Gaussian Splatting deformation networks to reconstruct large-scale, dynamic environments accurately. Specifically, we decompose each scene into a static background plus time-varying objects, each represented by learned Gaussian primitives undergoing global rigid transformations, skeleton-driven articulation, and subtle non-rigid deformations via an invertible neural flow. This hierarchical warping strategy enables robust free-viewpoint novel-view rendering from various embodied camera trajectories by attaching Gaussians to a complete canonical foreground shape (\eg, egocentric or third-person follow), which may involve substantial viewpoint changes and interactions between multiple actors. Our experiments demonstrate that \ourmethod~ achieves superior reconstruction quality on challenging datasets while significantly reducing both training and rendering time compared to state-of-the-art monocular deformable NeRFs. These results highlight a practical and scalable solution for EVS in real-world scenarios. The source code will be released.
Window Token Concatenation for Efficient Visual Large Language Models
Apr 05, 2025To effectively reduce the visual tokens in Visual Large Language Models (VLLMs), we propose a novel approach called Window Token Concatenation (WiCo). Specifically, we employ a sliding window to concatenate spatially adjacent visual tokens. However, directly concatenating these tokens may group diverse tokens into one, and thus obscure some fine details. To address this challenge, we propose fine-tuning the last few layers of the vision encoder to adaptively adjust the visual tokens, encouraging that those within the same window exhibit similar features. To further enhance the performance on fine-grained visual understanding tasks, we introduce WiCo+, which decomposes the visual tokens in later layers of the LLM. Such a design enjoys the merits of the large perception field of the LLM for fine-grained visual understanding while keeping a small number of visual tokens for efficient inference. We perform extensive experiments on both coarse- and fine-grained visual understanding tasks based on LLaVA-1.5 and Shikra, showing better performance compared with existing token reduction projectors. The code is available: https://github.com/JackYFL/WiCo.
Synthesizing Consistent Novel Views via 3D Epipolar Attention without Re-Training
Feb 25, 2025Large diffusion models demonstrate remarkable zero-shot capabilities in novel view synthesis from a single image. However, these models often face challenges in maintaining consistency across novel and reference views. A crucial factor leading to this issue is the limited utilization of contextual information from reference views. Specifically, when there is an overlap in the viewing frustum between two views, it is essential to ensure that the corresponding regions maintain consistency in both geometry and appearance. This observation leads to a simple yet effective approach, where we propose to use epipolar geometry to locate and retrieve overlapping information from the input view. This information is then incorporated into the generation of target views, eliminating the need for training or fine-tuning, as the process requires no learnable parameters. Furthermore, to enhance the overall consistency of generated views, we extend the utilization of epipolar attention to a multi-view setting, allowing retrieval of overlapping information from the input view and other target views. Qualitative and quantitative experimental results demonstrate the effectiveness of our method in significantly improving the consistency of synthesized views without the need for any fine-tuning. Moreover, This enhancement also boosts the performance of downstream applications such as 3D reconstruction. The code is available at https://github.com/botaoye/ConsisSyn.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
No Pose, No Problem: Surprisingly Simple 3D Gaussian Splats from Sparse Unposed Images
Oct 31, 2024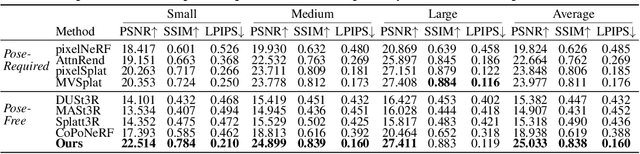
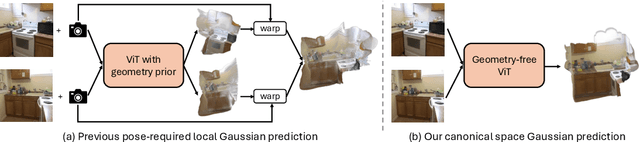
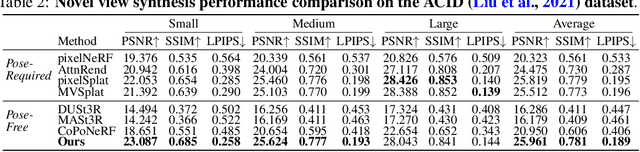
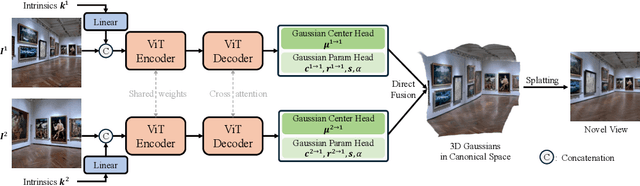
We introduce NoPoSplat, a feed-forward model capable of reconstructing 3D scenes parameterized by 3D Gaussians from \textit{unposed} sparse multi-view images. Our model, trained exclusively with photometric loss, achieves real-time 3D Gaussian reconstruction during inference. To eliminate the need for accurate pose input during reconstruction, we anchor one input view's local camera coordinates as the canonical space and train the network to predict Gaussian primitives for all views within this space. This approach obviates the need to transform Gaussian primitives from local coordinates into a global coordinate system, thus avoiding errors associated with per-frame Gaussians and pose estimation. To resolve scale ambiguity, we design and compare various intrinsic embedding methods, ultimately opting to convert camera intrinsics into a token embedding and concatenate it with image tokens as input to the model, enabling accurate scene scale prediction. We utilize the reconstructed 3D Gaussians for novel view synthesis and pose estimation tasks and propose a two-stage coarse-to-fine pipeline for accurate pose estimation. Experimental results demonstrate that our pose-free approach can achieve superior novel view synthesis quality compared to pose-required methods, particularly in scenarios with limited input image overlap. For pose estimation, our method, trained without ground truth depth or explicit matching loss, significantly outperforms the state-of-the-art methods with substantial improvements. This work makes significant advances in pose-free generalizable 3D reconstruction and demonstrates its applicability to real-world scenarios. Code and trained models are available at https://noposplat.github.io/.
Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
Mar 24, 2022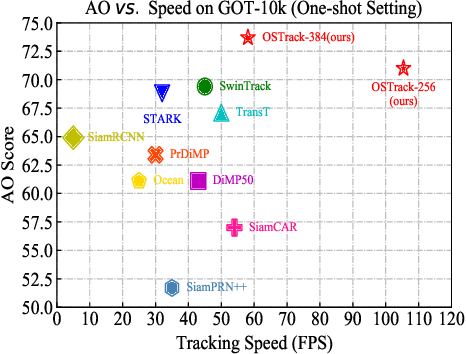
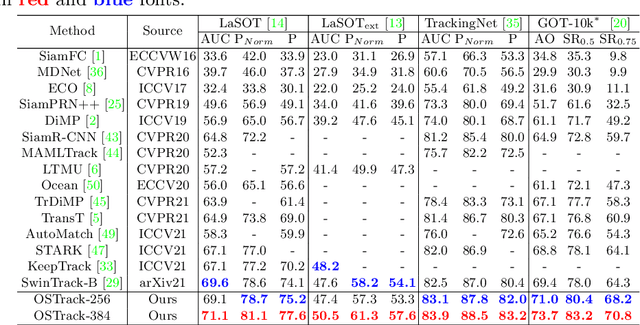
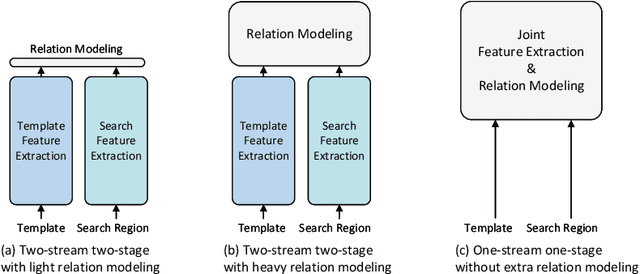

The current popular two-stream, two-stage tracking framework extracts the template and the search region features separately and then performs relation modeling, thus the extracted features lack the awareness of the target and have limited target-background discriminability. To tackle the above issue, we propose a novel one-stream tracking (OSTrack) framework that unifies feature learning and relation modeling by bridging the template-search image pairs with bidirectional information flows. In this way, discriminative target-oriented features can be dynamically extracted by mutual guidance. Since no extra heavy relation modeling module is needed and the implementation is highly parallelized, the proposed tracker runs at a fast speed. To further improve the inference efficiency, an in-network candidate early elimination module is proposed based on the strong similarity prior calculated in the one-stream framework. As a unified framework, OSTrack achieves state-of-the-art performance on multiple benchmarks, in particular, it shows impressive results on the one-shot tracking benchmark GOT-10k, i.e., achieving 73.7% AO, improving the existing best result (SwinTrack) by 4.3%. Besides, our method maintains a good performance-speed trade-off and shows faster convergence. The code and models will be available at https://github.com/botaoye/OSTrack.