 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWheat3DGS: In-field 3D Reconstruction, Instance Segmentation and Phenotyping of Wheat Heads with Gaussian Splatting
Apr 09, 2025
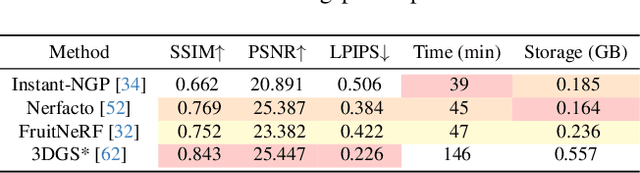
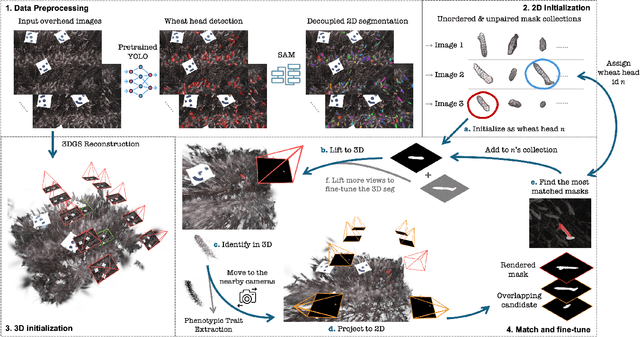

Automated extraction of plant morphological traits is crucial for supporting crop breeding and agricultural management through high-throughput field phenotyping (HTFP). Solutions based on multi-view RGB images are attractive due to their scalability and affordability, enabling volumetric measurements that 2D approaches cannot directly capture. While advanced methods like Neural Radiance Fields (NeRFs) have shown promise, their application has been limited to counting or extracting traits from only a few plants or organs. Furthermore, accurately measuring complex structures like individual wheat heads-essential for studying crop yields-remains particularly challenging due to occlusions and the dense arrangement of crop canopies in field conditions. The recent development of 3D Gaussian Splatting (3DGS) offers a promising alternative for HTFP due to its high-quality reconstructions and explicit point-based representation. In this paper, we present Wheat3DGS, a novel approach that leverages 3DGS and the Segment Anything Model (SAM) for precise 3D instance segmentation and morphological measurement of hundreds of wheat heads automatically, representing the first application of 3DGS to HTFP. We validate the accuracy of wheat head extraction against high-resolution laser scan data, obtaining per-instance mean absolute percentage errors of 15.1%, 18.3%, and 40.2% for length, width, and volume. We provide additional comparisons to NeRF-based approaches and traditional Muti-View Stereo (MVS), demonstrating superior results. Our approach enables rapid, non-destructive measurements of key yield-related traits at scale, with significant implications for accelerating crop breeding and improving our understanding of wheat development.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
3D Pose Based Feedback for Physical Exercises
Aug 05, 2022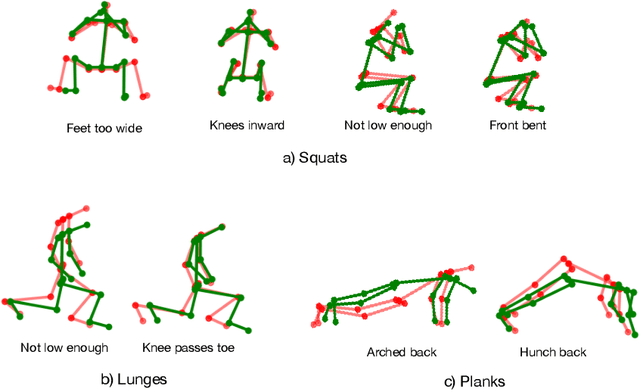
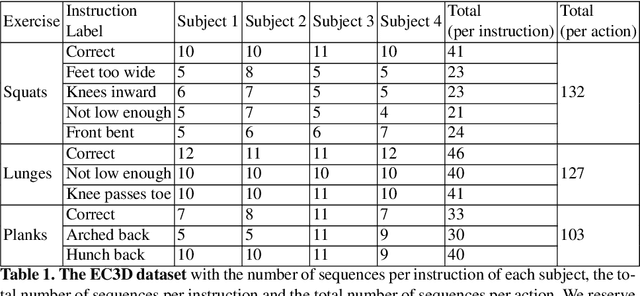
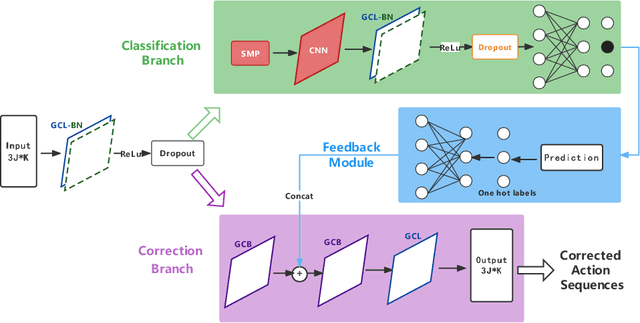
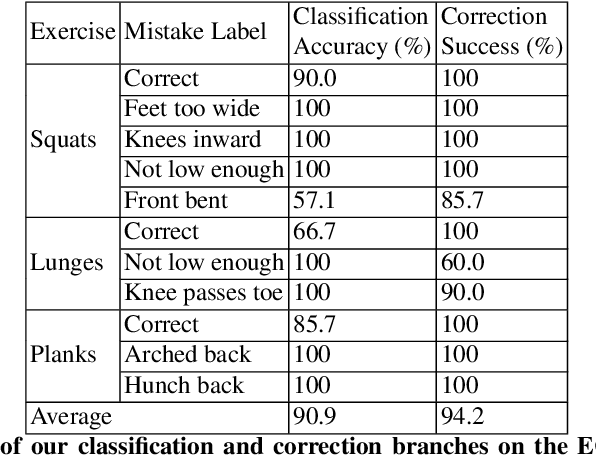
Unsupervised self-rehabilitation exercises and physical training can cause serious injuries if performed incorrectly. We introduce a learning-based framework that identifies the mistakes made by a user and proposes corrective measures for easier and safer individual training. Our framework does not rely on hard-coded, heuristic rules. Instead, it learns them from data, which facilitates its adaptation to specific user needs. To this end, we use a Graph Convolutional Network (GCN) architecture acting on the user's pose sequence to model the relationship between the body joints trajectories. To evaluate our approach, we introduce a dataset with 3 different physical exercises. Our approach yields 90.9% mistake identification accuracy and successfully corrects 94.2% of the mistakes.
Dyadic Human Motion Prediction
Dec 01, 2021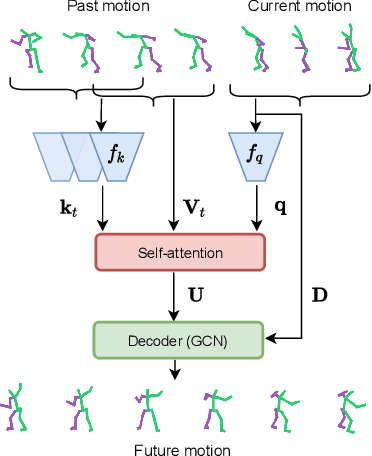
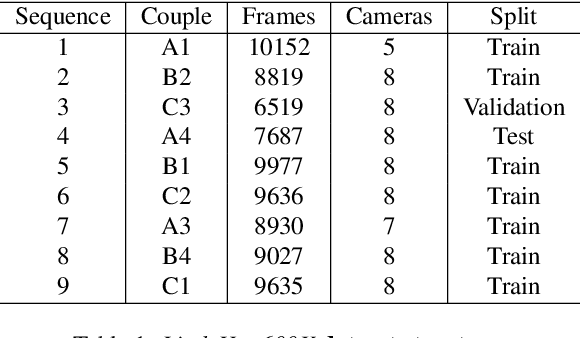
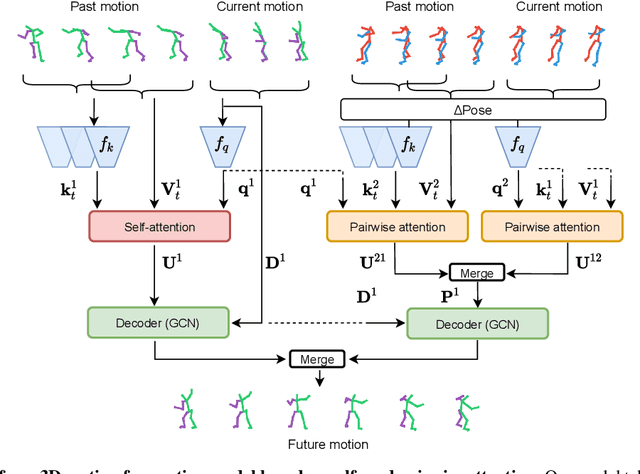

Prior work on human motion forecasting has mostly focused on predicting the future motion of single subjects in isolation from their past pose sequence. In the presence of closely interacting people, however, this strategy fails to account for the dependencies between the different subject's motions. In this paper, we therefore introduce a motion prediction framework that explicitly reasons about the interactions of two observed subjects. Specifically, we achieve this by introducing a pairwise attention mechanism that models the mutual dependencies in the motion history of the two subjects. This allows us to preserve the long-term motion dynamics in a more realistic way and more robustly predict unusual and fast-paced movements, such as the ones occurring in a dance scenario. To evaluate this, and because no existing motion prediction datasets depict two closely-interacting subjects, we introduce the LindyHop600K dance dataset. Our results evidence that our approach outperforms the state-of-the-art single person motion prediction techniques.
Self-supervised Human Detection and Segmentation via Multi-view Consensus
Dec 09, 2020


Self-supervised detection and segmentation of foreground objects in complex scenes is gaining attention as their fully-supervised counterparts require overly large amounts of annotated data to deliver sufficient accuracy in domain-specific applications. However, existing self-supervised approaches predominantly rely on restrictive assumptions on appearance and motion, which precludes their use in scenes depicting highly dynamic activities or involve camera motion. To mitigate this problem, we propose using a multi-camera framework in which geometric constraints are embedded in the form of multi-view consistency during training via coarse 3D localization in a voxel grid and fine-grained offset regression. In this manner, we learn a joint distribution of proposals over multiple views. At inference time, our method operates on single RGB images. We show that our approach outperforms state-of-the-art self-supervised person detection and segmentation techniques on images that visually depart from those of standard benchmarks, as well as on those of the classical Human3.6M dataset.
Self-supervised Segmentation via Background Inpainting
Nov 11, 2020
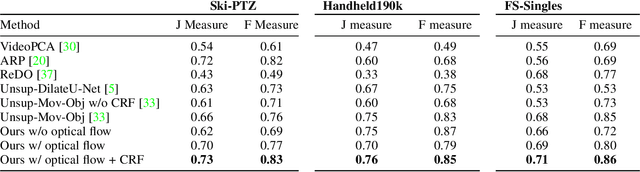
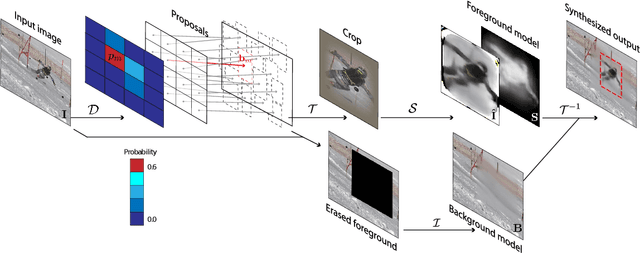

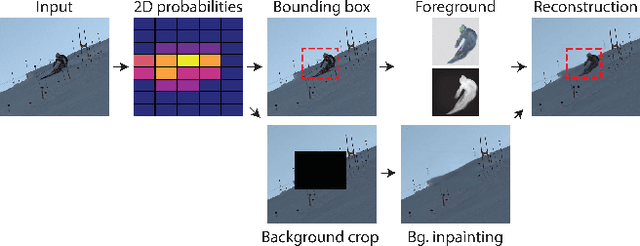
While supervised object detection and segmentation methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this when annotating data is prohibitively expensive, we introduce a self-supervised detection and segmentation approach that can work with single images captured by a potentially moving camera. At the heart of our approach lies the observation that object segmentation and background reconstruction are linked tasks, and that, for structured scenes, background regions can be re-synthesized from their surroundings, whereas regions depicting the moving object cannot. We encode this intuition into a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of the proposals, we develop a Monte Carlo-based training strategy that allows the algorithm to explore the large space of object proposals. We apply our method to human detection and segmentation in images that visually depart from those of standard benchmarks and outperform existing self-supervised methods.
Self-supervised Training of Proposal-based Segmentation via Background Prediction
Jul 18, 2019

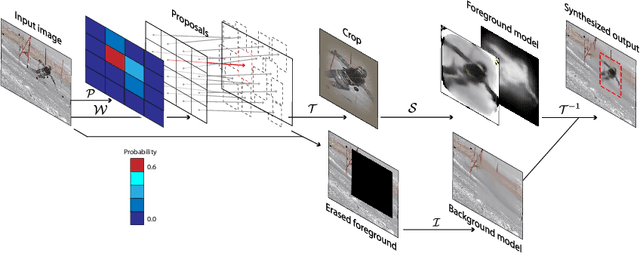
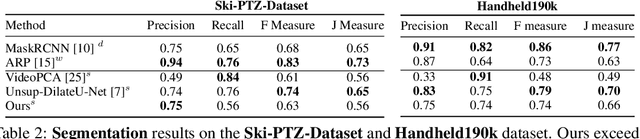
While supervised object detection methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this in scenarios where annotating data is prohibitively expensive, we introduce a self-supervised approach to object detection and segmentation, able to work with monocular images captured with a moving camera. At the heart of our approach lies the observation that segmentation and background reconstruction are linked tasks, and the idea that, because we observe a structured scene, background regions can be re-synthesized from their surroundings, whereas regions depicting the object cannot. We therefore encode this intuition as a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of object proposals, we develop a Monte Carlo-based training strategy that allows us to explore the large space of object proposals. Our experiments demonstrate that our approach yields accurate detections and segmentations in images that visually depart from those of standard benchmarks, outperforming existing self-supervised methods and approaching weakly supervised ones that exploit large annotated datasets.
Neural Scene Decomposition for Multi-Person Motion Capture
Mar 13, 2019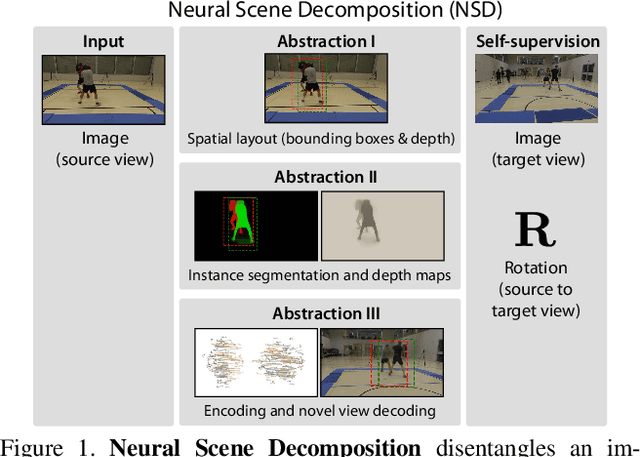
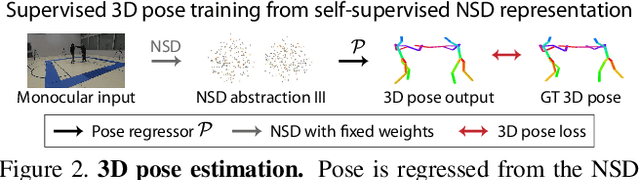
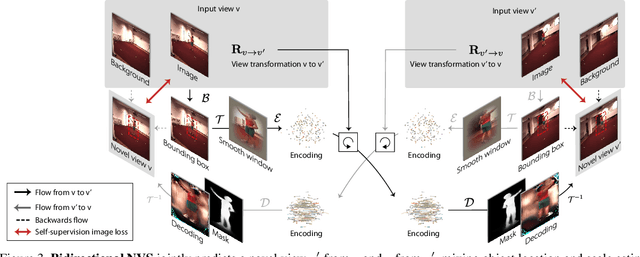

Learning general image representations has proven key to the success of many computer vision tasks. For example, many approaches to image understanding problems rely on deep networks that were initially trained on ImageNet, mostly because the learned features are a valuable starting point to learn from limited labeled data. However, when it comes to 3D motion capture of multiple people, these features are only of limited use. In this paper, we therefore propose an approach to learning features that are useful for this purpose. To this end, we introduce a self-supervised approach to learning what we call a neural scene decomposition (NSD) that can be exploited for 3D pose estimation. NSD comprises three layers of abstraction to represent human subjects: spatial layout in terms of bounding-boxes and relative depth; a 2D shape representation in terms of an instance segmentation mask; and subject-specific appearance and 3D pose information. By exploiting self-supervision coming from multiview data, our NSD model can be trained end-to-end without any 2D or 3D supervision. In contrast to previous approaches, it works for multiple persons and full-frame images. Because it encodes 3D geometry, NSD can then be effectively leveraged to train a 3D pose estimation network from small amounts of annotated data.
Learning Monocular 3D Human Pose Estimation from Multi-view Images
Mar 24, 2018
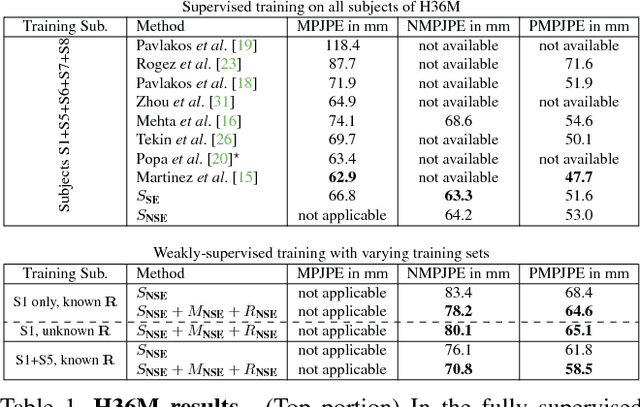

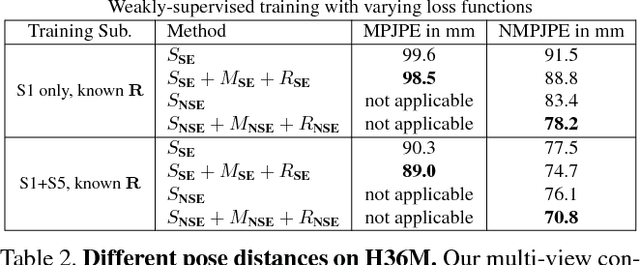
Accurate 3D human pose estimation from single images is possible with sophisticated deep-net architectures that have been trained on very large datasets. However, this still leaves open the problem of capturing motions for which no such database exists. Manual annotation is tedious, slow, and error-prone. In this paper, we propose to replace most of the annotations by the use of multiple views, at training time only. Specifically, we train the system to predict the same pose in all views. Such a consistency constraint is necessary but not sufficient to predict accurate poses. We therefore complement it with a supervised loss aiming to predict the correct pose in a small set of labeled images, and with a regularization term that penalizes drift from initial predictions. Furthermore, we propose a method to estimate camera pose jointly with human pose, which lets us utilize multi-view footage where calibration is difficult, e.g., for pan-tilt or moving handheld cameras. We demonstrate the effectiveness of our approach on established benchmarks, as well as on a new Ski dataset with rotating cameras and expert ski motion, for which annotations are truly hard to obtain.
Structured Prediction of 3D Human Pose with Deep Neural Networks
May 17, 2016
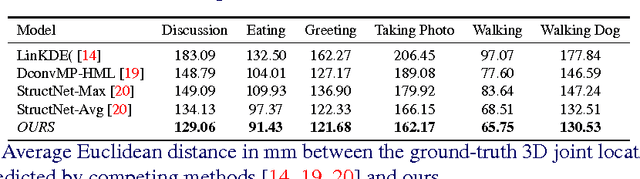
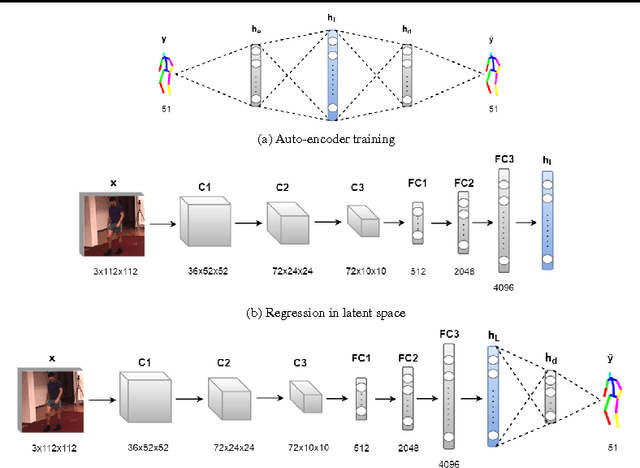
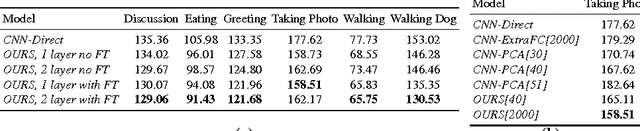
Most recent approaches to monocular 3D pose estimation rely on Deep Learning. They either train a Convolutional Neural Network to directly regress from image to 3D pose, which ignores the dependencies between human joints, or model these dependencies via a max-margin structured learning framework, which involves a high computational cost at inference time. In this paper, we introduce a Deep Learning regression architecture for structured prediction of 3D human pose from monocular images that relies on an overcomplete auto-encoder to learn a high-dimensional latent pose representation and account for joint dependencies. We demonstrate that our approach outperforms state-of-the-art ones both in terms of structure preservation and prediction accuracy.