 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Human Detection and Segmentation via Multi-view Consensus
Dec 09, 2020


Self-supervised detection and segmentation of foreground objects in complex scenes is gaining attention as their fully-supervised counterparts require overly large amounts of annotated data to deliver sufficient accuracy in domain-specific applications. However, existing self-supervised approaches predominantly rely on restrictive assumptions on appearance and motion, which precludes their use in scenes depicting highly dynamic activities or involve camera motion. To mitigate this problem, we propose using a multi-camera framework in which geometric constraints are embedded in the form of multi-view consistency during training via coarse 3D localization in a voxel grid and fine-grained offset regression. In this manner, we learn a joint distribution of proposals over multiple views. At inference time, our method operates on single RGB images. We show that our approach outperforms state-of-the-art self-supervised person detection and segmentation techniques on images that visually depart from those of standard benchmarks, as well as on those of the classical Human3.6M dataset.
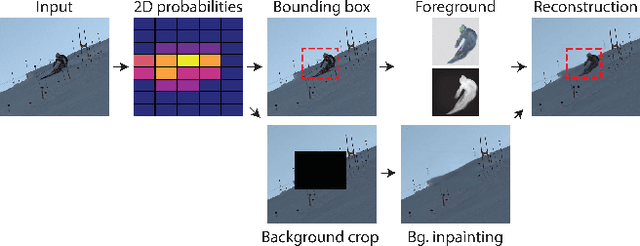
Self-supervised Segmentation via Background Inpainting
Nov 11, 2020
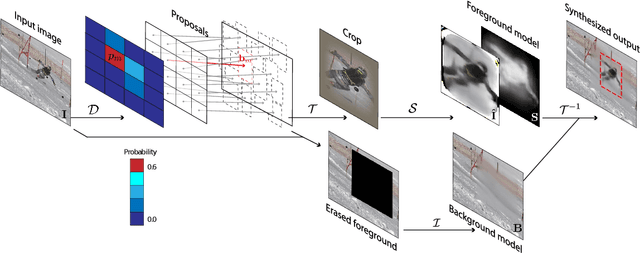

While supervised object detection and segmentation methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this when annotating data is prohibitively expensive, we introduce a self-supervised detection and segmentation approach that can work with single images captured by a potentially moving camera. At the heart of our approach lies the observation that object segmentation and background reconstruction are linked tasks, and that, for structured scenes, background regions can be re-synthesized from their surroundings, whereas regions depicting the moving object cannot. We encode this intuition into a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of the proposals, we develop a Monte Carlo-based training strategy that allows the algorithm to explore the large space of object proposals. We apply our method to human detection and segmentation in images that visually depart from those of standard benchmarks and outperform existing self-supervised methods.
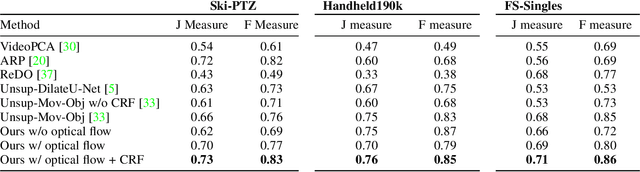
Motion Capture from Pan-Tilt Cameras with Unknown Orientation
Aug 30, 2019
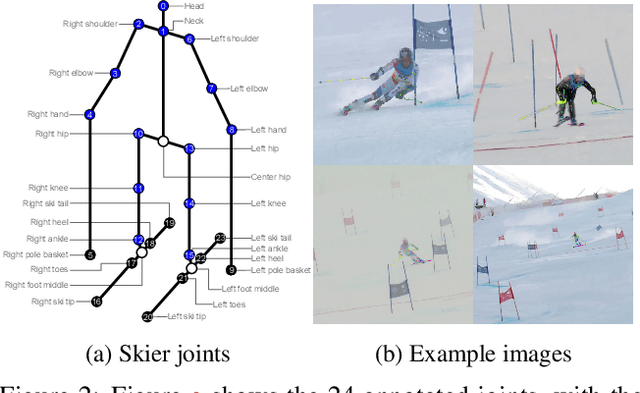
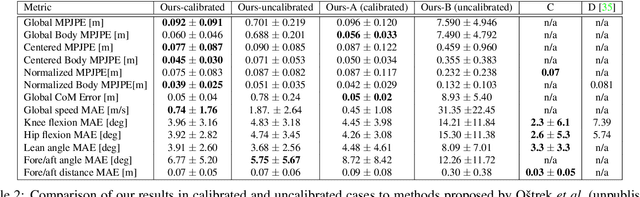
In sports, such as alpine skiing, coaches would like to know the speed and various biomechanical variables of their athletes and competitors. Existing methods use either body-worn sensors, which are cumbersome to setup, or manual image annotation, which is time consuming. We propose a method for estimating an athlete's global 3D position and articulated pose using multiple cameras. By contrast to classical markerless motion capture solutions, we allow cameras to rotate freely so that large capture volumes can be covered. In a first step, tight crops around the skier are predicted and fed to a 2D pose estimator network. The 3D pose is then reconstructed using a bundle adjustment method. Key to our solution is the rotation estimation of Pan-Tilt cameras in a joint optimization with the athlete pose and conditioning on relative background motion computed with feature tracking. Furthermore, we created a new alpine skiing dataset and annotated it with 2D pose labels, to overcome shortcomings of existing ones. Our method estimates accurate global 3D poses from images only and provides coaches with an automatic and fast tool for measuring and improving an athlete's performance.
Self-supervised Training of Proposal-based Segmentation via Background Prediction
Jul 18, 2019

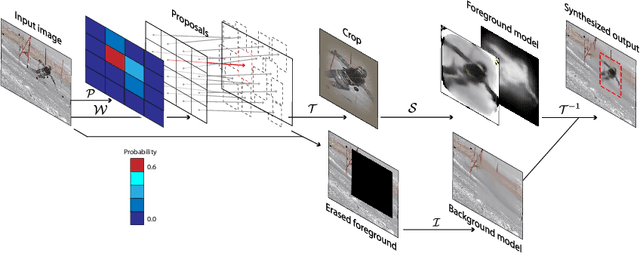
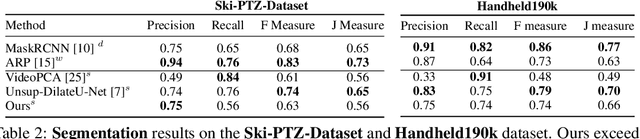
While supervised object detection methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this in scenarios where annotating data is prohibitively expensive, we introduce a self-supervised approach to object detection and segmentation, able to work with monocular images captured with a moving camera. At the heart of our approach lies the observation that segmentation and background reconstruction are linked tasks, and the idea that, because we observe a structured scene, background regions can be re-synthesized from their surroundings, whereas regions depicting the object cannot. We therefore encode this intuition as a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of object proposals, we develop a Monte Carlo-based training strategy that allows us to explore the large space of object proposals. Our experiments demonstrate that our approach yields accurate detections and segmentations in images that visually depart from those of standard benchmarks, outperforming existing self-supervised methods and approaching weakly supervised ones that exploit large annotated datasets.
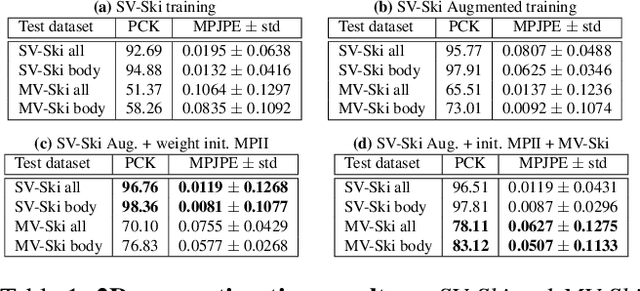
Learning Monocular 3D Human Pose Estimation from Multi-view Images
Mar 24, 2018
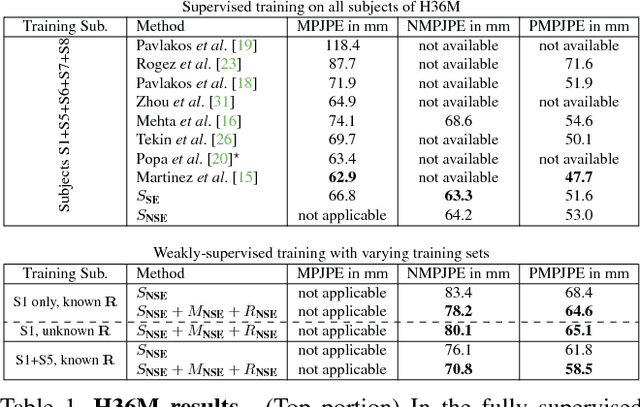

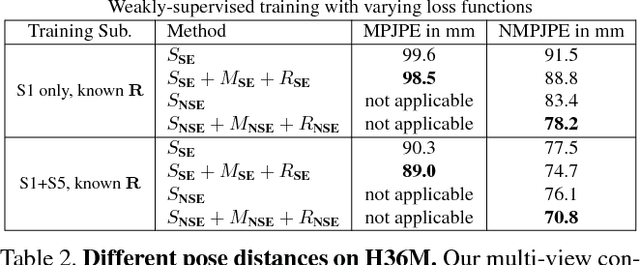
Accurate 3D human pose estimation from single images is possible with sophisticated deep-net architectures that have been trained on very large datasets. However, this still leaves open the problem of capturing motions for which no such database exists. Manual annotation is tedious, slow, and error-prone. In this paper, we propose to replace most of the annotations by the use of multiple views, at training time only. Specifically, we train the system to predict the same pose in all views. Such a consistency constraint is necessary but not sufficient to predict accurate poses. We therefore complement it with a supervised loss aiming to predict the correct pose in a small set of labeled images, and with a regularization term that penalizes drift from initial predictions. Furthermore, we propose a method to estimate camera pose jointly with human pose, which lets us utilize multi-view footage where calibration is difficult, e.g., for pan-tilt or moving handheld cameras. We demonstrate the effectiveness of our approach on established benchmarks, as well as on a new Ski dataset with rotating cameras and expert ski motion, for which annotations are truly hard to obtain.