 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Training of Proposal-based Segmentation via Background Prediction
Paper and Code
Jul 18, 2019

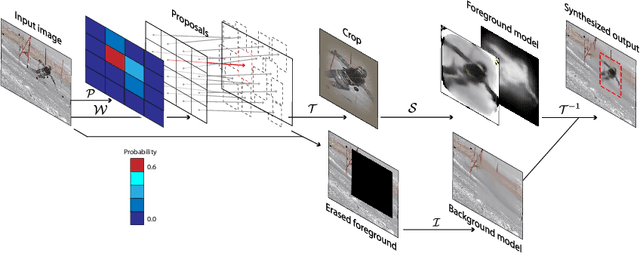
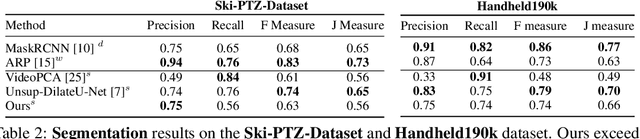
While supervised object detection methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this in scenarios where annotating data is prohibitively expensive, we introduce a self-supervised approach to object detection and segmentation, able to work with monocular images captured with a moving camera. At the heart of our approach lies the observation that segmentation and background reconstruction are linked tasks, and the idea that, because we observe a structured scene, background regions can be re-synthesized from their surroundings, whereas regions depicting the object cannot. We therefore encode this intuition as a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of object proposals, we develop a Monte Carlo-based training strategy that allows us to explore the large space of object proposals. Our experiments demonstrate that our approach yields accurate detections and segmentations in images that visually depart from those of standard benchmarks, outperforming existing self-supervised methods and approaching weakly supervised ones that exploit large annotated datasets.