 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Human Detection and Segmentation via Multi-view Consensus
Paper and Code

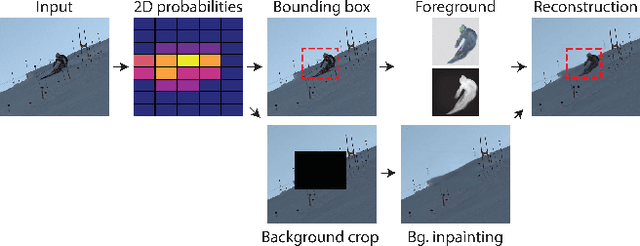


Self-supervised detection and segmentation of foreground objects in complex scenes is gaining attention as their fully-supervised counterparts require overly large amounts of annotated data to deliver sufficient accuracy in domain-specific applications. However, existing self-supervised approaches predominantly rely on restrictive assumptions on appearance and motion, which precludes their use in scenes depicting highly dynamic activities or involve camera motion. To mitigate this problem, we propose using a multi-camera framework in which geometric constraints are embedded in the form of multi-view consistency during training via coarse 3D localization in a voxel grid and fine-grained offset regression. In this manner, we learn a joint distribution of proposals over multiple views. At inference time, our method operates on single RGB images. We show that our approach outperforms state-of-the-art self-supervised person detection and segmentation techniques on images that visually depart from those of standard benchmarks, as well as on those of the classical Human3.6M dataset.