 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Pose Based Feedback for Physical Exercises
Aug 05, 2022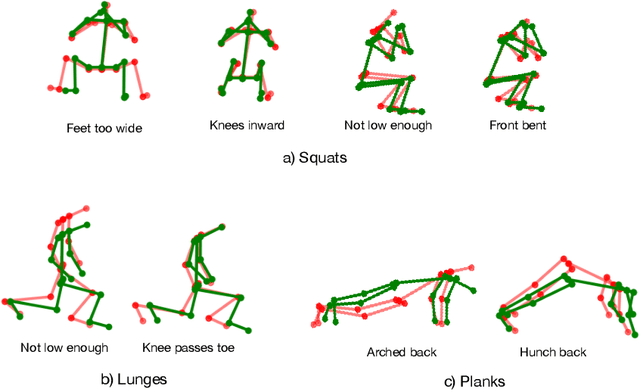
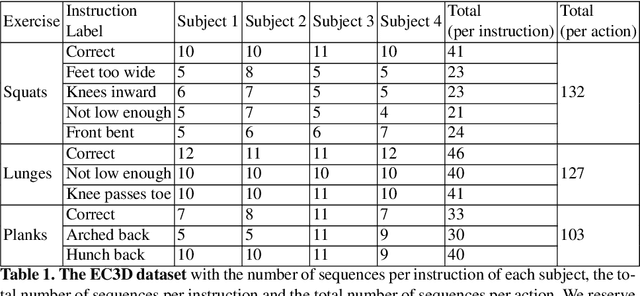
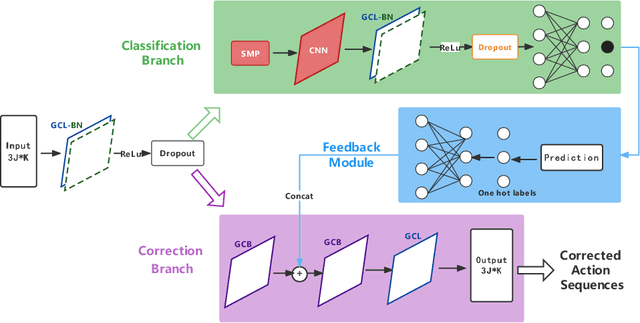
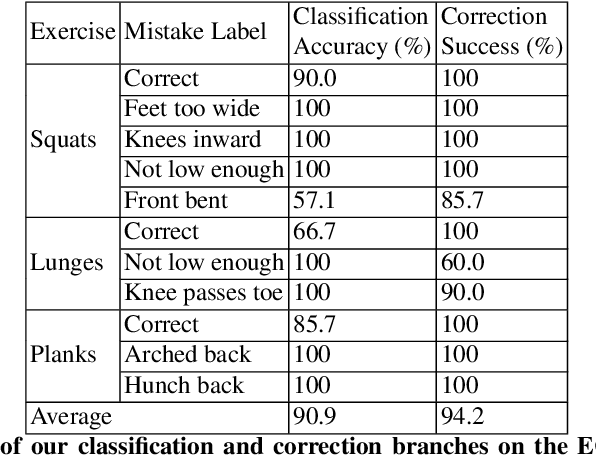
Unsupervised self-rehabilitation exercises and physical training can cause serious injuries if performed incorrectly. We introduce a learning-based framework that identifies the mistakes made by a user and proposes corrective measures for easier and safer individual training. Our framework does not rely on hard-coded, heuristic rules. Instead, it learns them from data, which facilitates its adaptation to specific user needs. To this end, we use a Graph Convolutional Network (GCN) architecture acting on the user's pose sequence to model the relationship between the body joints trajectories. To evaluate our approach, we introduce a dataset with 3 different physical exercises. Our approach yields 90.9% mistake identification accuracy and successfully corrects 94.2% of the mistakes.
Long Term Motion Prediction Using Keyposes
Dec 08, 2020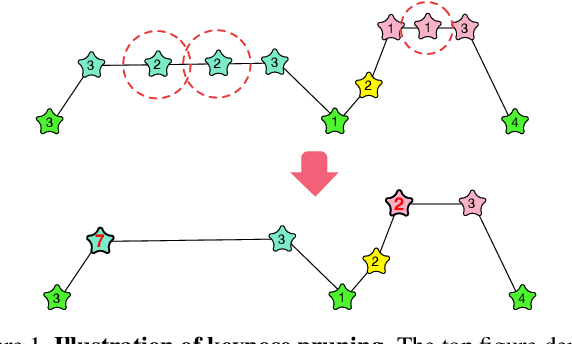
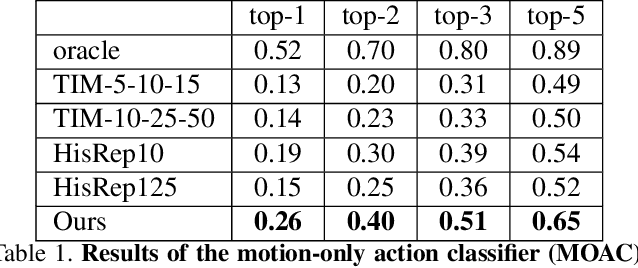
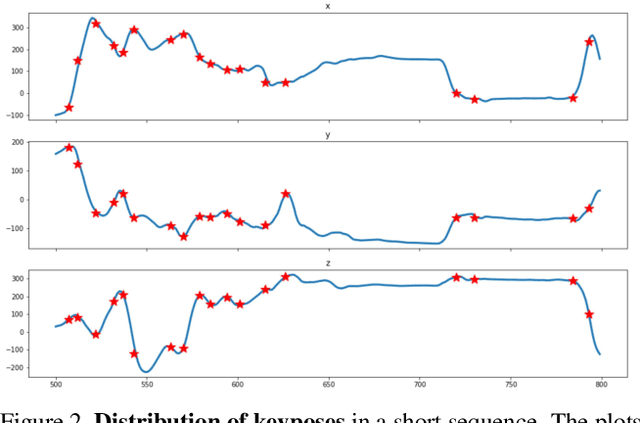
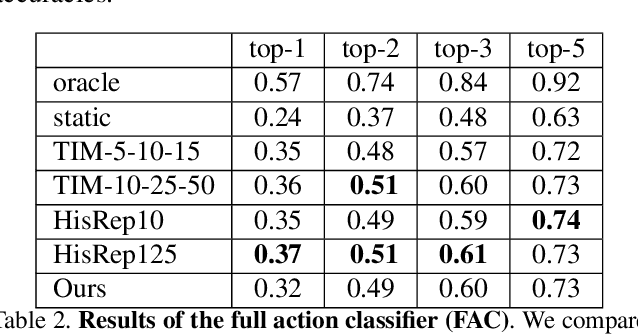
Long term human motion prediction is an essential component in safety-critical applications, such as human-robot interaction and autonomous driving. We argue that, to achieve long term forecasting, predicting human pose at every time instant is unnecessary because human motion follows patterns that are well-represented by a few essential poses in the sequence. We call such poses "keyposes", and approximate complex motions by linearly interpolating between subsequent keyposes. We show that learning the sequence of such keyposes allows us to predict very long term motion, up to 5 seconds in the future. In particular, our predictions are much more realistic and better preserve the motion dynamics than those obtained by the state-of-the-art methods. Furthermore, our approach models the future keyposes probabilistically, which, during inference, lets us generate diverse future motions via sampling.
Motion Prediction Using Temporal Inception Module
Oct 06, 2020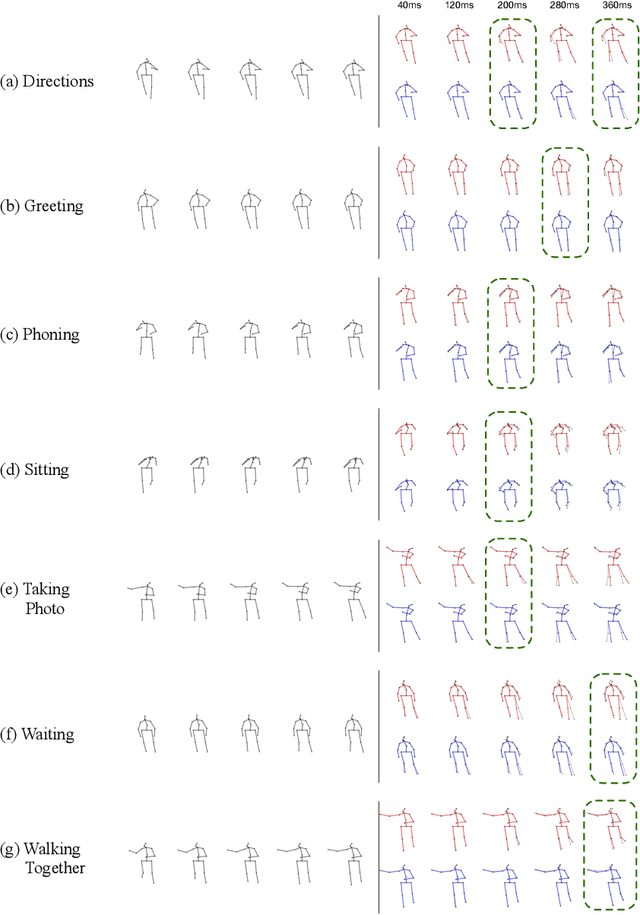
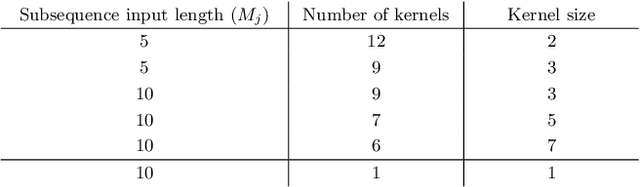
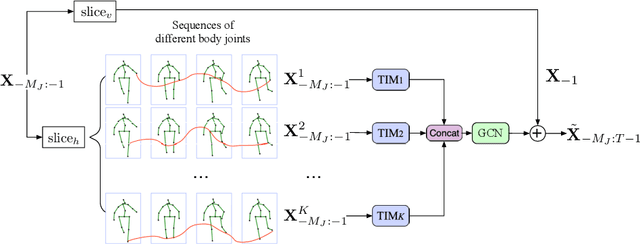

Human motion prediction is a necessary component for many applications in robotics and autonomous driving. Recent methods propose using sequence-to-sequence deep learning models to tackle this problem. However, they do not focus on exploiting different temporal scales for different length inputs. We argue that the diverse temporal scales are important as they allow us to look at the past frames with different receptive fields, which can lead to better predictions. In this paper, we propose a Temporal Inception Module (TIM) to encode human motion. Making use of TIM, our framework produces input embeddings using convolutional layers, by using different kernel sizes for different input lengths. The experimental results on standard motion prediction benchmark datasets Human3.6M and CMU motion capture dataset show that our approach consistently outperforms the state of the art methods.
ActiveMoCap: Optimized Drone Flight for Active Human Motion Capture
Dec 18, 2019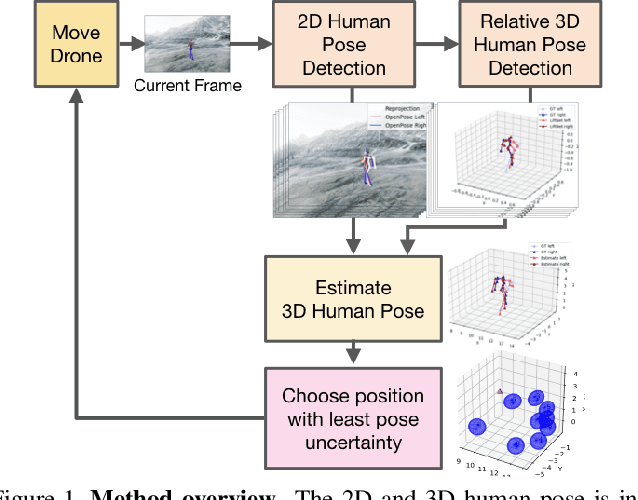

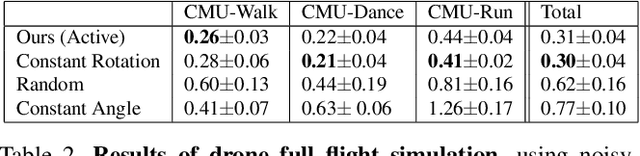
The accuracy of monocular 3D human pose estimation depends on the viewpoint from which the image is captured. While camera-equipped drones provide control over this viewpoint, automatically positioning them at the location which will yield the highest accuracy remains an open problem. This is the problem that we address in this paper. Specifically, given a short video sequence, we introduce an algorithm that predicts the where a drone should go in the future frame so as to maximize 3D human pose estimation accuracy. A key idea underlying our approach is a method to estimate the uncertainty of the 3D body pose estimates. We integrate several sources of uncertainty, originating from a deep learning based regressors and temporal smoothness. The resulting motion planner leads to improved 3D body pose estimates and outperforms or matches existing planners that are based on person following and orbiting.