 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Pretraining via Target Encoder Bootstrapping
Mar 19, 2025Object-centric representation learning has recently been successfully applied to real-world datasets. This success can be attributed to pretrained non-object-centric foundation models, whose features serve as reconstruction targets for slot attention. However, targets must remain frozen throughout the training, which sets an upper bound on the performance object-centric models can attain. Attempts to update the target encoder by bootstrapping result in large performance drops, which can be attributed to its lack of object-centric inductive biases, causing the object-centric model's encoder to drift away from representations useful as reconstruction targets. To address these limitations, we propose Object-CEntric Pretraining by Target Encoder BOotstrapping, a self-distillation setup for training object-centric models from scratch, on real-world data, for the first time ever. In OCEBO, the target encoder is updated as an exponential moving average of the object-centric model, thus explicitly being enriched with object-centric inductive biases introduced by slot attention while removing the upper bound on performance present in other models. We mitigate the slot collapse caused by random initialization of the target encoder by introducing a novel cross-view patch filtering approach that limits the supervision to sufficiently informative patches. When pretrained on 241k images from COCO, OCEBO achieves unsupervised object discovery performance comparable to that of object-centric models with frozen non-object-centric target encoders pretrained on hundreds of millions of images. The code and pretrained models are publicly available at https://github.com/djukicn/ocebo.
Failure-Proof Non-Contrastive Self-Supervised Learning
Oct 07, 2024



We identify sufficient conditions to avoid known failure modes, including representation, dimensional, cluster and intracluster collapses, occurring in non-contrastive self-supervised learning. Based on these findings, we propose a principled design for the projector and loss function. We theoretically demonstrate that this design introduces an inductive bias that promotes learning representations that are both decorrelated and clustered without explicit enforcing these properties and leading to improved generalization. To the best of our knowledge, this is the first solution that achieves robust training with respect to these failure modes while guaranteeing enhanced generalization performance in downstream tasks. We validate our theoretical findings on image datasets including SVHN, CIFAR10, CIFAR100 and ImageNet-100, and show that our solution, dubbed FALCON, outperforms existing feature decorrelation and cluster-based self-supervised learning methods in terms of generalization to clustering and linear classification tasks.
A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
Jun 23, 2024



Zero-shot classification capabilities naturally arise in models trained within a vision-language contrastive framework. Despite their classification prowess, these models struggle in dense tasks like zero-shot open-vocabulary segmentation. This deficiency is often attributed to the absence of localization cues in captions and the intertwined nature of the learning process, which encompasses both image representation learning and cross-modality alignment. To tackle these issues, we propose SimZSS, a Simple framework for open-vocabulary Zero-Shot Segmentation. The method is founded on two key principles: i) leveraging frozen vision-only models that exhibit spatial awareness while exclusively aligning the text encoder and ii) exploiting the discrete nature of text and linguistic knowledge to pinpoint local concepts within captions. By capitalizing on the quality of the visual representations, our method requires only image-caption pairs datasets and adapts to both small curated and large-scale noisy datasets. When trained on COCO Captions across 8 GPUs, SimZSS achieves state-of-the-art results on 7 out of 8 benchmark datasets in less than 15 minutes.
CrIBo: Self-Supervised Learning via Cross-Image Object-Level Bootstrapping
Oct 11, 2023



Leveraging nearest neighbor retrieval for self-supervised representation learning has proven beneficial with object-centric images. However, this approach faces limitations when applied to scene-centric datasets, where multiple objects within an image are only implicitly captured in the global representation. Such global bootstrapping can lead to undesirable entanglement of object representations. Furthermore, even object-centric datasets stand to benefit from a finer-grained bootstrapping approach. In response to these challenges, we introduce a novel Cross-Image Object-Level Bootstrapping method tailored to enhance dense visual representation learning. By employing object-level nearest neighbor bootstrapping throughout the training, CrIBo emerges as a notably strong and adequate candidate for in-context learning, leveraging nearest neighbor retrieval at test time. CrIBo shows state-of-the-art performance on the latter task while being highly competitive in more standard downstream segmentation tasks. Our code and pretrained models will be publicly available upon acceptance.
CrOC: Cross-View Online Clustering for Dense Visual Representation Learning
Mar 23, 2023



Learning dense visual representations without labels is an arduous task and more so from scene-centric data. We propose to tackle this challenging problem by proposing a Cross-view consistency objective with an Online Clustering mechanism (CrOC) to discover and segment the semantics of the views. In the absence of hand-crafted priors, the resulting method is more generalizable and does not require a cumbersome pre-processing step. More importantly, the clustering algorithm conjointly operates on the features of both views, thereby elegantly bypassing the issue of content not represented in both views and the ambiguous matching of objects from one crop to the other. We demonstrate excellent performance on linear and unsupervised segmentation transfer tasks on various datasets and similarly for video object segmentation. Our code and pre-trained models are publicly available at https://github.com/stegmuel/CrOC.
Adaptive Similarity Bootstrapping for Self-Distillation
Mar 23, 2023



Most self-supervised methods for representation learning leverage a cross-view consistency objective i.e. they maximize the representation similarity of a given image's augmented views. Recent work NNCLR goes beyond the cross-view paradigm and uses positive pairs from different images obtained via nearest neighbor bootstrapping in a contrastive setting. We empirically show that as opposed to the contrastive learning setting which relies on negative samples, incorporating nearest neighbor bootstrapping in a self-distillation scheme can lead to a performance drop or even collapse. We scrutinize the reason for this unexpected behavior and provide a solution. We propose to adaptively bootstrap neighbors based on the estimated quality of the latent space. We report consistent improvements compared to the naive bootstrapping approach and the original baselines. Our approach leads to performance improvements for various self-distillation method/backbone combinations and standard downstream tasks. Our code will be released upon acceptance.
Global-Local Self-Distillation for Visual Representation Learning
Jul 29, 2022
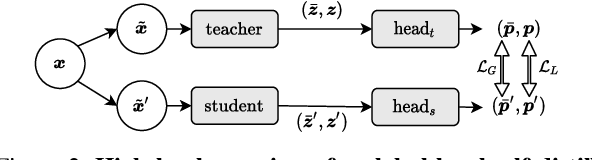
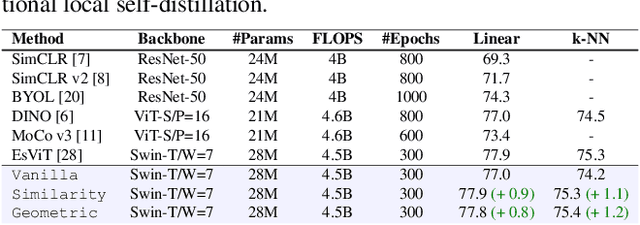

The downstream accuracy of self-supervised methods is tightly linked to the proxy task solved during training and the quality of the gradients extracted from it. Richer and more meaningful gradients updates are key to allow self-supervised methods to learn better and in a more efficient manner. In a typical self-distillation framework, the representation of two augmented images are enforced to be coherent at the global level. Nonetheless, incorporating local cues in the proxy task can be beneficial and improve the model accuracy on downstream tasks. This leads to a dual objective in which, on the one hand, coherence between global-representations is enforced and on the other, coherence between local-representations is enforced. Unfortunately, an exact correspondence mapping between two sets of local-representations does not exist making the task of matching local-representations from one augmentation to another non-trivial. We propose to leverage the spatial information in the input images to obtain geometric matchings and compare this geometric approach against previous methods based on similarity matchings. Our study shows that not only 1) geometric matchings perform better than similarity based matchings in low-data regimes but also 2) that similarity based matchings are highly hurtful in low-data regimes compared to the vanilla baseline without local self-distillation. The code will be released upon acceptance.
Motion Prediction Using Temporal Inception Module
Oct 06, 2020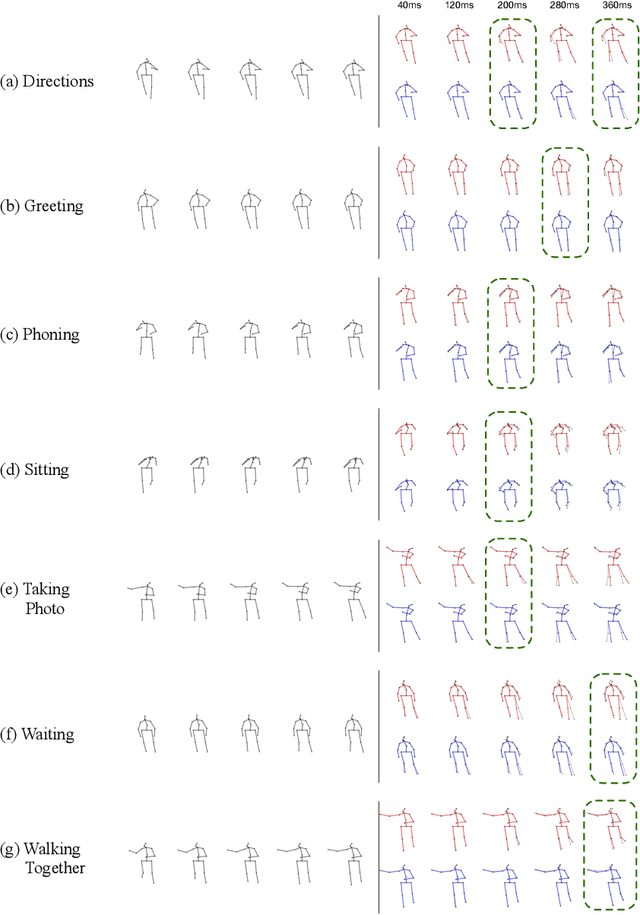
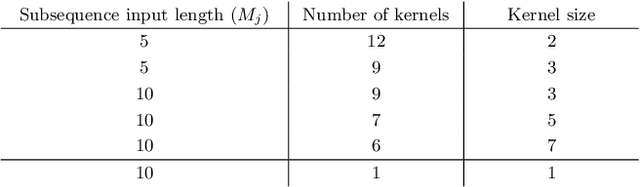
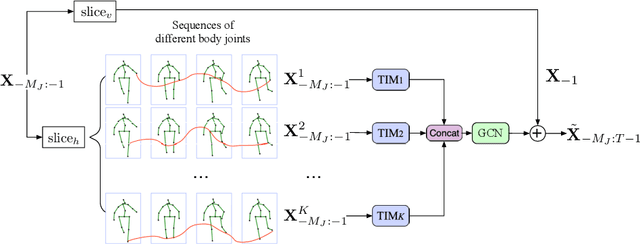

Human motion prediction is a necessary component for many applications in robotics and autonomous driving. Recent methods propose using sequence-to-sequence deep learning models to tackle this problem. However, they do not focus on exploiting different temporal scales for different length inputs. We argue that the diverse temporal scales are important as they allow us to look at the past frames with different receptive fields, which can lead to better predictions. In this paper, we propose a Temporal Inception Module (TIM) to encode human motion. Making use of TIM, our framework produces input embeddings using convolutional layers, by using different kernel sizes for different input lengths. The experimental results on standard motion prediction benchmark datasets Human3.6M and CMU motion capture dataset show that our approach consistently outperforms the state of the art methods.