 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline library learning in human visual puzzle solving
Mar 24, 2026When learning a novel complex task, people often form efficient reusable abstractions that simplify future work, despite uncertainty about the future. We study this process in a visual puzzle task where participants define and reuse helpers -- intermediate constructions that capture repeating structure. In an online experiment, participants solved puzzles of increasing difficulty. Early on, they created many helpers, favouring completeness over efficiency. With experience, helper use became more selective and efficient, reflecting sensitivity to reuse and cost. Access to helpers enabled participants to solve puzzles that were otherwise difficult or impossible. Computational modelling shows that human decision times and number of operations used to complete a puzzle increase with search space estimated by a program induction model with library learning. In contrast, raw program length predicts failure but not effort. Together, these results point to online library learning as a core mechanism in human problem solving, allowing people to flexibly build, refine, and reuse abstractions as task demands grow.
OrigamiBench: An Interactive Environment to Synthesize Flat-Foldable Origamis
Mar 17, 2026Building AI systems that can plan, act, and create in the physical world requires more than pattern recognition. Such systems must understand the causal mechanisms and constraints governing physical processes in order to guide sequential decisions. This capability relies on internal representations, analogous to an internal language model, that relate observations, actions, and resulting environmental changes. However, many existing benchmarks treat visual perception and programmatic reasoning as separate problems, focusing either on visual recognition or on symbolic tasks. The domain of origami provides a natural testbed that integrates these modalities. Constructing shapes through folding operations requires visual perception, reasoning about geometric and physical constraints, and sequential planning, while remaining sufficiently structured for systematic evaluation. We introduce OrigamiBench, an interactive benchmark in which models iteratively propose folds and receive feedback on physical validity and similarity to a target configuration. Experiments with modern vision-language models show that scaling model size alone does not reliably produce causal reasoning about physical transformations. Models fail to generate coherent multi-step folding strategies, suggesting that visual and language representations remain weakly integrated.
Power Term Polynomial Algebra for Boolean Logic
Mar 14, 2026We introduce power term polynomial algebra, a representation language for Boolean formulae designed to bridge conjunctive normal form (CNF) and algebraic normal form (ANF). The language is motivated by the tiling mismatch between these representations: direct CNF<->ANF conversion may cause exponential blowup unless formulas are decomposed into smaller fragments, typically through auxiliary variables and side constraints. In contrast, our framework addresses this mismatch within the representation itself, compactly encoding structured families of monomials while representing CNF clauses directly, thereby avoiding auxiliary variables and constraints at the abstraction level. We formalize the language through power terms and power term polynomials, define their semantics, and show that they admit algebraic operations corresponding to Boolean polynomial addition and multiplication. We prove several key properties of the language: disjunctive clauses admit compact canonical representations; power terms support local shortening and expansion rewrite rules; and products of atomic terms can be systematically rewritten within the language. Together, these results yield a symbolic calculus that enables direct manipulation of formulas without expanding them into ordinary ANF. The resulting framework provides a new intermediate representation and rewriting calculus that bridges clause-based and algebraic reasoning and suggests new directions for structure-aware CNF<->ANF conversion and hybrid reasoning methods.
Failure-Proof Non-Contrastive Self-Supervised Learning
Oct 07, 2024



We identify sufficient conditions to avoid known failure modes, including representation, dimensional, cluster and intracluster collapses, occurring in non-contrastive self-supervised learning. Based on these findings, we propose a principled design for the projector and loss function. We theoretically demonstrate that this design introduces an inductive bias that promotes learning representations that are both decorrelated and clustered without explicit enforcing these properties and leading to improved generalization. To the best of our knowledge, this is the first solution that achieves robust training with respect to these failure modes while guaranteeing enhanced generalization performance in downstream tasks. We validate our theoretical findings on image datasets including SVHN, CIFAR10, CIFAR100 and ImageNet-100, and show that our solution, dubbed FALCON, outperforms existing feature decorrelation and cluster-based self-supervised learning methods in terms of generalization to clustering and linear classification tasks.
EXPLAIN, AGREE, LEARN: Scaling Learning for Neural Probabilistic Logic
Aug 15, 2024



Neural probabilistic logic systems follow the neuro-symbolic (NeSy) paradigm by combining the perceptive and learning capabilities of neural networks with the robustness of probabilistic logic. Learning corresponds to likelihood optimization of the neural networks. However, to obtain the likelihood exactly, expensive probabilistic logic inference is required. To scale learning to more complex systems, we therefore propose to instead optimize a sampling based objective. We prove that the objective has a bounded error with respect to the likelihood, which vanishes when increasing the sample count. Furthermore, the error vanishes faster by exploiting a new concept of sample diversity. We then develop the EXPLAIN, AGREE, LEARN (EXAL) method that uses this objective. EXPLAIN samples explanations for the data. AGREE reweighs each explanation in concordance with the neural component. LEARN uses the reweighed explanations as a signal for learning. In contrast to previous NeSy methods, EXAL can scale to larger problem sizes while retaining theoretical guarantees on the error. Experimentally, our theoretical claims are verified and EXAL outperforms recent NeSy methods when scaling up the MNIST addition and Warcraft pathfinding problems.
(Deep) Generative Geodesics
Jul 15, 2024In this work, we propose to study the global geometrical properties of generative models. We introduce a new Riemannian metric to assess the similarity between any two data points. Importantly, our metric is agnostic to the parametrization of the generative model and requires only the evaluation of its data likelihood. Moreover, the metric leads to the conceptual definition of generative distances and generative geodesics, whose computation can be done efficiently in the data space. Their approximations are proven to converge to their true values under mild conditions. We showcase three proof-of-concept applications of this global metric, including clustering, data visualization, and data interpolation, thus providing new tools to support the geometrical understanding of generative models.
A Bayesian Unification of Self-Supervised Clustering and Energy-Based Models
Dec 30, 2023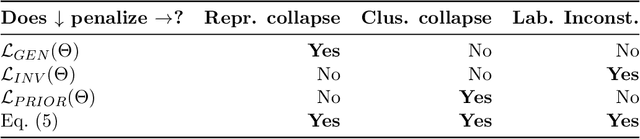
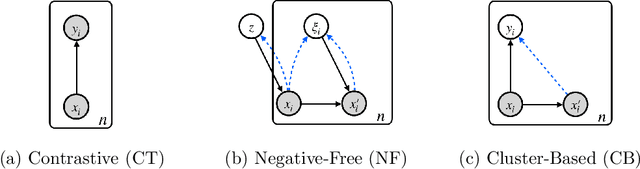
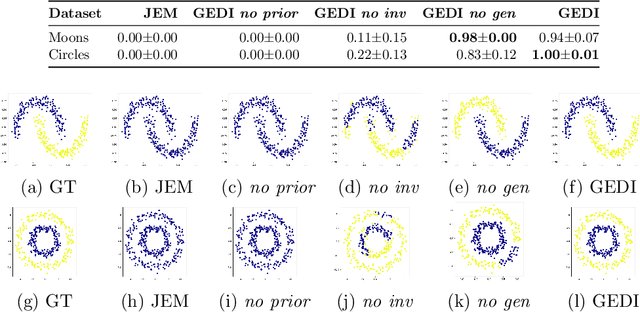
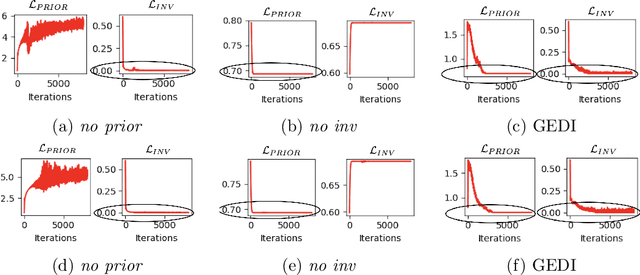
Self-supervised learning is a popular and powerful method for utilizing large amounts of unlabeled data, for which a wide variety of training objectives have been proposed in the literature. In this study, we perform a Bayesian analysis of state-of-the-art self-supervised learning objectives, elucidating the underlying probabilistic graphical models in each class and presenting a standardized methodology for their derivation from first principles. The analysis also indicates a natural means of integrating self-supervised learning with likelihood-based generative models. We instantiate this concept within the realm of cluster-based self-supervised learning and energy models, introducing a novel lower bound which is proven to reliably penalize the most important failure modes. Furthermore, this newly proposed lower bound enables the training of a standard backbone architecture without the necessity for asymmetric elements such as stop gradients, momentum encoders, or specialized clustering layers - typically introduced to avoid learning trivial solutions. Our theoretical findings are substantiated through experiments on synthetic and real-world data, including SVHN, CIFAR10, and CIFAR100, thus showing that our objective function allows to outperform existing self-supervised learning strategies in terms of clustering, generation and out-of-distribution detection performance by a wide margin. We also demonstrate that GEDI can be integrated into a neural-symbolic framework to mitigate the reasoning shortcut problem and to learn higher quality symbolic representations thanks to the enhanced classification performance.
Differentiable Sampling of Categorical Distributions Using the CatLog-Derivative Trick
Nov 21, 2023



Categorical random variables can faithfully represent the discrete and uncertain aspects of data as part of a discrete latent variable model. Learning in such models necessitates taking gradients with respect to the parameters of the categorical probability distributions, which is often intractable due to their combinatorial nature. A popular technique to estimate these otherwise intractable gradients is the Log-Derivative trick. This trick forms the basis of the well-known REINFORCE gradient estimator and its many extensions. While the Log-Derivative trick allows us to differentiate through samples drawn from categorical distributions, it does not take into account the discrete nature of the distribution itself. Our first contribution addresses this shortcoming by introducing the CatLog-Derivative trick - a variation of the Log-Derivative trick tailored towards categorical distributions. Secondly, we use the CatLog-Derivative trick to introduce IndeCateR, a novel and unbiased gradient estimator for the important case of products of independent categorical distributions with provably lower variance than REINFORCE. Thirdly, we empirically show that IndeCateR can be efficiently implemented and that its gradient estimates have significantly lower bias and variance for the same number of samples compared to the state of the art.
The Triad of Failure Modes and a Possible Way Out
Sep 27, 2023



We present a novel objective function for cluster-based self-supervised learning (SSL) that is designed to circumvent the triad of failure modes, namely representation collapse, cluster collapse, and the problem of invariance to permutations of cluster assignments. This objective consists of three key components: (i) A generative term that penalizes representation collapse, (ii) a term that promotes invariance to data augmentations, thereby addressing the issue of label permutations and (ii) a uniformity term that penalizes cluster collapse. Additionally, our proposed objective possesses two notable advantages. Firstly, it can be interpreted from a Bayesian perspective as a lower bound on the data log-likelihood. Secondly, it enables the training of a standard backbone architecture without the need for asymmetric elements like stop gradients, momentum encoders, or specialized clustering layers. Due to its simplicity and theoretical foundation, our proposed objective is well-suited for optimization. Experiments on both toy and real world data demonstrate its effectiveness
Learning Symbolic Representations Through Joint GEnerative and DIscriminative Training
Apr 22, 2023



We introduce GEDI, a Bayesian framework that combines existing self-supervised learning objectives with likelihood-based generative models. This framework leverages the benefits of both GEnerative and DIscriminative approaches, resulting in improved symbolic representations over standalone solutions. Additionally, GEDI can be easily integrated and trained jointly with existing neuro-symbolic frameworks without the need for additional supervision or costly pre-training steps. We demonstrate through experiments on real-world data, including SVHN, CIFAR10, and CIFAR100, that GEDI outperforms existing self-supervised learning strategies in terms of clustering performance by a significant margin. The symbolic component further allows it to leverage knowledge in the form of logical constraints to improve performance in the small data regime.
* ICLR 2023 Workshop NeSy-GeMs. arXiv admin note: substantial text overlap with arXiv:2212.13425