 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning with Local Contrastive Loss for Detection and Semantic Segmentation
Jul 10, 2022
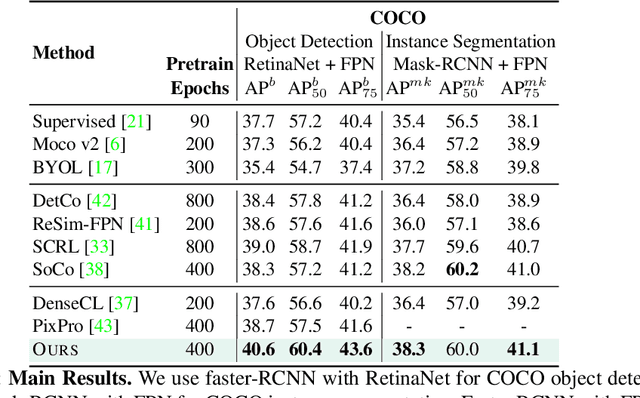
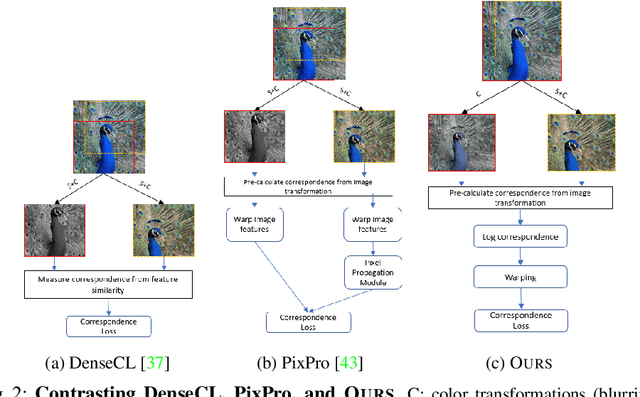
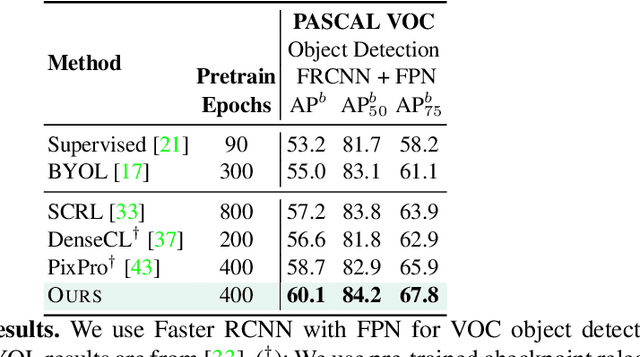
We present a self-supervised learning (SSL) method suitable for semi-global tasks such as object detection and semantic segmentation. We enforce local consistency between self-learned features, representing corresponding image locations of transformed versions of the same image, by minimizing a pixel-level local contrastive (LC) loss during training. LC-loss can be added to existing self-supervised learning methods with minimal overhead. We evaluate our SSL approach on two downstream tasks -- object detection and semantic segmentation, using COCO, PASCAL VOC, and CityScapes datasets. Our method outperforms the existing state-of-the-art SSL approaches by 1.9% on COCO object detection, 1.4% on PASCAL VOC detection, and 0.6% on CityScapes segmentation.
Generalized Pose-and-Scale Estimation using 4-Point Congruence Constraints
Nov 27, 2020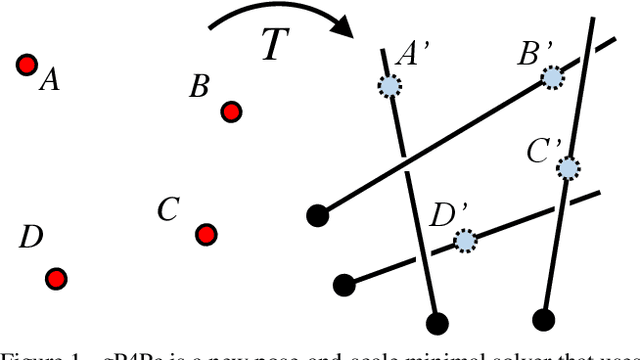
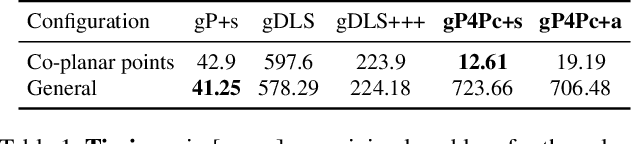
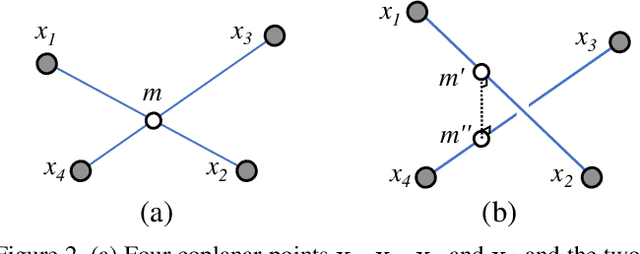

We present gP4Pc, a new method for computing the absolute pose of a generalized camera with unknown internal scale from four corresponding 3D point-and-ray pairs. Unlike most pose-and-scale methods, gP4Pc is based on constraints arising from the congruence of shapes defined by two sets of four points related by an unknown similarity transformation. By choosing a novel parametrization for the problem, we derive a system of four quadratic equations in four scalar variables. The variables represent the distances of 3D points along the rays from the camera centers. After solving this system via Groebner basis-based automatic polynomial solvers, we compute the similarity transformation using an efficient 3D point-point alignment method. We also propose a specialized variant of our solver for the case of coplanar points, which is computationally very efficient and about 3x faster than the fastest existing solver. Our experiments on real and synthetic datasets, demonstrate that gP4Pc is among the fastest methods in terms of total running time when used within a RANSAC framework, while achieving competitive numerical stability, accuracy, and robustness to noise.
Deep Depth Prior for Multi-View Stereo
Jan 21, 2020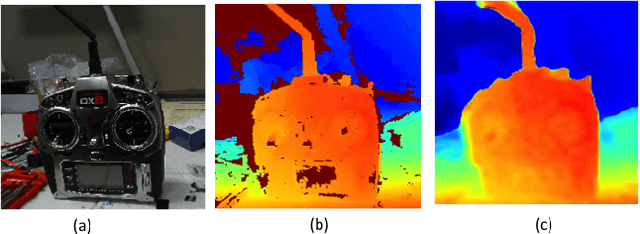
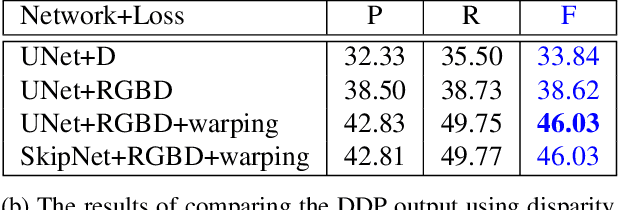
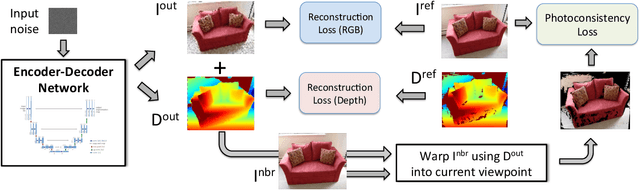
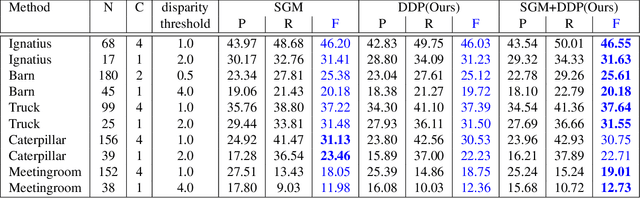
It was recently shown that the structure of convolutional neural networks induces a strong prior favoring natural color images, a phenomena referred to as a deep image prior (DIP), which can be an effective regularizer in inverse problems such as image denoising, inpainting etc. In this paper, we investigate a similar idea for depth images, which we call a deep depth prior. Specifically, given a color image and a noisy and incomplete target depth map from the same viewpoint, we optimize a randomly initialized CNN model to reconstruct an RGB-D image where the depth channel gets restored by virtue of using the network structure as a prior. We propose using deep depth priors for refining and inpainting noisy depth maps within a multi-view stereo pipeline. We optimize the network parameters to minimize two losses 1) a RGB-D reconstruction loss based on the noisy depth map and 2) a multi-view photoconsistency-based loss, which is computed using images from a geometrically calibrated camera from nearby viewpoints. Our quantitative and qualitative evaluation shows that our refined depth maps are more accurate and complete, and after fusion, produces dense 3D models of higher quality.
ActiveMoCap: Optimized Drone Flight for Active Human Motion Capture
Dec 18, 2019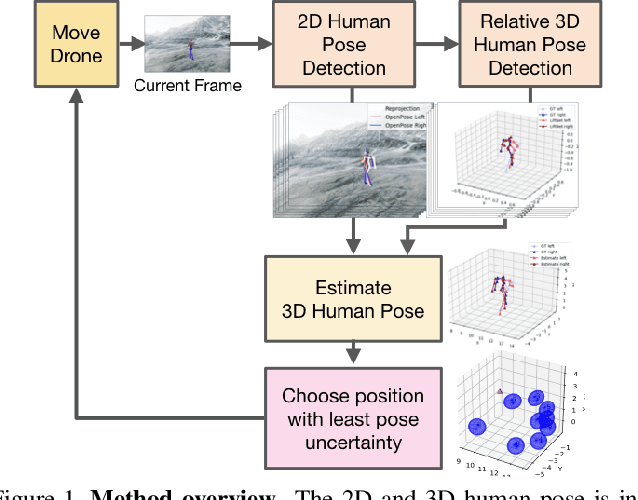

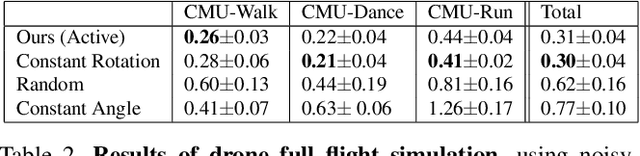
The accuracy of monocular 3D human pose estimation depends on the viewpoint from which the image is captured. While camera-equipped drones provide control over this viewpoint, automatically positioning them at the location which will yield the highest accuracy remains an open problem. This is the problem that we address in this paper. Specifically, given a short video sequence, we introduce an algorithm that predicts the where a drone should go in the future frame so as to maximize 3D human pose estimation accuracy. A key idea underlying our approach is a method to estimate the uncertainty of the 3D body pose estimates. We integrate several sources of uncertainty, originating from a deep learning based regressors and temporal smoothness. The resulting motion planner leads to improved 3D body pose estimates and outperforms or matches existing planners that are based on person following and orbiting.
Privacy-Preserving Action Recognition using Coded Aperture Videos
Apr 16, 2019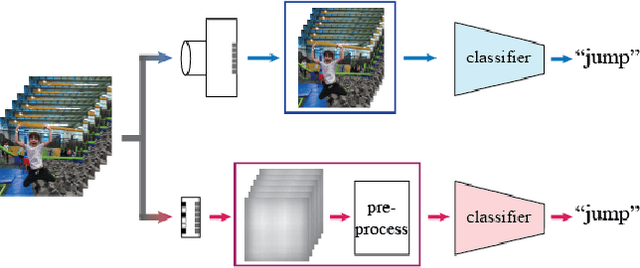
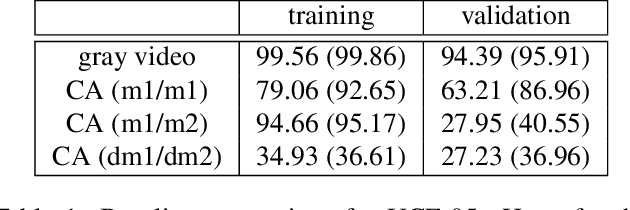
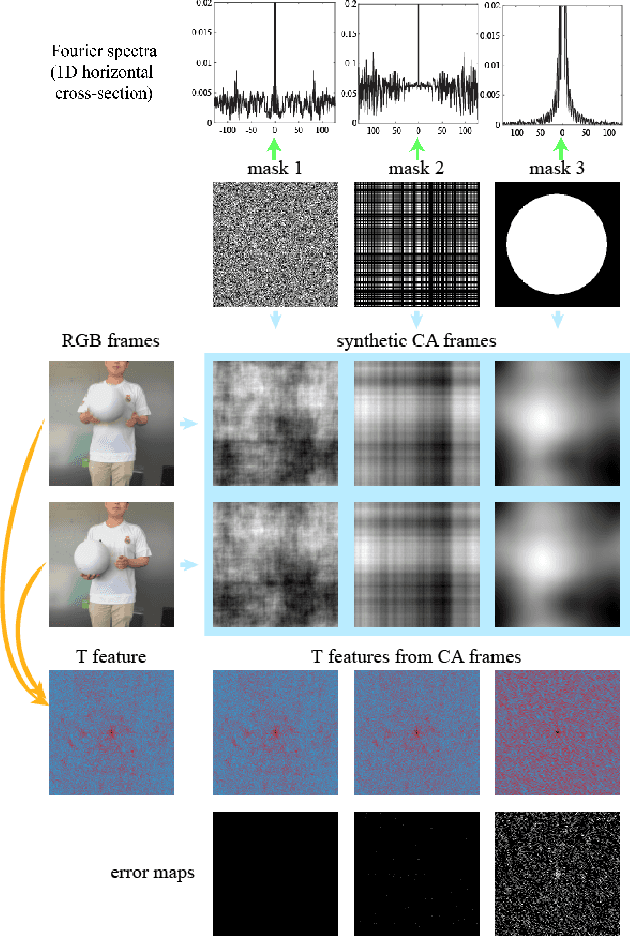
The risk of unauthorized remote access of streaming video from networked cameras underlines the need for stronger privacy safeguards. We propose a lens-free coded aperture camera system for human action recognition that is privacy-preserving. While coded aperture systems exist, we believe ours is the first system designed for action recognition without the need for image restoration as an intermediate step. Action recognition is done using a deep network that takes in as input, non-invertible motion features between pairs of frames computed using phase correlation and log-polar transformation. Phase correlation encodes translation while the log polar transformation encodes in-plane rotation and scaling. We show that the translation features are independent of the coded aperture design, as long as its spectral response within the bandwidth has no zeros. Stacking motion features computed on frames at multiple different strides in the video can improve accuracy. Preliminary results on simulated data based on a subset of the UCF and NTU datasets are promising. We also describe our prototype lens-free coded aperture camera system, and results for real captured videos are mixed.
Submodular Trajectory Optimization for Aerial 3D Scanning
Aug 04, 2017
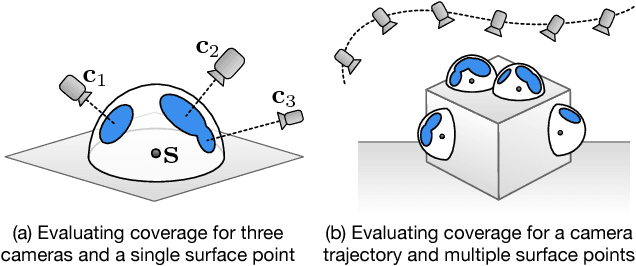
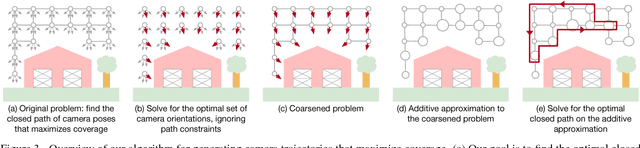

Drones equipped with cameras are emerging as a powerful tool for large-scale aerial 3D scanning, but existing automatic flight planners do not exploit all available information about the scene, and can therefore produce inaccurate and incomplete 3D models. We present an automatic method to generate drone trajectories, such that the imagery acquired during the flight will later produce a high-fidelity 3D model. Our method uses a coarse estimate of the scene geometry to plan camera trajectories that: (1) cover the scene as thoroughly as possible; (2) encourage observations of scene geometry from a diverse set of viewing angles; (3) avoid obstacles; and (4) respect a user-specified flight time budget. Our method relies on a mathematical model of scene coverage that exhibits an intuitive diminishing returns property known as submodularity. We leverage this property extensively to design a trajectory planning algorithm that reasons globally about the non-additive coverage reward obtained across a trajectory, jointly with the cost of traveling between views. We evaluate our method by using it to scan three large outdoor scenes, and we perform a quantitative evaluation using a photorealistic video game simulator.
Multiview Rectification of Folded Documents
Jun 01, 2016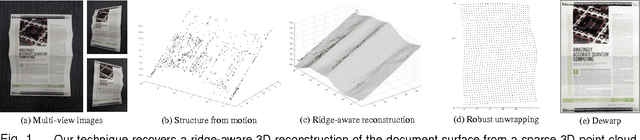


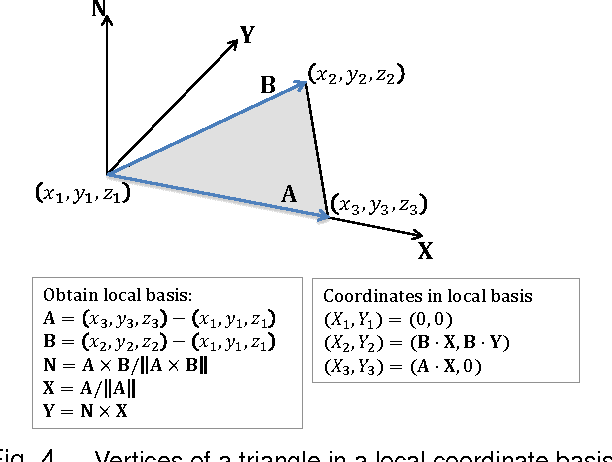
Digitally unwrapping images of paper sheets is crucial for accurate document scanning and text recognition. This paper presents a method for automatically rectifying curved or folded paper sheets from a few images captured from multiple viewpoints. Prior methods either need expensive 3D scanners or model deformable surfaces using over-simplified parametric representations. In contrast, our method uses regular images and is based on general developable surface models that can represent a wide variety of paper deformations. Our main contribution is a new robust rectification method based on ridge-aware 3D reconstruction of a paper sheet and unwrapping the reconstructed surface using properties of developable surfaces via $\ell_1$ conformal mapping. We present results on several examples including book pages, folded letters and shopping receipts.
Real-time Image-based 6-DOF Localization in Large-Scale Environments
Mar 27, 2012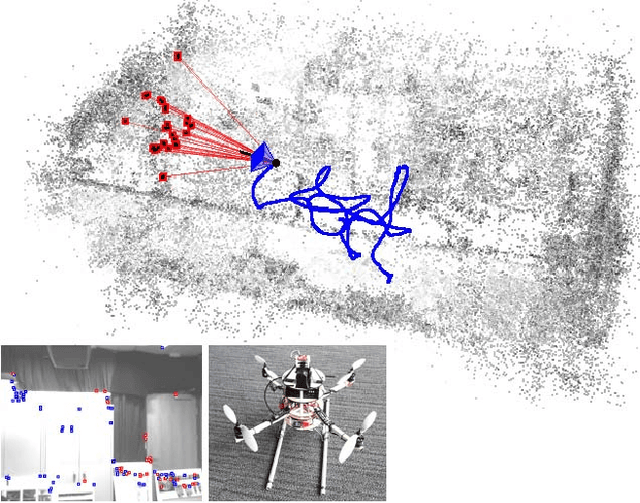
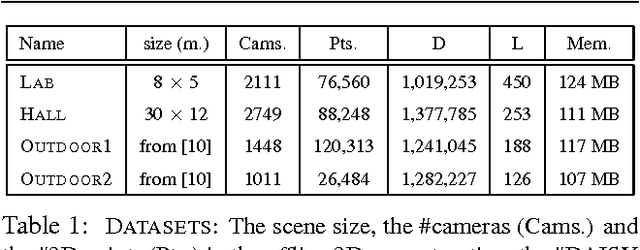
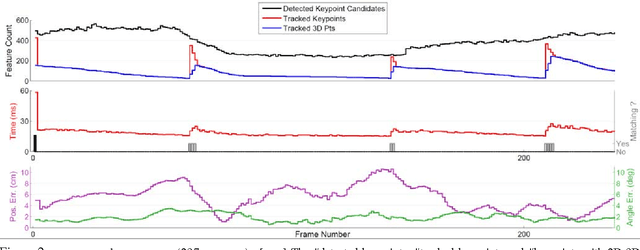
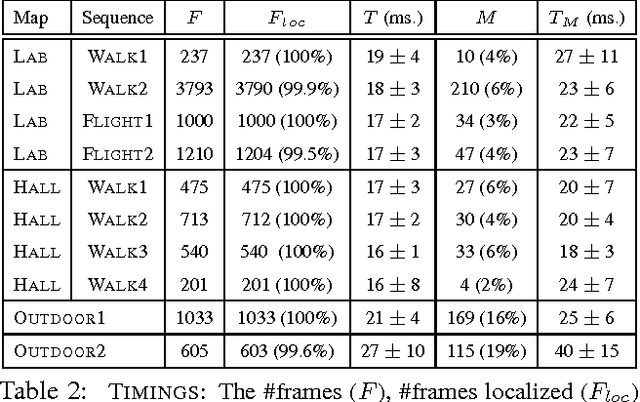
We present a real-time approach for image-based localization within large scenes that have been reconstructed offline using structure from motion (Sfm). From monocular video, our method continuously computes a precise 6-DOF camera pose, by efficiently tracking natural features and matching them to 3D points in the Sfm point cloud. Our main contribution lies in efficiently interleaving a fast keypoint tracker that uses inexpensive binary feature descriptors with a new approach for direct 2D-to-3D matching. The 2D-to-3D matching avoids the need for online extraction of scale-invariant features. Instead, offline we construct an indexed database containing multiple DAISY descriptors per 3D point extracted at multiple scales. The key to the efficiency of our method lies in invoking DAISY descriptor extraction and matching sparingly during localization, and in distributing this computation over a window of successive frames. This enables the algorithm to run in real-time, without fluctuations in the latency over long durations. We evaluate the method in large indoor and outdoor scenes. Our algorithm runs at over 30 Hz on a laptop and at 12 Hz on a low-power, mobile computer suitable for onboard computation on a quadrotor micro aerial vehicle.