 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation
Mar 22, 2023



We present a technique for segmenting real and AI-generated images using latent diffusion models (LDMs) trained on internet-scale datasets. First, we show that the latent space of LDMs (z-space) is a better input representation compared to other feature representations like RGB images or CLIP encodings for text-based image segmentation. By training the segmentation models on the latent z-space, which creates a compressed representation across several domains like different forms of art, cartoons, illustrations, and photographs, we are also able to bridge the domain gap between real and AI-generated images. We show that the internal features of LDMs contain rich semantic information and present a technique in the form of LD-ZNet to further boost the performance of text-based segmentation. Overall, we show up to 6% improvement over standard baselines for text-to-image segmentation on natural images. For AI-generated imagery, we show close to 20% improvement compared to state-of-the-art techniques.
All About Knowledge Graphs for Actions
Aug 28, 2020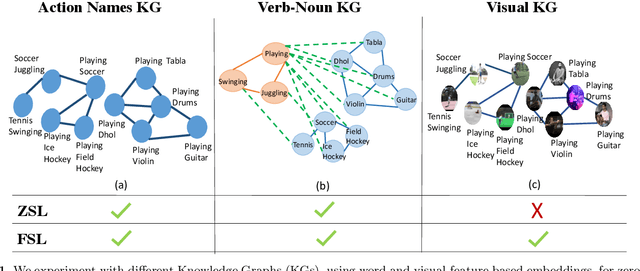
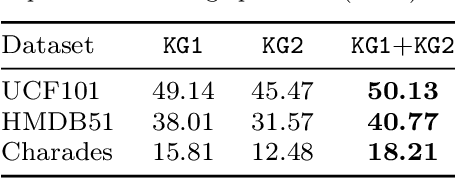
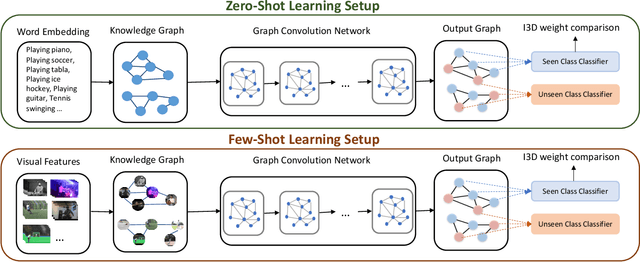
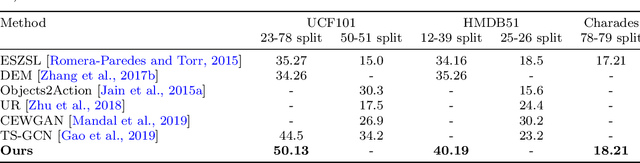
Current action recognition systems require large amounts of training data for recognizing an action. Recent works have explored the paradigm of zero-shot and few-shot learning to learn classifiers for unseen categories or categories with few labels. Following similar paradigms in object recognition, these approaches utilize external sources of knowledge (eg. knowledge graphs from language domains). However, unlike objects, it is unclear what is the best knowledge representation for actions. In this paper, we intend to gain a better understanding of knowledge graphs (KGs) that can be utilized for zero-shot and few-shot action recognition. In particular, we study three different construction mechanisms for KGs: action embeddings, action-object embeddings, visual embeddings. We present extensive analysis of the impact of different KGs in different experimental setups. Finally, to enable a systematic study of zero-shot and few-shot approaches, we propose an improved evaluation paradigm based on UCF101, HMDB51, and Charades datasets for knowledge transfer from models trained on Kinetics.
Deep Depth Prior for Multi-View Stereo
Jan 21, 2020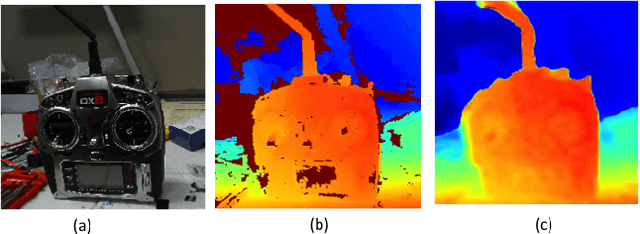
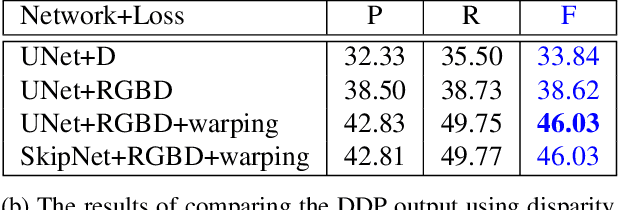
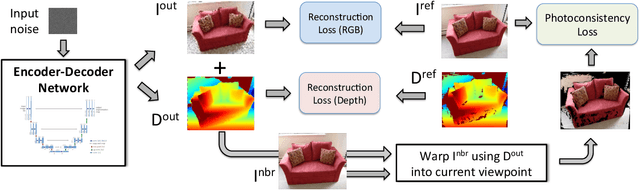
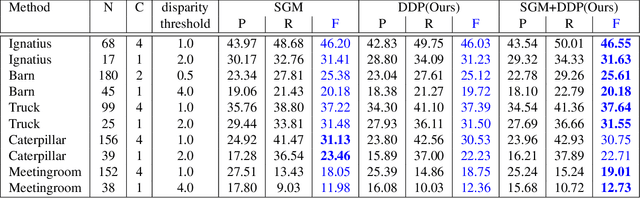
It was recently shown that the structure of convolutional neural networks induces a strong prior favoring natural color images, a phenomena referred to as a deep image prior (DIP), which can be an effective regularizer in inverse problems such as image denoising, inpainting etc. In this paper, we investigate a similar idea for depth images, which we call a deep depth prior. Specifically, given a color image and a noisy and incomplete target depth map from the same viewpoint, we optimize a randomly initialized CNN model to reconstruct an RGB-D image where the depth channel gets restored by virtue of using the network structure as a prior. We propose using deep depth priors for refining and inpainting noisy depth maps within a multi-view stereo pipeline. We optimize the network parameters to minimize two losses 1) a RGB-D reconstruction loss based on the noisy depth map and 2) a multi-view photoconsistency-based loss, which is computed using images from a geometrically calibrated camera from nearby viewpoints. Our quantitative and qualitative evaluation shows that our refined depth maps are more accurate and complete, and after fusion, produces dense 3D models of higher quality.
Stacked Spatio-Temporal Graph Convolutional Networks for Action Segmentation
Dec 12, 2018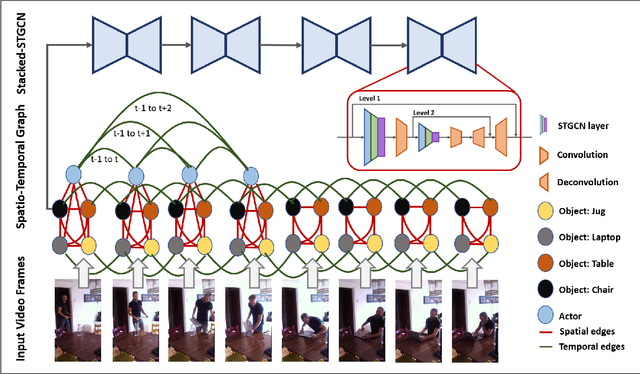

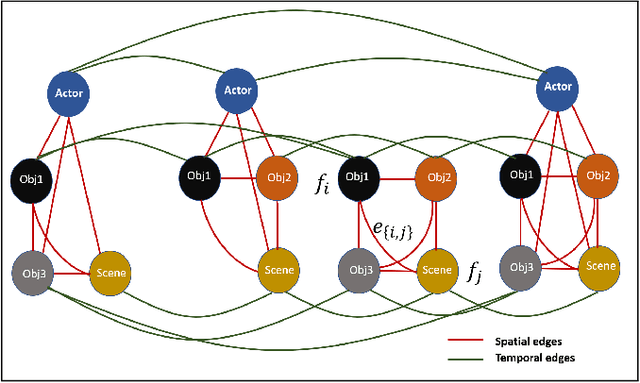

We propose novel Stacked Spatio-Temporal Graph Convolutional Networks (Stacked-STGCN) for action segmentation, i.e., predicting and localizing a sequence of actions over long videos. We extend the Spatio-Temporal Graph Convolutional Network (STGCN) originally proposed for skeleton-based action recognition to enable nodes with different characteristics (e.g., scene, actor, object, action, etc.), feature descriptors with varied lengths, and arbitrary temporal edge connections to account for large graph deformation commonly associated with complex activities. We further introduce the stacked hourglass architecture to STGCN to leverage the advantages of an encoder-decoder design for improved generalization performance and localization accuracy. We explore various descriptors such as frame-level VGG, segment-level I3D, RCNN-based object, etc. as node descriptors to enable action segmentation based on joint inference over comprehensive contextual information. We show results on CAD120 (which provides pre-computed node features and edge weights for fair performance comparison across algorithms) as well as a more complex real-world activity dataset, Charades. Our Stacked-STGCN in general achieves 4.0% performance improvement over the best reported results in F1 score on CAD120 and 1.3% in mAP on Charades using VGG features.
Stacked U-Nets: A No-Frills Approach to Natural Image Segmentation
Apr 27, 2018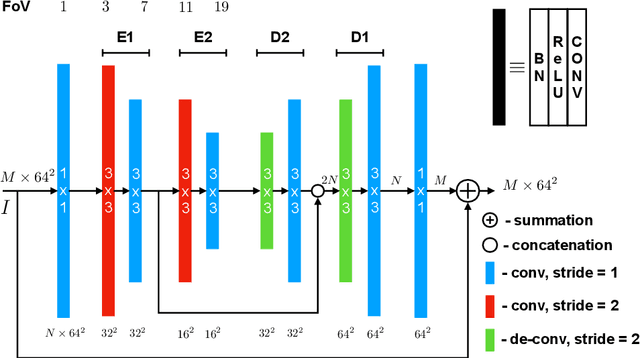
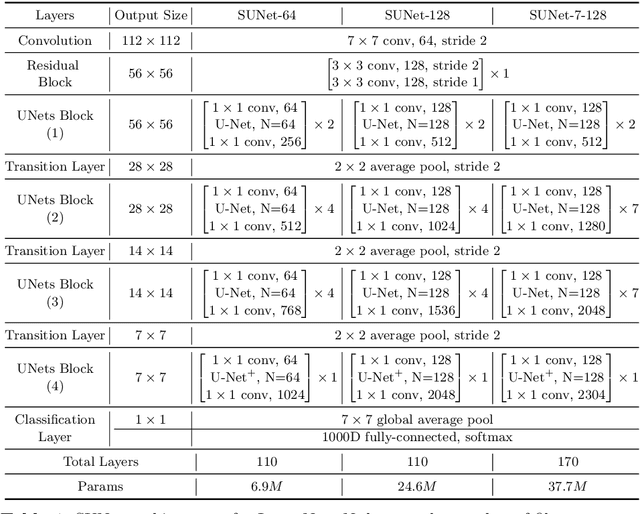
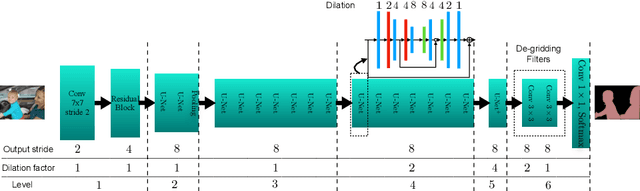
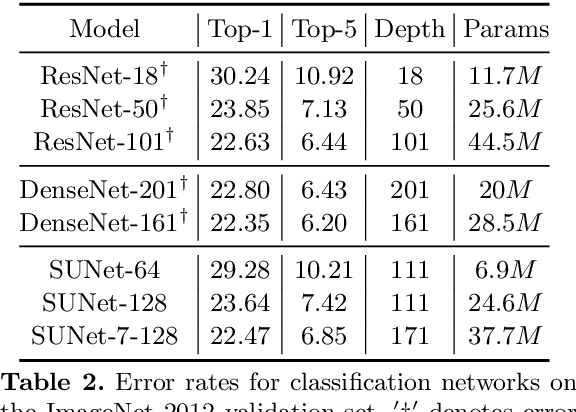
Many imaging tasks require global information about all pixels in an image. Conventional bottom-up classification networks globalize information by decreasing resolution; features are pooled and downsampled into a single output. But for semantic segmentation and object detection tasks, a network must provide higher-resolution pixel-level outputs. To globalize information while preserving resolution, many researchers propose the inclusion of sophisticated auxiliary blocks, but these come at the cost of a considerable increase in network size and computational cost. This paper proposes stacked u-nets (SUNets), which iteratively combine features from different resolution scales while maintaining resolution. SUNets leverage the information globalization power of u-nets in a deeper network architectures that is capable of handling the complexity of natural images. SUNets perform extremely well on semantic segmentation tasks using a small number of parameters.