 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll About Knowledge Graphs for Actions
Paper and Code
Aug 28, 2020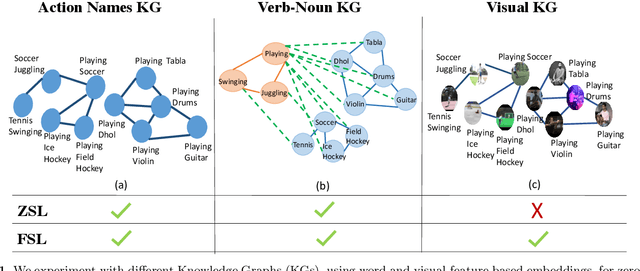
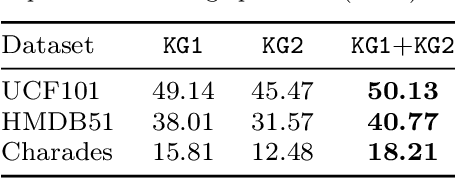
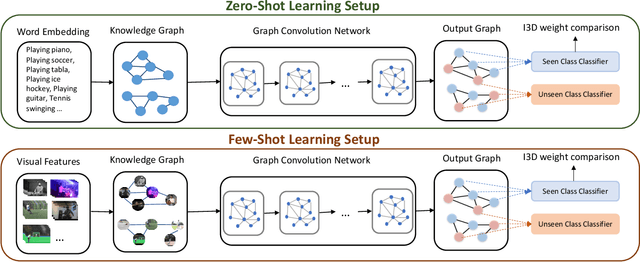
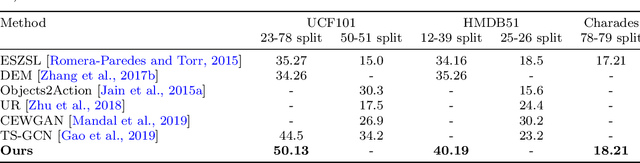
Current action recognition systems require large amounts of training data for recognizing an action. Recent works have explored the paradigm of zero-shot and few-shot learning to learn classifiers for unseen categories or categories with few labels. Following similar paradigms in object recognition, these approaches utilize external sources of knowledge (eg. knowledge graphs from language domains). However, unlike objects, it is unclear what is the best knowledge representation for actions. In this paper, we intend to gain a better understanding of knowledge graphs (KGs) that can be utilized for zero-shot and few-shot action recognition. In particular, we study three different construction mechanisms for KGs: action embeddings, action-object embeddings, visual embeddings. We present extensive analysis of the impact of different KGs in different experimental setups. Finally, to enable a systematic study of zero-shot and few-shot approaches, we propose an improved evaluation paradigm based on UCF101, HMDB51, and Charades datasets for knowledge transfer from models trained on Kinetics.