 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation
Mar 22, 2023



We present a technique for segmenting real and AI-generated images using latent diffusion models (LDMs) trained on internet-scale datasets. First, we show that the latent space of LDMs (z-space) is a better input representation compared to other feature representations like RGB images or CLIP encodings for text-based image segmentation. By training the segmentation models on the latent z-space, which creates a compressed representation across several domains like different forms of art, cartoons, illustrations, and photographs, we are also able to bridge the domain gap between real and AI-generated images. We show that the internal features of LDMs contain rich semantic information and present a technique in the form of LD-ZNet to further boost the performance of text-based segmentation. Overall, we show up to 6% improvement over standard baselines for text-to-image segmentation on natural images. For AI-generated imagery, we show close to 20% improvement compared to state-of-the-art techniques.
Frustratingly Simple but Effective Zero-shot Detection and Segmentation: Analysis and a Strong Baseline
Feb 14, 2023Methods for object detection and segmentation often require abundant instance-level annotations for training, which are time-consuming and expensive to collect. To address this, the task of zero-shot object detection (or segmentation) aims at learning effective methods for identifying and localizing object instances for the categories that have no supervision available. Constructing architectures for these tasks requires choosing from a myriad of design options, ranging from the form of the class encoding used to transfer information from seen to unseen categories, to the nature of the function being optimized for learning. In this work, we extensively study these design choices, and carefully construct a simple yet extremely effective zero-shot recognition method. Through extensive experiments on the MSCOCO dataset on object detection and segmentation, we highlight that our proposed method outperforms existing, considerably more complex, architectures. Our findings and method, which we propose as a competitive future baseline, point towards the need to revisit some of the recent design trends in zero-shot detection / segmentation.
Energy-Based Learning for Scene Graph Generation
Mar 03, 2021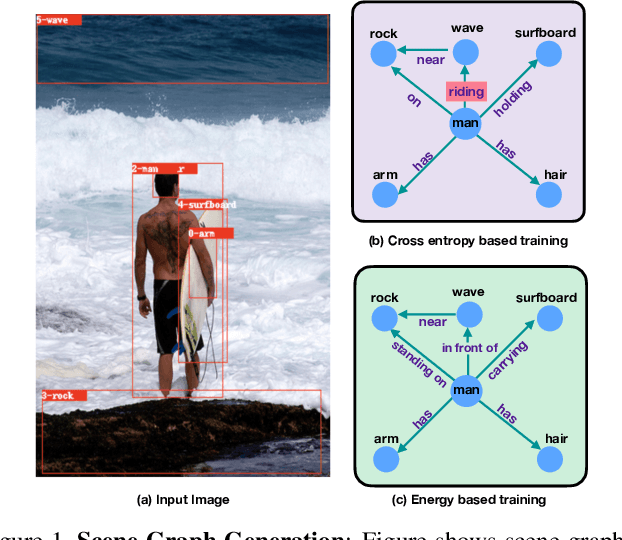

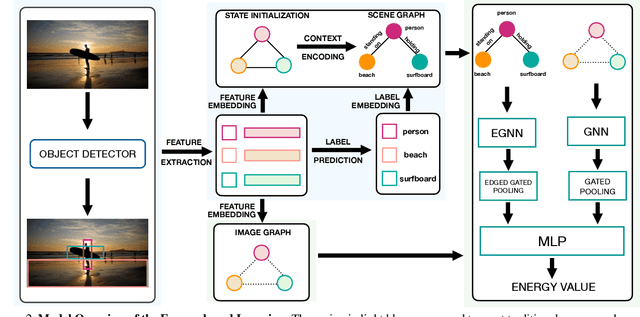
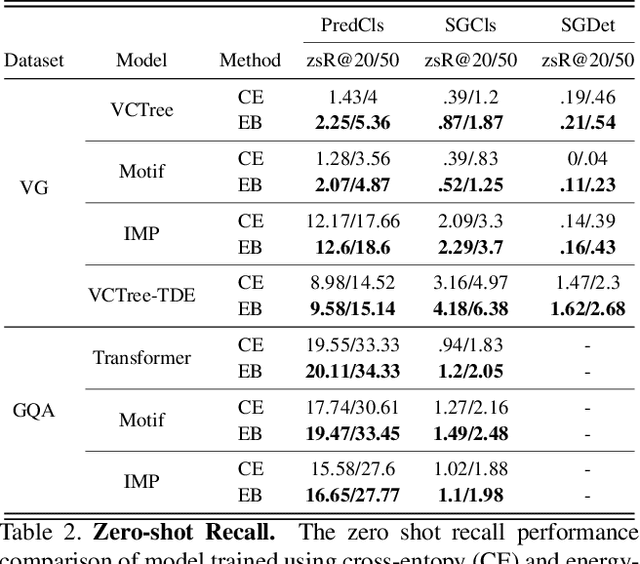
Traditional scene graph generation methods are trained using cross-entropy losses that treat objects and relationships as independent entities. Such a formulation, however, ignores the structure in the output space, in an inherently structured prediction problem. In this work, we introduce a novel energy-based learning framework for generating scene graphs. The proposed formulation allows for efficiently incorporating the structure of scene graphs in the output space. This additional constraint in the learning framework acts as an inductive bias and allows models to learn efficiently from a small number of labels. We use the proposed energy-based framework to train existing state-of-the-art models and obtain a significant performance improvement, of up to 21% and 27%, on the Visual Genome and GQA benchmark datasets, respectively. Furthermore, we showcase the learning efficiency of the proposed framework by demonstrating superior performance in the zero- and few-shot settings where data is scarce.
Human Social Interaction Modeling Using Temporal Deep Networks
May 28, 2015
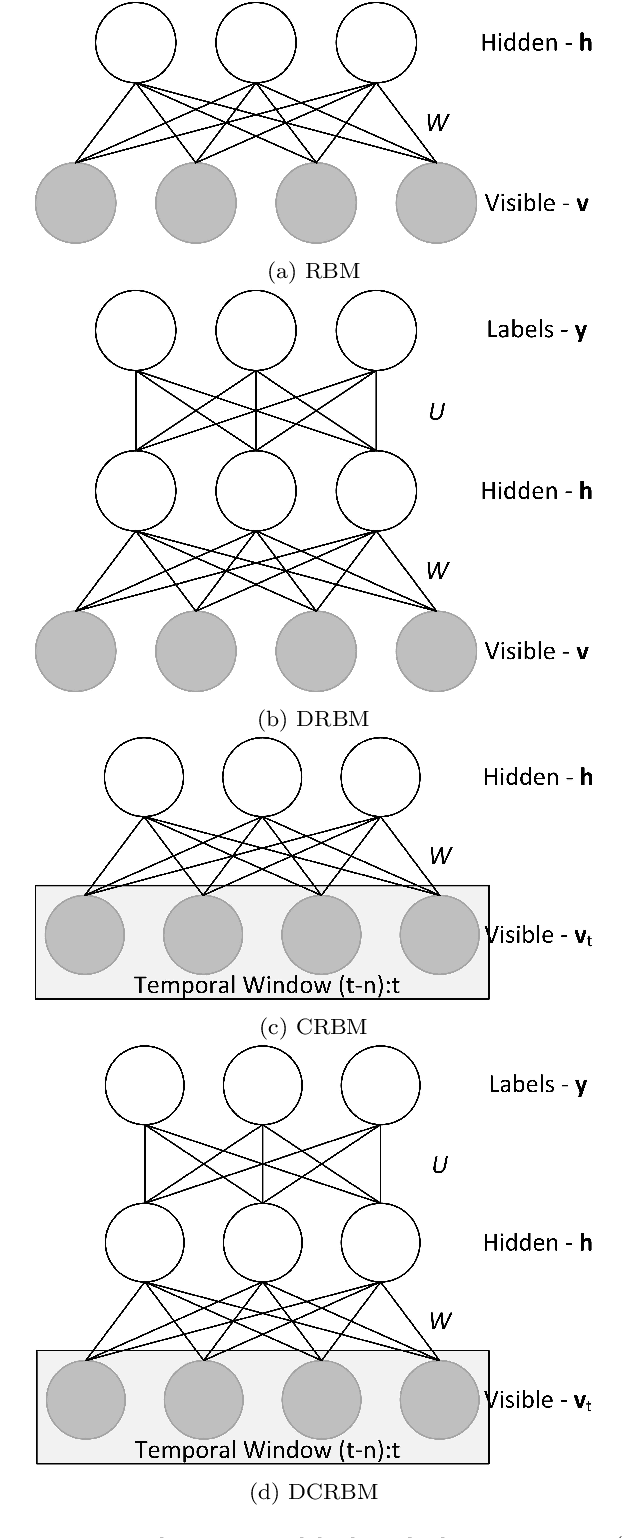
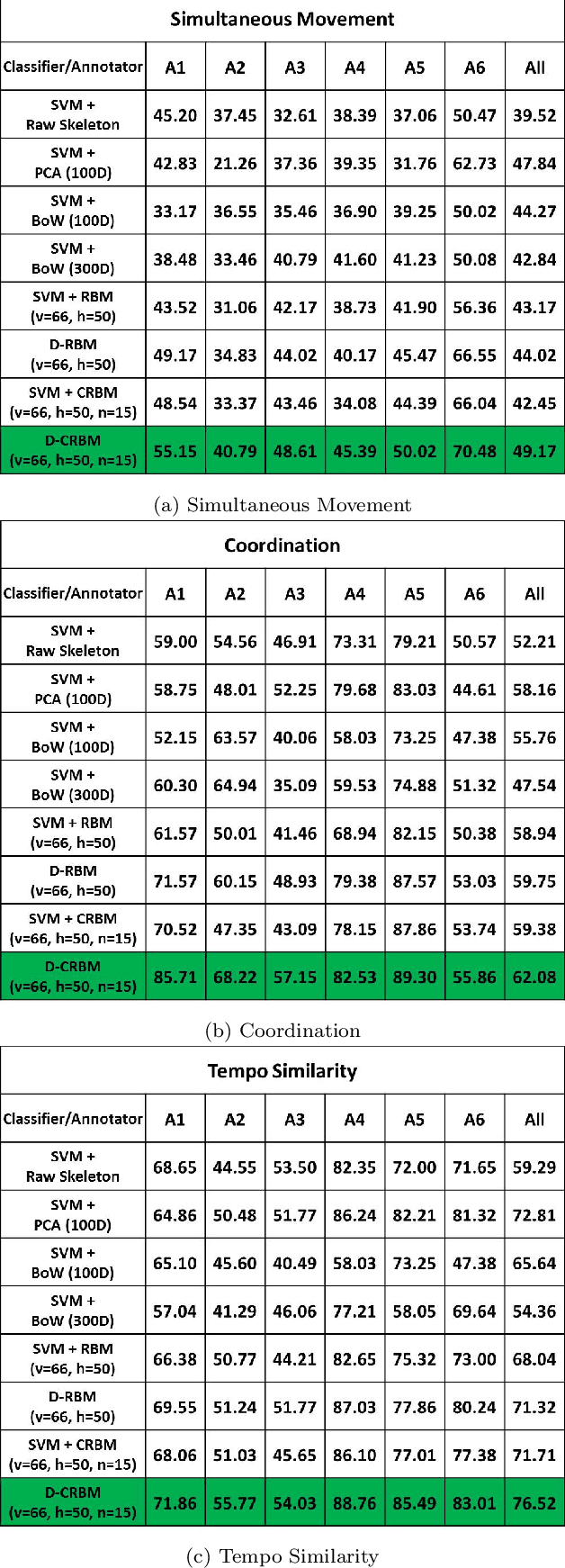
We present a novel approach to computational modeling of social interactions based on modeling of essential social interaction predicates (ESIPs) such as joint attention and entrainment. Based on sound social psychological theory and methodology, we collect a new "Tower Game" dataset consisting of audio-visual capture of dyadic interactions labeled with the ESIPs. We expect this dataset to provide a new avenue for research in computational social interaction modeling. We propose a novel joint Discriminative Conditional Restricted Boltzmann Machine (DCRBM) model that combines a discriminative component with the generative power of CRBMs. Such a combination enables us to uncover actionable constituents of the ESIPs in two steps. First, we train the DCRBM model on the labeled data and get accurate (76\%-49\% across various ESIPs) detection of the predicates. Second, we exploit the generative capability of DCRBMs to activate the trained model so as to generate the lower-level data corresponding to the specific ESIP that closely matches the actual training data (with mean square error 0.01-0.1 for generating 100 frames). We are thus able to decompose the ESIPs into their constituent actionable behaviors. Such a purely computational determination of how to establish an ESIP such as engagement is unprecedented.