 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Classification with Hierarchical Multigraph Networks
Jul 21, 2019
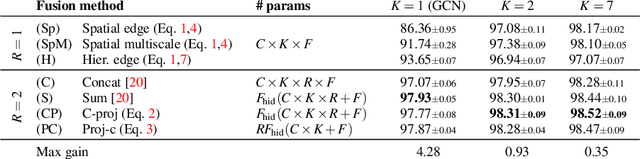
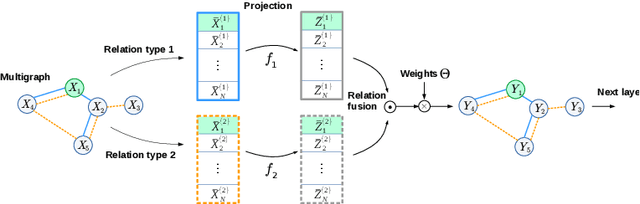

Graph Convolutional Networks (GCNs) are a class of general models that can learn from graph structured data. Despite being general, GCNs are admittedly inferior to convolutional neural networks (CNNs) when applied to vision tasks, mainly due to the lack of domain knowledge that is hardcoded into CNNs, such as spatially oriented translation invariant filters. However, a great advantage of GCNs is the ability to work on irregular inputs, such as superpixels of images. This could significantly reduce the computational cost of image reasoning tasks. Another key advantage inherent to GCNs is the natural ability to model multirelational data. Building upon these two promising properties, in this work, we show best practices for designing GCNs for image classification; in some cases even outperforming CNNs on the MNIST, CIFAR-10 and PASCAL image datasets.
Data-Efficient Mutual Information Neural Estimator
May 24, 2019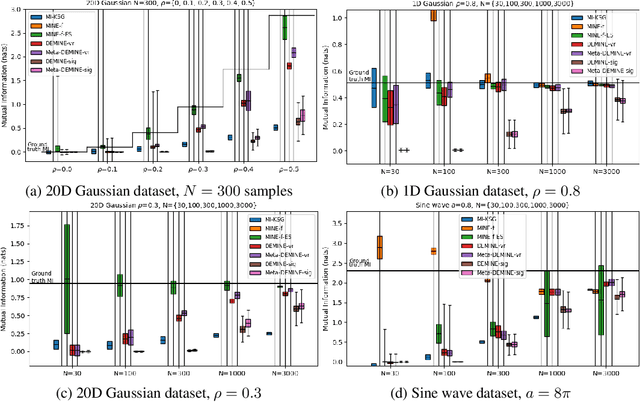
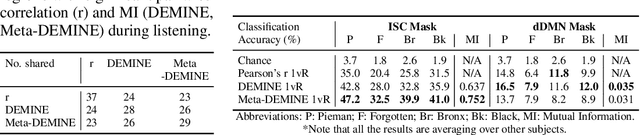
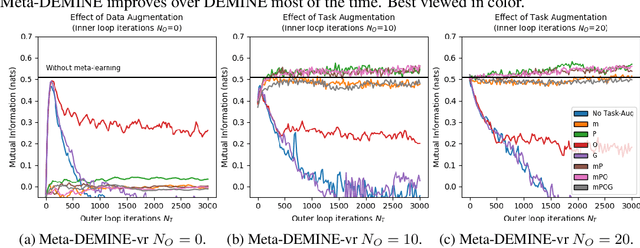
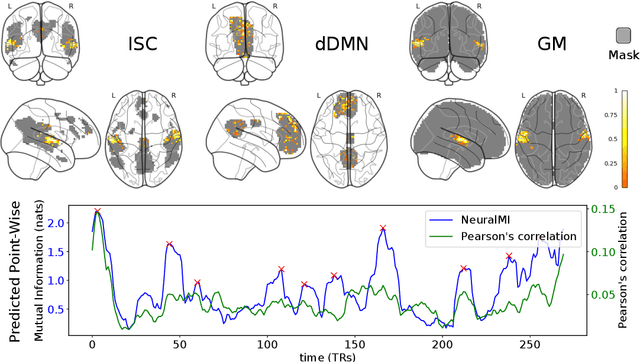
Measuring Mutual Information (MI) between high-dimensional, continuous, random variables from observed samples has wide theoretical and practical applications. Recent work, MINE (Belghazi et al. 2018), focused on estimating tight variational lower bounds of MI using neural networks, but assumed unlimited supply of samples to prevent overfitting. In real world applications, data is not always available at a surplus. In this work, we focus on improving data efficiency and propose a Data-Efficient MINE Estimator (DEMINE), by developing a relaxed predictive MI lower bound that can be estimated at higher data efficiency by orders of magnitudes. The predictive MI lower bound also enables us to develop a new meta-learning approach using task augmentation, Meta-DEMINE, to improve generalization of the network and further boost estimation accuracy empirically. With improved data-efficiency, our estimators enables statistical testing of dependency at practical dataset sizes. We demonstrate the effectiveness of our estimators on synthetic benchmarks and a real world fMRI data, with application of inter-subject correlation analysis.
Understanding attention in graph neural networks
May 08, 2019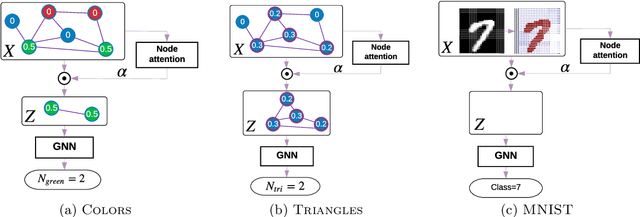
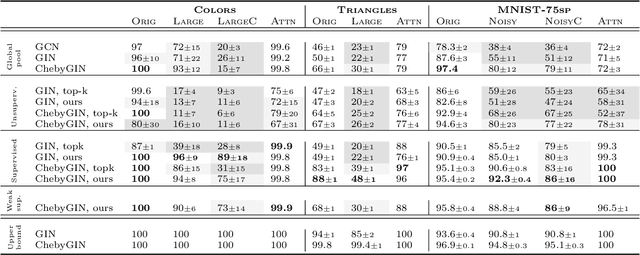
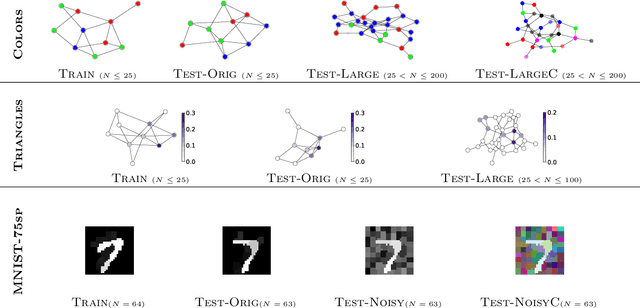
We aim to better understand attention over nodes in graph neural networks and identify factors influencing its effectiveness. Motivated by insights from the work on Graph Isomorphism Networks (Xu et al., 2019), we design simple graph reasoning tasks that allow us to study attention in a controlled environment. We find that under typical conditions the effect of attention is negligible or even harmful, but under certain conditions it provides an exceptional gain in performance of more than 40% in some of our classification tasks. However, we have yet to satisfy these conditions in practice.
Spectral Multigraph Networks for Discovering and Fusing Relationships in Molecules
Nov 23, 2018
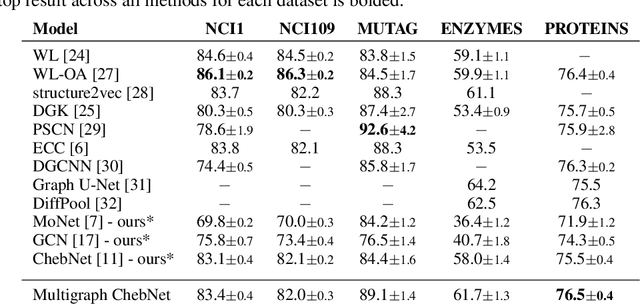


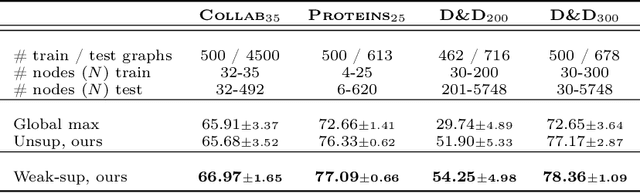
Spectral Graph Convolutional Networks (GCNs) are a generalization of convolutional networks to learning on graph-structured data. Applications of spectral GCNs have been successful, but limited to a few problems where the graph is fixed, such as shape correspondence and node classification. In this work, we address this limitation by revisiting a particular family of spectral graph networks, Chebyshev GCNs, showing its efficacy in solving graph classification tasks with a variable graph structure and size. Chebyshev GCNs restrict graphs to have at most one edge between any pair of nodes. To this end, we propose a novel multigraph network that learns from multi-relational graphs. We model learned edges with abstract meaning and experiment with different ways to fuse the representations extracted from annotated and learned edges, achieving competitive results on a variety of chemical classification benchmarks.
Human Motion Modeling using DVGANs
May 18, 2018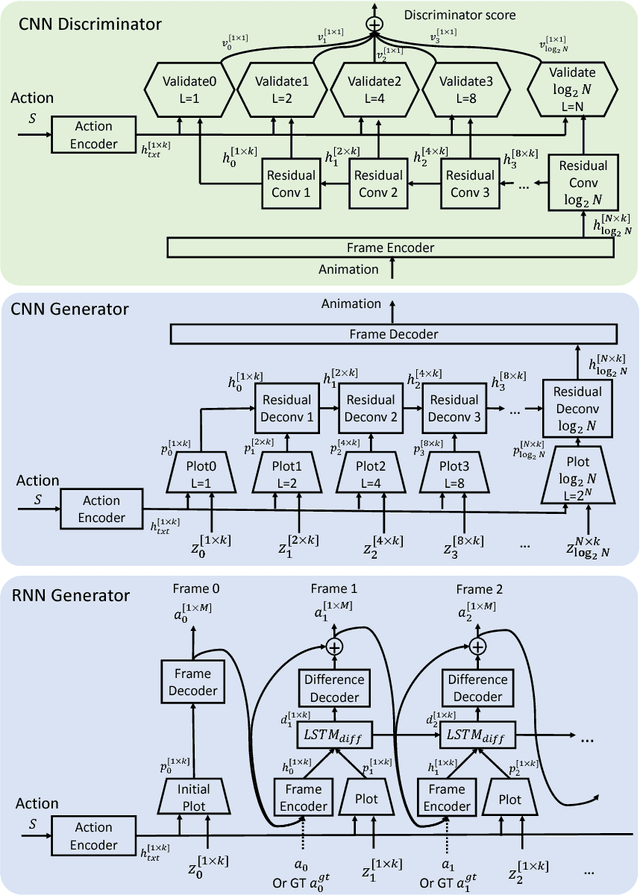
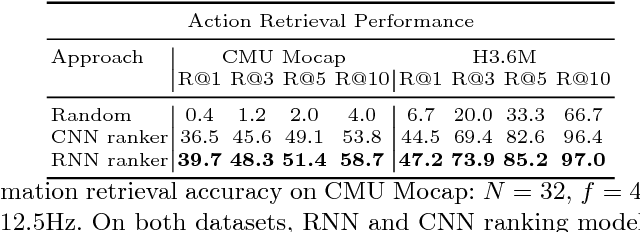
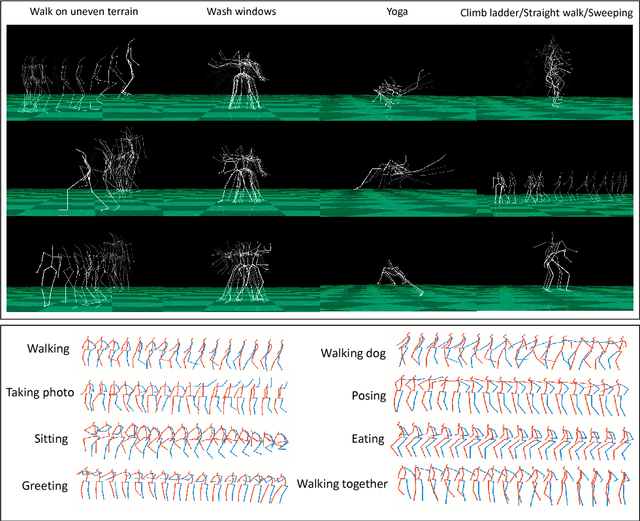
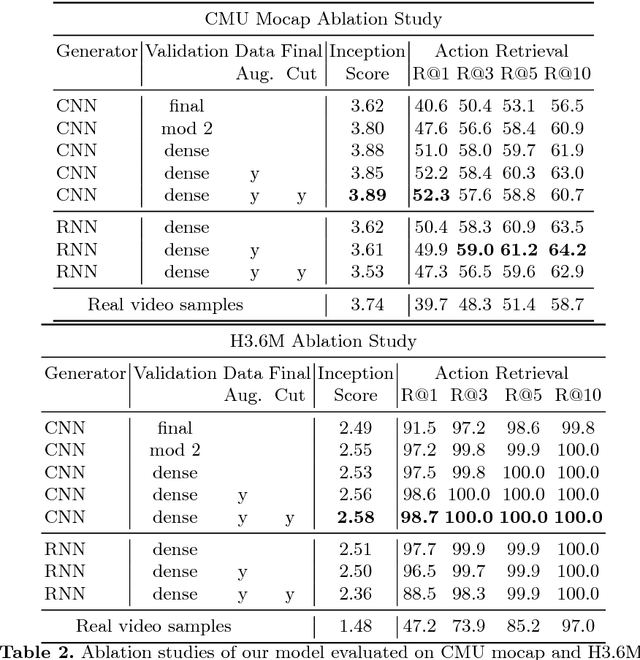
We present a novel generative model for human motion modeling using Generative Adversarial Networks (GANs). We formulate the GAN discriminator using dense validation at each time-scale and perturb the discriminator input to make it translation invariant. Our model is capable of motion generation and completion. We show through our evaluations the resiliency to noise, generalization over actions, and generation of long diverse sequences. We evaluate our approach on Human 3.6M and CMU motion capture datasets using inception scores.
Structure Optimization for Deep Multimodal Fusion Networks using Graph-Induced Kernels
Jul 03, 2017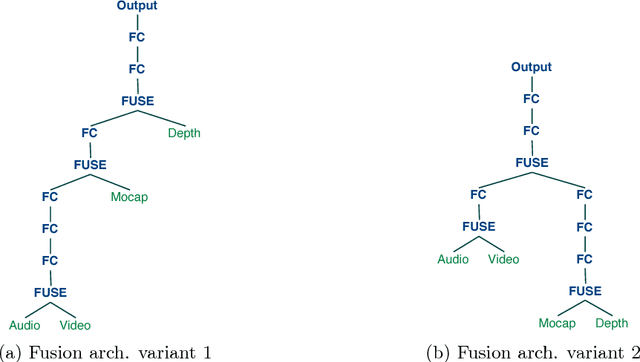
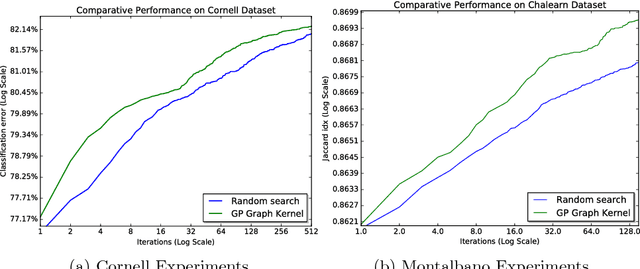
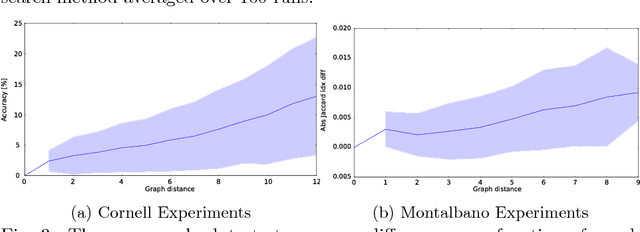
A popular testbed for deep learning has been multimodal recognition of human activity or gesture involving diverse inputs such as video, audio, skeletal pose and depth images. Deep learning architectures have excelled on such problems due to their ability to combine modality representations at different levels of nonlinear feature extraction. However, designing an optimal architecture in which to fuse such learned representations has largely been a non-trivial human engineering effort. We treat fusion structure optimization as a hyper-parameter search and cast it as a discrete optimization problem under the Bayesian optimization framework. We propose a novel graph-induced kernel to compute structural similarities in the search space of tree-structured multimodal architectures and demonstrate its effectiveness using two challenging multimodal human activity recognition datasets.
Action-Affect Classification and Morphing using Multi-Task Representation Learning
Mar 21, 2016



Most recent work focused on affect from facial expressions, and not as much on body. This work focuses on body affect analysis. Affect does not occur in isolation. Humans usually couple affect with an action in natural interactions; for example, a person could be talking and smiling. Recognizing body affect in sequences requires efficient algorithms to capture both the micro movements that differentiate between happy and sad and the macro variations between different actions. We depart from traditional approaches for time-series data analytics by proposing a multi-task learning model that learns a shared representation that is well-suited for action-affect classification as well as generation. For this paper we choose Conditional Restricted Boltzmann Machines to be our building block. We propose a new model that enhances the CRBM model with a factored multi-task component to become Multi-Task Conditional Restricted Boltzmann Machines (MTCRBMs). We evaluate our approach on two publicly available datasets, the Body Affect dataset and the Tower Game dataset, and show superior classification performance improvement over the state-of-the-art, as well as the generative abilities of our model.
Human Social Interaction Modeling Using Temporal Deep Networks
May 28, 2015
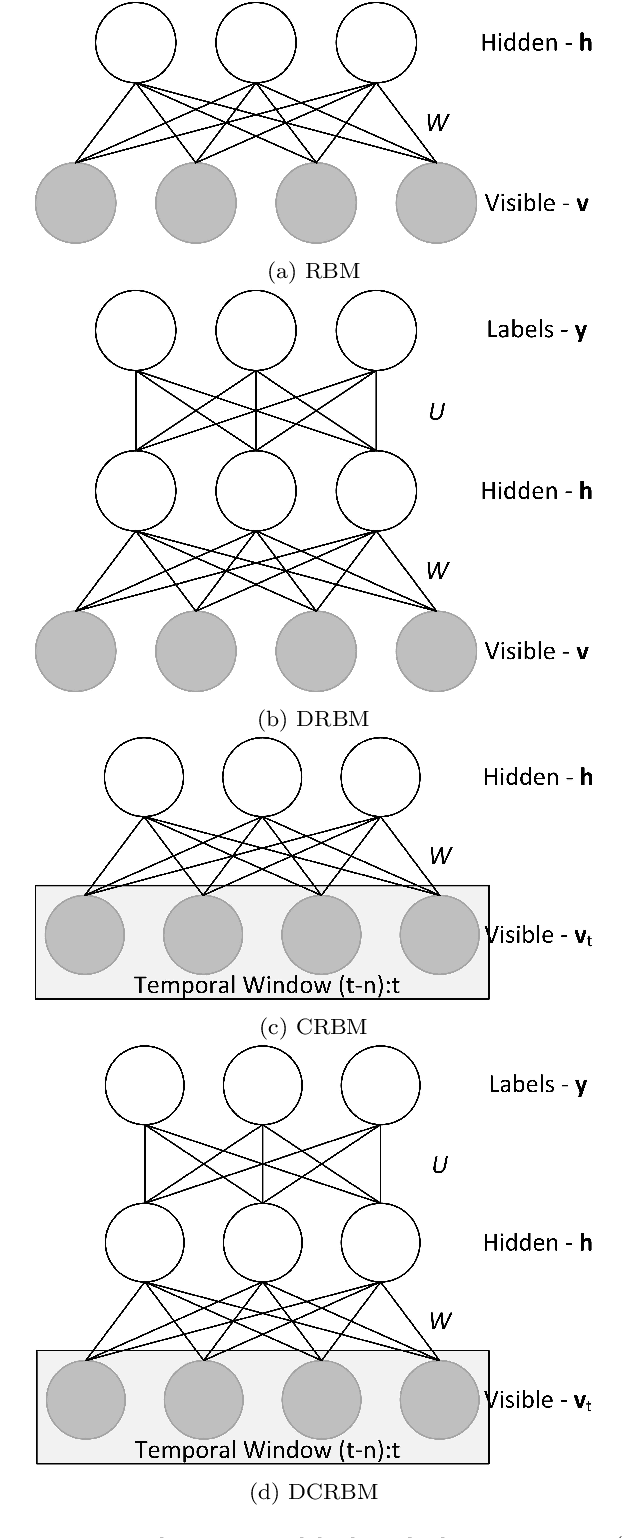
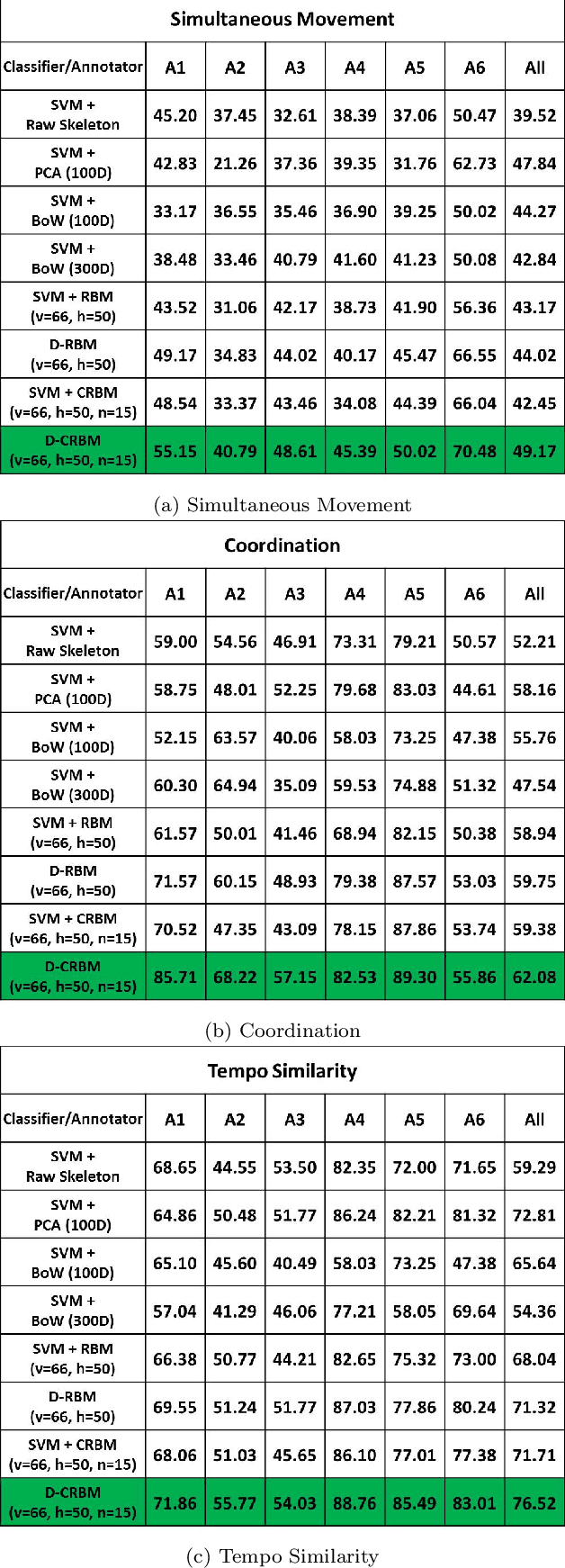
We present a novel approach to computational modeling of social interactions based on modeling of essential social interaction predicates (ESIPs) such as joint attention and entrainment. Based on sound social psychological theory and methodology, we collect a new "Tower Game" dataset consisting of audio-visual capture of dyadic interactions labeled with the ESIPs. We expect this dataset to provide a new avenue for research in computational social interaction modeling. We propose a novel joint Discriminative Conditional Restricted Boltzmann Machine (DCRBM) model that combines a discriminative component with the generative power of CRBMs. Such a combination enables us to uncover actionable constituents of the ESIPs in two steps. First, we train the DCRBM model on the labeled data and get accurate (76\%-49\% across various ESIPs) detection of the predicates. Second, we exploit the generative capability of DCRBMs to activate the trained model so as to generate the lower-level data corresponding to the specific ESIP that closely matches the actual training data (with mean square error 0.01-0.1 for generating 100 frames). We are thus able to decompose the ESIPs into their constituent actionable behaviors. Such a purely computational determination of how to establish an ESIP such as engagement is unprecedented.