 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit-Driven Batch Selection for Robust Learning under Label Noise
Oct 31, 2023



We introduce a novel approach for batch selection in Stochastic Gradient Descent (SGD) training, leveraging combinatorial bandit algorithms. Our methodology focuses on optimizing the learning process in the presence of label noise, a prevalent issue in real-world datasets. Experimental evaluations on the CIFAR-10 dataset reveal that our approach consistently outperforms existing methods across various levels of label corruption. Importantly, we achieve this superior performance without incurring the computational overhead commonly associated with auxiliary neural network models. This work presents a balanced trade-off between computational efficiency and model efficacy, offering a scalable solution for complex machine learning applications.
An Empirical Study of Neural Kernel Bandits
Nov 05, 2021

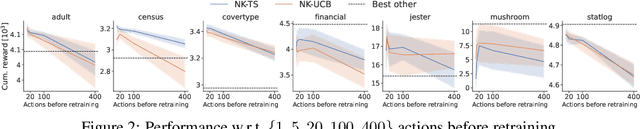

Neural bandits have enabled practitioners to operate efficiently on problems with non-linear reward functions. While in general contextual bandits commonly utilize Gaussian process (GP) predictive distributions for decision making, the most successful neural variants use only the last layer parameters in the derivation. Research on neural kernels (NK) has recently established a correspondence between deep networks and GPs that take into account all the parameters of a NN and can be trained more efficiently than most Bayesian NNs. We propose to directly apply NK-induced distributions to guide an upper confidence bound or Thompson sampling-based policy. We show that NK bandits achieve state-of-the-art performance on highly non-linear structured data. Furthermore, we analyze practical considerations such as training frequency and model partitioning. We believe our work will help better understand the impact of utilizing NKs in applied settings.
Evaluating Curriculum Learning Strategies in Neural Combinatorial Optimization
Nov 12, 2020

Neural combinatorial optimization (NCO) aims at designing problem-independent and efficient neural network-based strategies for solving combinatorial problems. The field recently experienced growth by successfully adapting architectures originally designed for machine translation. Even though the results are promising, a large gap still exists between NCO models and classic deterministic solvers, both in terms of accuracy and efficiency. One of the drawbacks of current approaches is the inefficiency of training on multiple problem sizes. Curriculum learning strategies have been shown helpful in increasing performance in the multi-task setting. In this work, we focus on designing a curriculum learning-based training procedure that can help existing architectures achieve competitive performance on a large range of problem sizes simultaneously. We provide a systematic investigation of several training procedures and use the insights gained to motivate application of a psychologically-inspired approach to improve upon the classic curriculum method.
Structure Optimization for Deep Multimodal Fusion Networks using Graph-Induced Kernels
Jul 03, 2017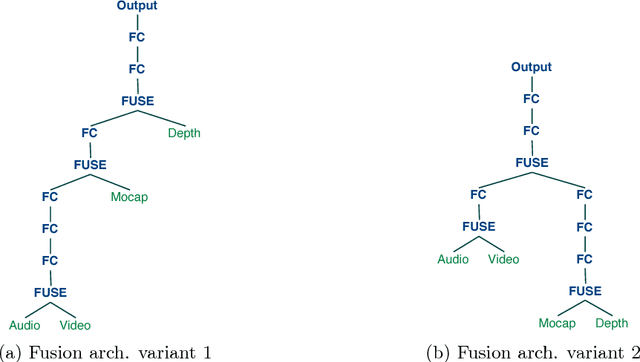
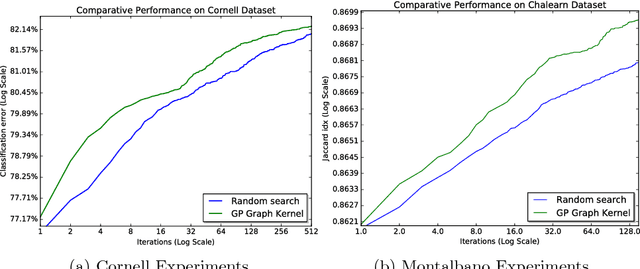
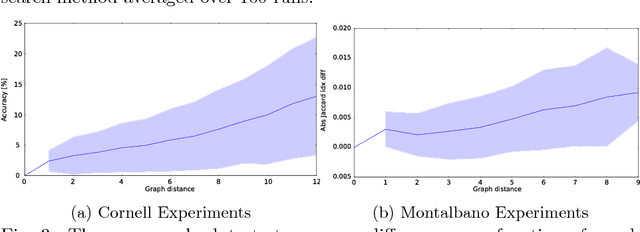
A popular testbed for deep learning has been multimodal recognition of human activity or gesture involving diverse inputs such as video, audio, skeletal pose and depth images. Deep learning architectures have excelled on such problems due to their ability to combine modality representations at different levels of nonlinear feature extraction. However, designing an optimal architecture in which to fuse such learned representations has largely been a non-trivial human engineering effort. We treat fusion structure optimization as a hyper-parameter search and cast it as a discrete optimization problem under the Bayesian optimization framework. We propose a novel graph-induced kernel to compute structural similarities in the search space of tree-structured multimodal architectures and demonstrate its effectiveness using two challenging multimodal human activity recognition datasets.