 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Optimization for Deep Multimodal Fusion Networks using Graph-Induced Kernels
Jul 03, 2017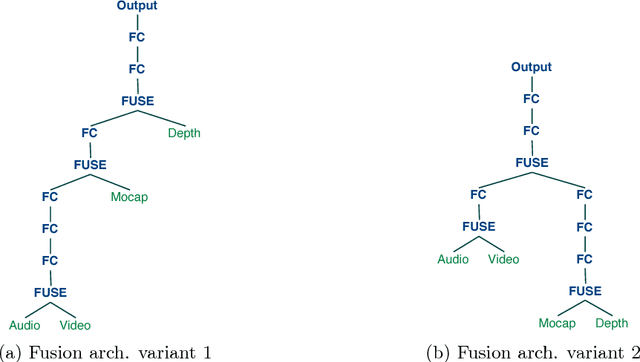
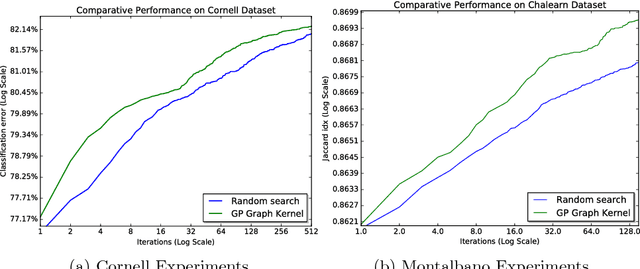
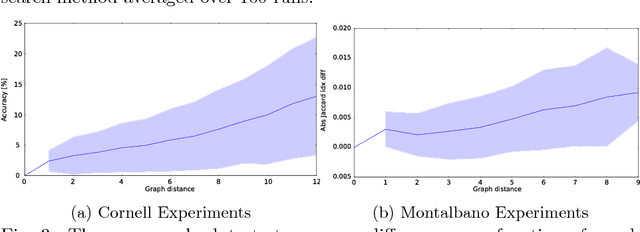
A popular testbed for deep learning has been multimodal recognition of human activity or gesture involving diverse inputs such as video, audio, skeletal pose and depth images. Deep learning architectures have excelled on such problems due to their ability to combine modality representations at different levels of nonlinear feature extraction. However, designing an optimal architecture in which to fuse such learned representations has largely been a non-trivial human engineering effort. We treat fusion structure optimization as a hyper-parameter search and cast it as a discrete optimization problem under the Bayesian optimization framework. We propose a novel graph-induced kernel to compute structural similarities in the search space of tree-structured multimodal architectures and demonstrate its effectiveness using two challenging multimodal human activity recognition datasets.
Action-Affect Classification and Morphing using Multi-Task Representation Learning
Mar 21, 2016



Most recent work focused on affect from facial expressions, and not as much on body. This work focuses on body affect analysis. Affect does not occur in isolation. Humans usually couple affect with an action in natural interactions; for example, a person could be talking and smiling. Recognizing body affect in sequences requires efficient algorithms to capture both the micro movements that differentiate between happy and sad and the macro variations between different actions. We depart from traditional approaches for time-series data analytics by proposing a multi-task learning model that learns a shared representation that is well-suited for action-affect classification as well as generation. For this paper we choose Conditional Restricted Boltzmann Machines to be our building block. We propose a new model that enhances the CRBM model with a factored multi-task component to become Multi-Task Conditional Restricted Boltzmann Machines (MTCRBMs). We evaluate our approach on two publicly available datasets, the Body Affect dataset and the Tower Game dataset, and show superior classification performance improvement over the state-of-the-art, as well as the generative abilities of our model.