 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAM: Merging Improves Pruning of Experts in LLMs
Apr 06, 2026Mixture-of-Experts (MoE) large language models (LLMs) are among the top-performing architectures. The largest models, often with hundreds of billions of parameters, pose significant memory challenges for deployment. Traditional approaches to reduce memory requirements include weight pruning and quantization. Motivated by the Router-weighted Expert Activation Pruning (REAP) that prunes experts, we propose a novel method, Router-weighted Expert Activation Merging (REAM). Instead of removing experts, REAM groups them and merges their weights, better preserving original performance. We evaluate REAM against REAP and other baselines across multiple MoE LLMs on diverse multiple-choice (MC) question answering and generative (GEN) benchmarks. Our results reveal a trade-off between MC and GEN performance that depends on the mix of calibration data. By controlling the mix of general, math and coding data, we examine the Pareto frontier of this trade-off and show that REAM often outperforms the baselines and in many cases is comparable to the original uncompressed models.
Celo2: Towards Learned Optimization Free Lunch
Feb 22, 2026Learned optimizers are powerful alternatives to hand-designed update rules like Adam, yet they have seen limited practical adoption since they often fail to meta-generalize beyond their training distribution and incur high meta-training cost. For instance, prior work, VeLO, scaled meta-training to 4,000 TPU months ($\sim$10$\times$ GPT-3 compute) to meta-train a general-purpose optimizer but it failed to generalize beyond 600M parameters tasks. In this work, we present a surprising finding: by crafting a simple normalized optimizer architecture and augmenting meta-training, it becomes feasible to meta-train a performant general-purpose learned update rule on a tiny fraction of VeLO compute, 4.5 GPU hours to be precise. Our learned update rule scales stably to a billion-scale pretraining task (GPT-3 XL 1.3B) which is six orders of magnitude larger than its meta-training distribution. Furthermore, it shows strong performance across diverse out-of-distribution tasks and is compatible with modern optimization harness that includes orthogonalization, distinct update rules for input-output and hidden weights, and decoupled weight decay. In all, this work paves the way for practically applicable learnable optimization algorithms, unlocking exploration of richer meta-training and data curation recipes to further improve performance.
M^4olGen: Multi-Agent, Multi-Stage Molecular Generation under Precise Multi-Property Constraints
Jan 16, 2026Generating molecules that satisfy precise numeric constraints over multiple physicochemical properties is critical and challenging. Although large language models (LLMs) are expressive, they struggle with precise multi-objective control and numeric reasoning without external structure and feedback. We introduce \textbf{M olGen}, a fragment-level, retrieval-augmented, two-stage framework for molecule generation under multi-property constraints. Stage I : Prototype generation: a multi-agent reasoner performs retrieval-anchored, fragment-level edits to produce a candidate near the feasible region. Stage II : RL-based fine-grained optimization: a fragment-level optimizer trained with Group Relative Policy Optimization (GRPO) applies one- or multi-hop refinements to explicitly minimize the property errors toward our target while regulating edit complexity and deviation from the prototype. A large, automatically curated dataset with reasoning chains of fragment edits and measured property deltas underpins both stages, enabling deterministic, reproducible supervision and controllable multi-hop reasoning. Unlike prior work, our framework better reasons about molecules by leveraging fragments and supports controllable refinement toward numeric targets. Experiments on generation under two sets of property constraints (QED, LogP, Molecular Weight and HOMO, LUMO) show consistent gains in validity and precise satisfaction of multi-property targets, outperforming strong LLMs and graph-based algorithms.
Generating $π$-Functional Molecules Using STGG+ with Active Learning
Feb 20, 2025Generating novel molecules with out-of-distribution properties is a major challenge in molecular discovery. While supervised learning methods generate high-quality molecules similar to those in a dataset, they struggle to generalize to out-of-distribution properties. Reinforcement learning can explore new chemical spaces but often conducts 'reward-hacking' and generates non-synthesizable molecules. In this work, we address this problem by integrating a state-of-the-art supervised learning method, STGG+, in an active learning loop. Our approach iteratively generates, evaluates, and fine-tunes STGG+ to continuously expand its knowledge. We denote this approach STGG+AL. We apply STGG+AL to the design of organic $\pi$-functional materials, specifically two challenging tasks: 1) generating highly absorptive molecules characterized by high oscillator strength and 2) designing absorptive molecules with reasonable oscillator strength in the near-infrared (NIR) range. The generated molecules are validated and rationalized in-silico with time-dependent density functional theory. Our results demonstrate that our method is highly effective in generating novel molecules with high oscillator strength, contrary to existing methods such as reinforcement learning (RL) methods. We open-source our active-learning code along with our Conjugated-xTB dataset containing 2.9 million $\pi$-conjugated molecules and the function for approximating the oscillator strength and absorption wavelength (based on sTDA-xTB).
Accelerating Training with Neuron Interaction and Nowcasting Networks
Sep 06, 2024



Neural network training can be accelerated when a learnable update rule is used in lieu of classic adaptive optimizers (e.g. Adam). However, learnable update rules can be costly and unstable to train and use. A simpler recently proposed approach to accelerate training is to use Adam for most of the optimization steps and periodically, only every few steps, nowcast (predict future) parameters. We improve this approach by Neuron interaction and Nowcasting (NiNo) networks. NiNo leverages neuron connectivity and graph neural networks to more accurately nowcast parameters by learning in a supervised way from a set of training trajectories over multiple tasks. We show that in some networks, such as Transformers, neuron connectivity is non-trivial. By accurately modeling neuron connectivity, we allow NiNo to accelerate Adam training by up to 50\% in vision and language tasks.
Any-Property-Conditional Molecule Generation with Self-Criticism using Spanning Trees
Jul 12, 2024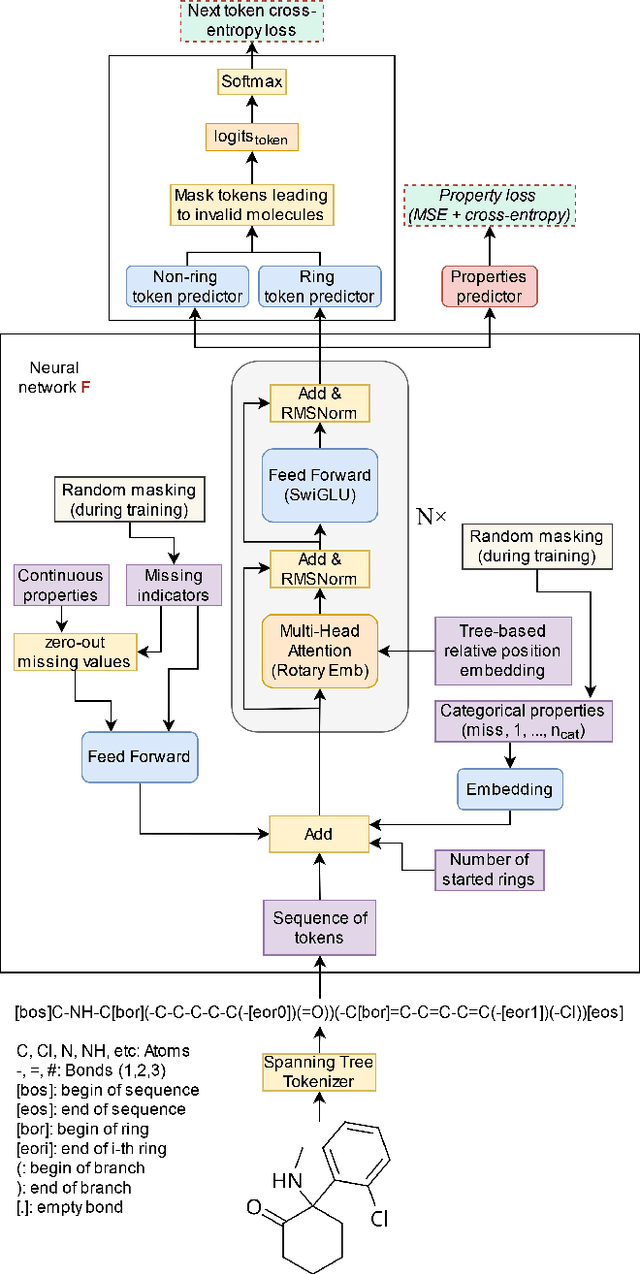
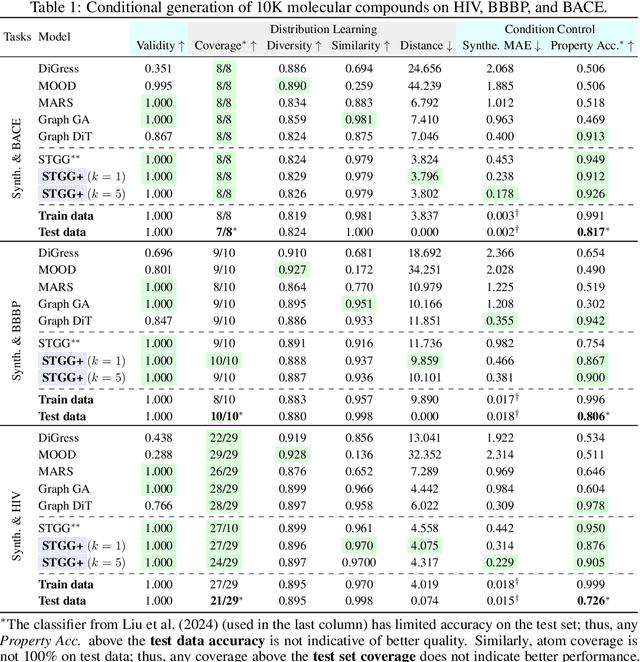
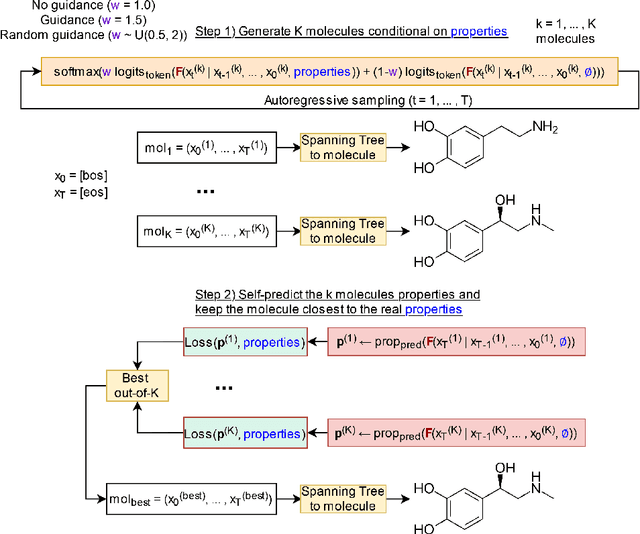
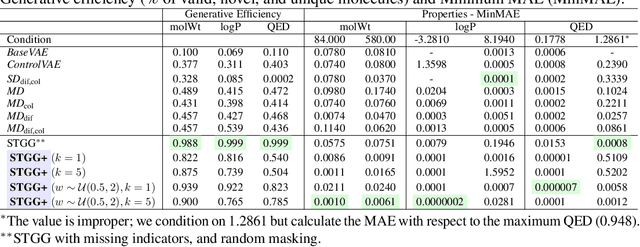
Generating novel molecules is challenging, with most representations leading to generative models producing many invalid molecules. Spanning Tree-based Graph Generation (STGG) is a promising approach to ensure the generation of valid molecules, outperforming state-of-the-art SMILES and graph diffusion models for unconditional generation. In the real world, we want to be able to generate molecules conditional on one or multiple desired properties rather than unconditionally. Thus, in this work, we extend STGG to multi-property-conditional generation. Our approach, STGG+, incorporates a modern Transformer architecture, random masking of properties during training (enabling conditioning on any subset of properties and classifier-free guidance), an auxiliary property-prediction loss (allowing the model to self-criticize molecules and select the best ones), and other improvements. We show that STGG+ achieves state-of-the-art performance on in-distribution and out-of-distribution conditional generation, and reward maximization.
$μ$LO: Compute-Efficient Meta-Generalization of Learned Optimizers
May 31, 2024



Learned optimizers (LOs) can significantly reduce the wall-clock training time of neural networks, substantially reducing training costs. However, they often suffer from poor meta-generalization, especially when training networks larger than those seen during meta-training. To address this, we use the recently proposed Maximal Update Parametrization ($\mu$P), which allows zero-shot generalization of optimizer hyperparameters from smaller to larger models. We extend $\mu$P theory to learned optimizers, treating the meta-training problem as finding the learned optimizer under $\mu$P. Our evaluation shows that LOs meta-trained with $\mu$P substantially improve meta-generalization as compared to LOs trained under standard parametrization (SP). Notably, when applied to large-width models, our best $\mu$LO, trained for 103 GPU-hours, matches or exceeds the performance of VeLO, the largest publicly available learned optimizer, meta-trained with 4000 TPU-months of compute. Moreover, $\mu$LOs demonstrate better generalization than their SP counterparts to deeper networks and to much longer training horizons (25 times longer) than those seen during meta-training.
LoGAH: Predicting 774-Million-Parameter Transformers using Graph HyperNetworks with 1/100 Parameters
May 25, 2024A good initialization of deep learning models is essential since it can help them converge better and faster. However, pretraining large models is unaffordable for many researchers, which makes a desired prediction for initial parameters more necessary nowadays. Graph HyperNetworks (GHNs), one approach to predicting model parameters, have recently shown strong performance in initializing large vision models. Unfortunately, predicting parameters of very wide networks relies on copying small chunks of parameters multiple times and requires an extremely large number of parameters to support full prediction, which greatly hinders its adoption in practice. To address this limitation, we propose LoGAH (Low-rank GrAph Hypernetworks), a GHN with a low-rank parameter decoder that expands to significantly wider networks without requiring as excessive increase of parameters as in previous attempts. LoGAH allows us to predict the parameters of 774-million large neural networks in a memory-efficient manner. We show that vision and language models (i.e., ViT and GPT-2) initialized with LoGAH achieve better performance than those initialized randomly or using existing hypernetworks. Furthermore, we show promising transfer learning results w.r.t. training LoGAH on small datasets and using the predicted parameters to initialize for larger tasks. We provide the codes in https://github.com/Blackzxy/LoGAH .
Graph Neural Networks for Learning Equivariant Representations of Neural Networks
Mar 20, 2024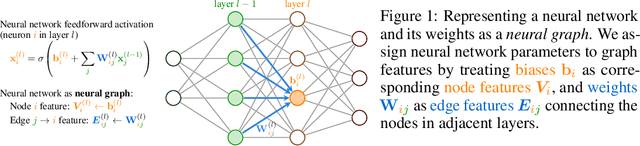
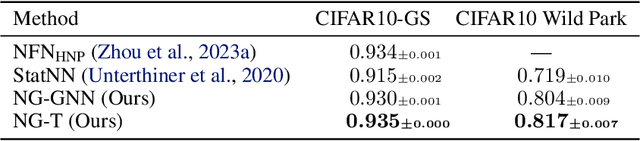
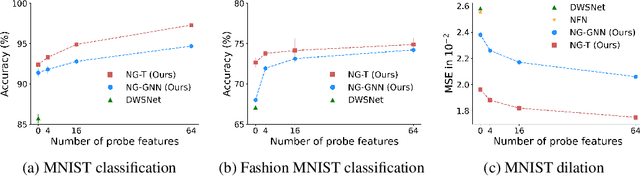
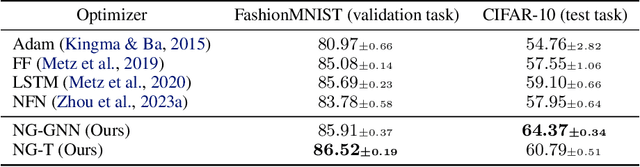
Neural networks that process the parameters of other neural networks find applications in domains as diverse as classifying implicit neural representations, generating neural network weights, and predicting generalization errors. However, existing approaches either overlook the inherent permutation symmetry in the neural network or rely on intricate weight-sharing patterns to achieve equivariance, while ignoring the impact of the network architecture itself. In this work, we propose to represent neural networks as computational graphs of parameters, which allows us to harness powerful graph neural networks and transformers that preserve permutation symmetry. Consequently, our approach enables a single model to encode neural computational graphs with diverse architectures. We showcase the effectiveness of our method on a wide range of tasks, including classification and editing of implicit neural representations, predicting generalization performance, and learning to optimize, while consistently outperforming state-of-the-art methods. The source code is open-sourced at https://github.com/mkofinas/neural-graphs.
Can We Learn Communication-Efficient Optimizers?
Dec 02, 2023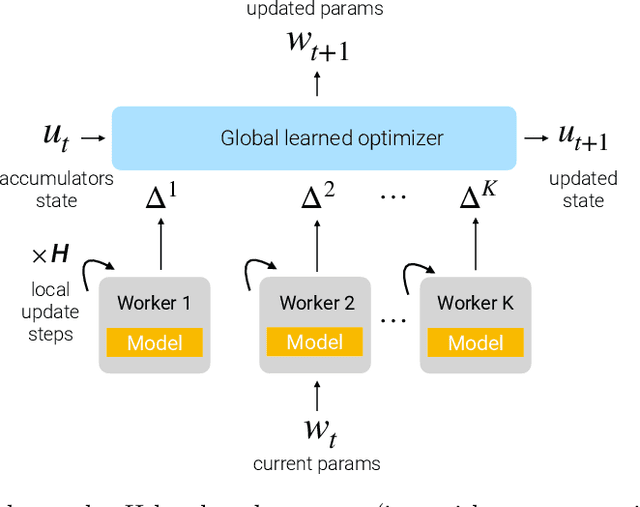

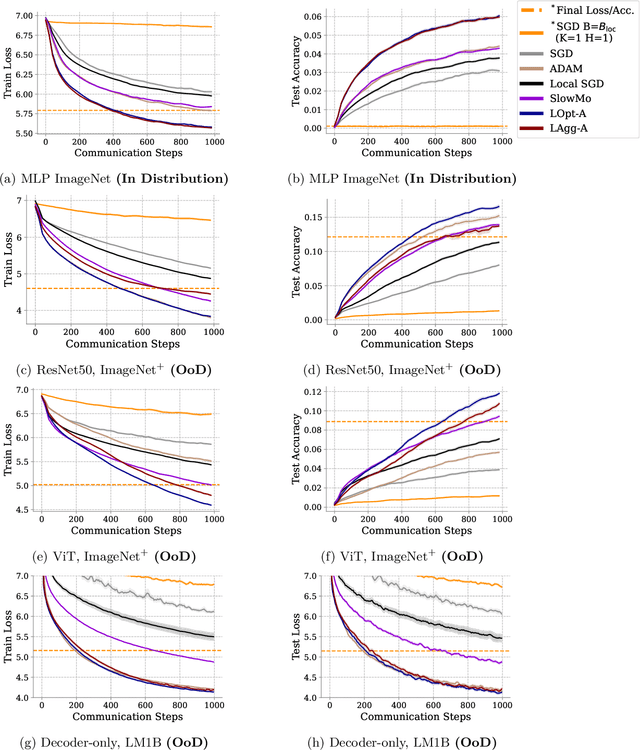
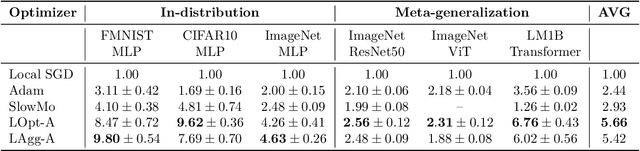
Communication-efficient variants of SGD, specifically local SGD, have received a great deal of interest in recent years. These approaches compute multiple gradient steps locally, that is on each worker, before averaging model parameters, helping relieve the critical communication bottleneck in distributed deep learning training. Although many variants of these approaches have been proposed, they can sometimes lag behind state-of-the-art adaptive optimizers for deep learning. In this work, we investigate if the recent progress in the emerging area of learned optimizers can potentially close this gap while remaining communication-efficient. Specifically, we meta-learn how to perform global updates given an update from local SGD iterations. Our results demonstrate that learned optimizers can substantially outperform local SGD and its sophisticated variants while maintaining their communication efficiency. Learned optimizers can even generalize to unseen and much larger datasets and architectures, including ImageNet and ViTs, and to unseen modalities such as language modeling. We therefore demonstrate the potential of learned optimizers for improving communication-efficient distributed learning.