 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating $π$-Functional Molecules Using STGG+ with Active Learning
Feb 20, 2025Generating novel molecules with out-of-distribution properties is a major challenge in molecular discovery. While supervised learning methods generate high-quality molecules similar to those in a dataset, they struggle to generalize to out-of-distribution properties. Reinforcement learning can explore new chemical spaces but often conducts 'reward-hacking' and generates non-synthesizable molecules. In this work, we address this problem by integrating a state-of-the-art supervised learning method, STGG+, in an active learning loop. Our approach iteratively generates, evaluates, and fine-tunes STGG+ to continuously expand its knowledge. We denote this approach STGG+AL. We apply STGG+AL to the design of organic $\pi$-functional materials, specifically two challenging tasks: 1) generating highly absorptive molecules characterized by high oscillator strength and 2) designing absorptive molecules with reasonable oscillator strength in the near-infrared (NIR) range. The generated molecules are validated and rationalized in-silico with time-dependent density functional theory. Our results demonstrate that our method is highly effective in generating novel molecules with high oscillator strength, contrary to existing methods such as reinforcement learning (RL) methods. We open-source our active-learning code along with our Conjugated-xTB dataset containing 2.9 million $\pi$-conjugated molecules and the function for approximating the oscillator strength and absorption wavelength (based on sTDA-xTB).
Torque-Aware Momentum
Dec 25, 2024Efficiently exploring complex loss landscapes is key to the performance of deep neural networks. While momentum-based optimizers are widely used in state-of-the-art setups, classical momentum can still struggle with large, misaligned gradients, leading to oscillations. To address this, we propose Torque-Aware Momentum (TAM), which introduces a damping factor based on the angle between the new gradients and previous momentum, stabilizing the update direction during training. Empirical results show that TAM, which can be combined with both SGD and Adam, enhances exploration, handles distribution shifts more effectively, and improves generalization performance across various tasks, including image classification and large language model fine-tuning, when compared to classical momentum-based optimizers.
Any-Property-Conditional Molecule Generation with Self-Criticism using Spanning Trees
Jul 12, 2024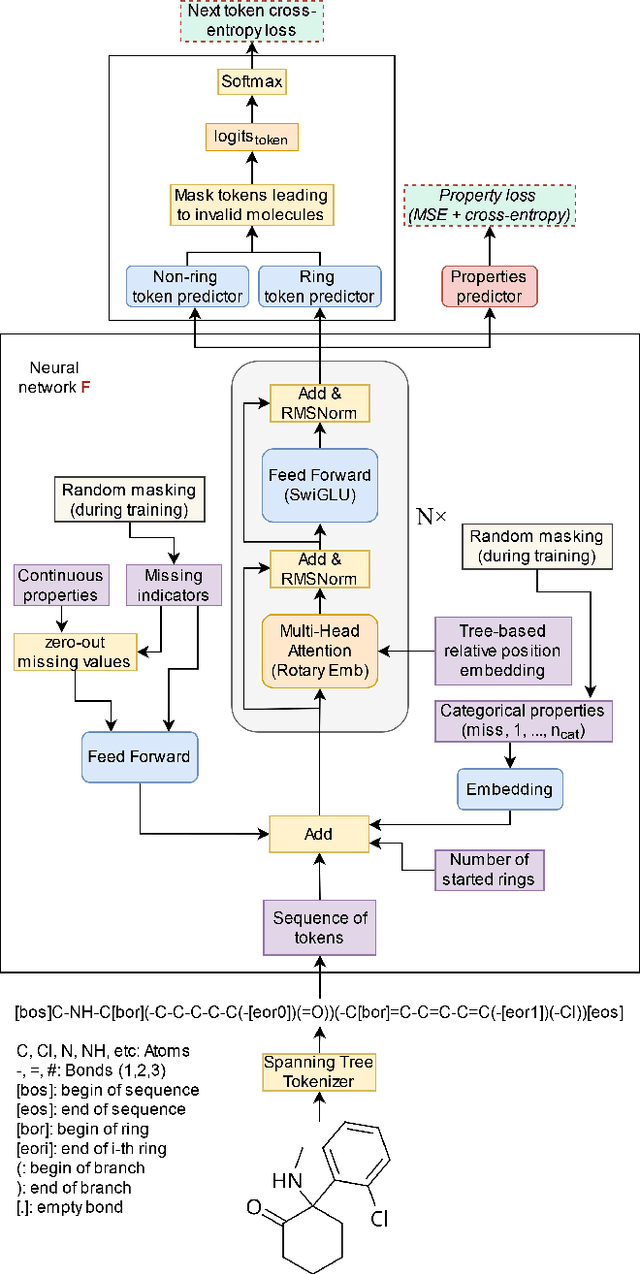
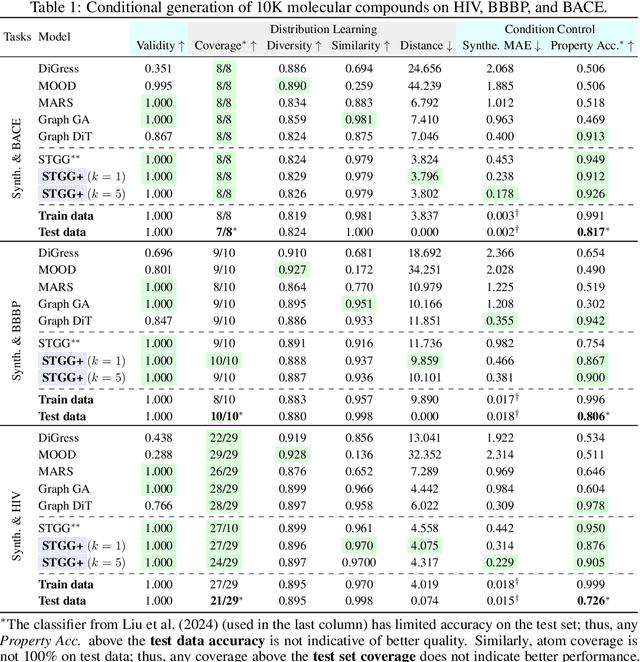
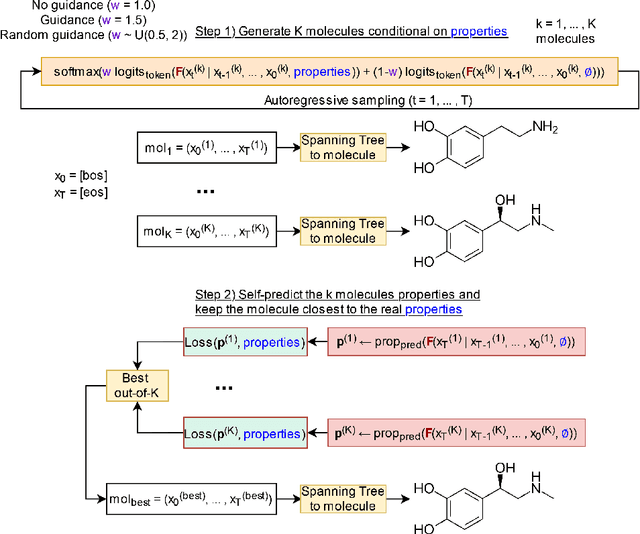
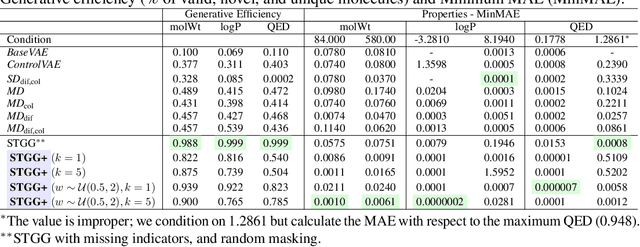
Generating novel molecules is challenging, with most representations leading to generative models producing many invalid molecules. Spanning Tree-based Graph Generation (STGG) is a promising approach to ensure the generation of valid molecules, outperforming state-of-the-art SMILES and graph diffusion models for unconditional generation. In the real world, we want to be able to generate molecules conditional on one or multiple desired properties rather than unconditionally. Thus, in this work, we extend STGG to multi-property-conditional generation. Our approach, STGG+, incorporates a modern Transformer architecture, random masking of properties during training (enabling conditioning on any subset of properties and classifier-free guidance), an auxiliary property-prediction loss (allowing the model to self-criticize molecules and select the best ones), and other improvements. We show that STGG+ achieves state-of-the-art performance on in-distribution and out-of-distribution conditional generation, and reward maximization.
Bias in Motion: Theoretical Insights into the Dynamics of Bias in SGD Training
May 28, 2024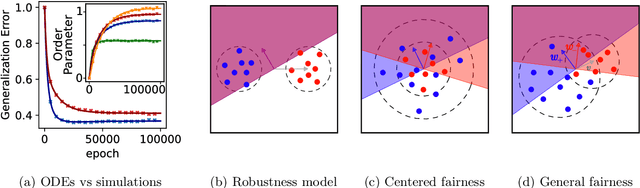
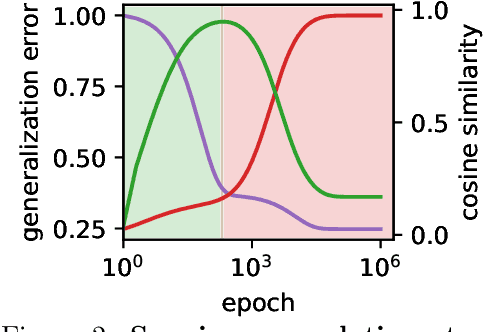
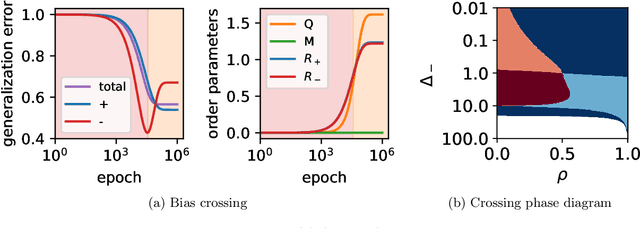
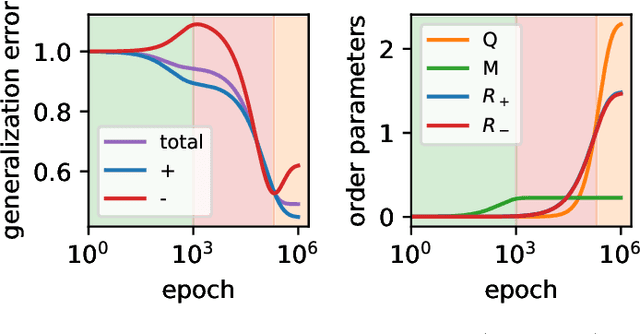
Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations. Current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup modeling different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setting, which we prove to be exact in high dimension. Notably, our analysis reveals how different properties of sub-populations influence bias at different timescales, showing a shifting preference of the classifier during training. Applying our findings to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real datasets, including CIFAR10, MNIST, and CelebA.
Maxwell's Demon at Work: Efficient Pruning by Leveraging Saturation of Neurons
Mar 12, 2024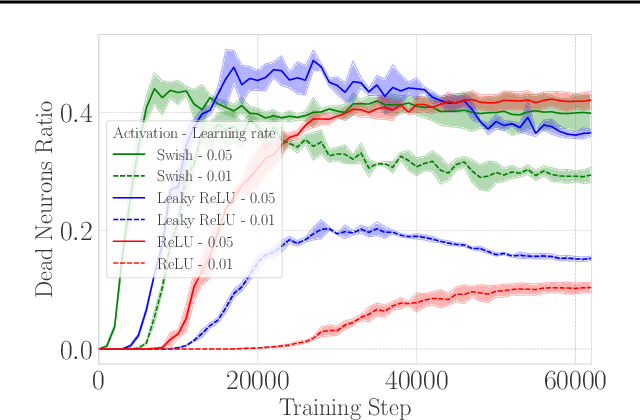
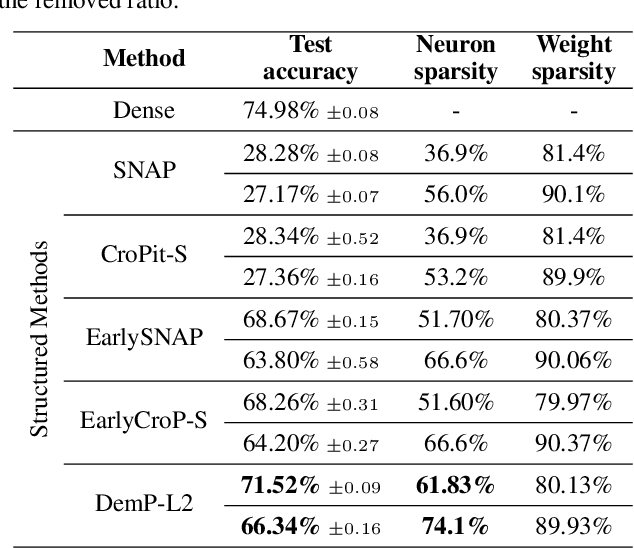
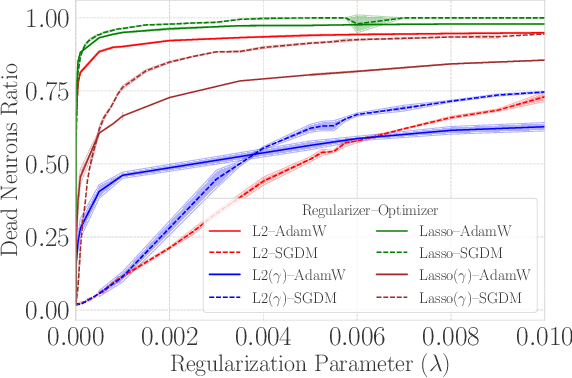
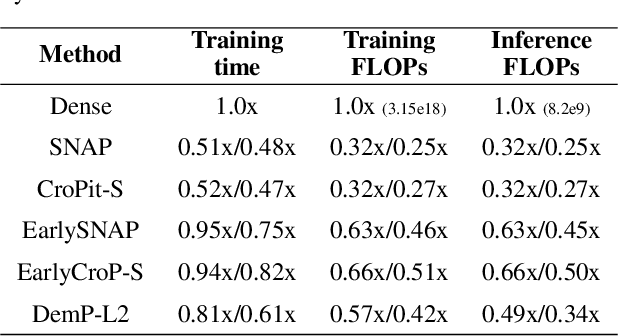
When training deep neural networks, the phenomenon of $\textit{dying neurons}$ $\unicode{x2013}$units that become inactive or saturated, output zero during training$\unicode{x2013}$ has traditionally been viewed as undesirable, linked with optimization challenges, and contributing to plasticity loss in continual learning scenarios. In this paper, we reassess this phenomenon, focusing on sparsity and pruning. By systematically exploring the impact of various hyperparameter configurations on dying neurons, we unveil their potential to facilitate simple yet effective structured pruning algorithms. We introduce $\textit{Demon Pruning}$ (DemP), a method that controls the proliferation of dead neurons, dynamically leading to network sparsity. Achieved through a combination of noise injection on active units and a one-cycled schedule regularization strategy, DemP stands out for its simplicity and broad applicability. Experiments on CIFAR10 and ImageNet datasets demonstrate that DemP surpasses existing structured pruning techniques, showcasing superior accuracy-sparsity tradeoffs and training speedups. These findings suggest a novel perspective on dying neurons as a valuable resource for efficient model compression and optimization.
Unsupervised Concept Discovery Mitigates Spurious Correlations
Feb 20, 2024
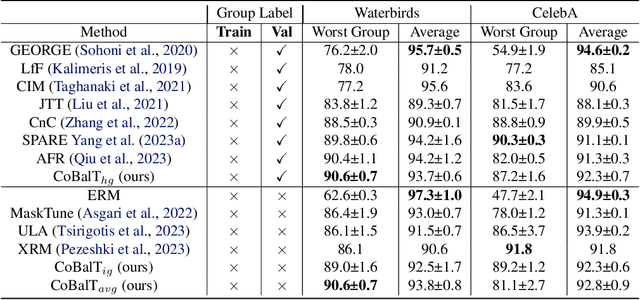
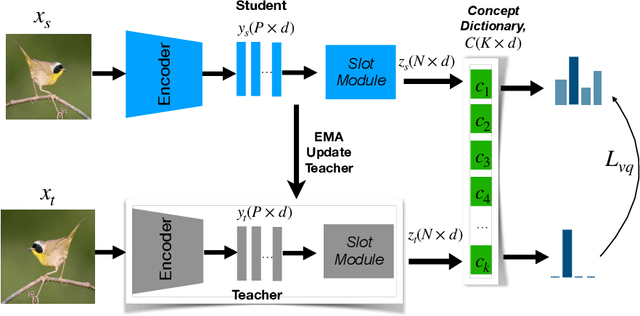
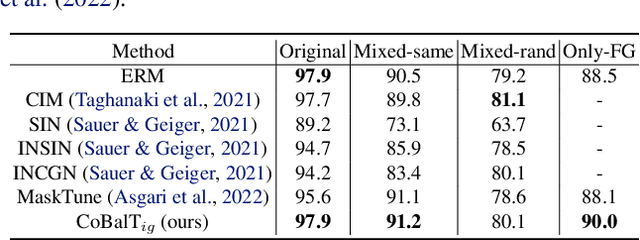
Models prone to spurious correlations in training data often produce brittle predictions and introduce unintended biases. Addressing this challenge typically involves methods relying on prior knowledge and group annotation to remove spurious correlations, which may not be readily available in many applications. In this paper, we establish a novel connection between unsupervised object-centric learning and mitigation of spurious correlations. Instead of directly inferring sub-groups with varying correlations with labels, our approach focuses on discovering concepts: discrete ideas that are shared across input samples. Leveraging existing object-centric representation learning, we introduce CoBalT: a concept balancing technique that effectively mitigates spurious correlations without requiring human labeling of subgroups. Evaluation across the Waterbirds, CelebA and ImageNet-9 benchmark datasets for subpopulation shifts demonstrate superior or competitive performance compared state-of-the-art baselines, without the need for group annotation.
How connectivity structure shapes rich and lazy learning in neural circuits
Oct 12, 2023In theoretical neuroscience, recent work leverages deep learning tools to explore how some network attributes critically influence its learning dynamics. Notably, initial weight distributions with small (resp. large) variance may yield a rich (resp. lazy) regime, where significant (resp. minor) changes to network states and representation are observed over the course of learning. However, in biology, neural circuit connectivity generally has a low-rank structure and therefore differs markedly from the random initializations generally used for these studies. As such, here we investigate how the structure of the initial weights, in particular their effective rank, influences the network learning regime. Through both empirical and theoretical analyses, we discover that high-rank initializations typically yield smaller network changes indicative of lazier learning, a finding we also confirm with experimentally-driven initial connectivity in recurrent neural networks. Conversely, low-rank initialization biases learning towards richer learning. Importantly, however, as an exception to this rule, we find lazier learning can still occur with a low-rank initialization that aligns with task and data statistics. Our research highlights the pivotal role of initial weight structures in shaping learning regimes, with implications for metabolic costs of plasticity and risks of catastrophic forgetting.
Lookbehind Optimizer: k steps back, 1 step forward
Jul 31, 2023The Lookahead optimizer improves the training stability of deep neural networks by having a set of fast weights that "look ahead" to guide the descent direction. Here, we combine this idea with sharpness-aware minimization (SAM) to stabilize its multi-step variant and improve the loss-sharpness trade-off. We propose Lookbehind, which computes $k$ gradient ascent steps ("looking behind") at each iteration and combine the gradients to bias the descent step toward flatter minima. We apply Lookbehind on top of two popular sharpness-aware training methods -- SAM and adaptive SAM (ASAM) -- and show that our approach leads to a myriad of benefits across a variety of tasks and training regimes. Particularly, we show increased generalization performance, greater robustness against noisy weights, and higher tolerance to catastrophic forgetting in lifelong learning settings.
Promoting Exploration in Memory-Augmented Adam using Critical Momenta
Jul 18, 2023Adaptive gradient-based optimizers, particularly Adam, have left their mark in training large-scale deep learning models. The strength of such optimizers is that they exhibit fast convergence while being more robust to hyperparameter choice. However, they often generalize worse than non-adaptive methods. Recent studies have tied this performance gap to flat minima selection: adaptive methods tend to find solutions in sharper basins of the loss landscape, which in turn hurts generalization. To overcome this issue, we propose a new memory-augmented version of Adam that promotes exploration towards flatter minima by using a buffer of critical momentum terms during training. Intuitively, the use of the buffer makes the optimizer overshoot outside the basin of attraction if it is not wide enough. We empirically show that our method improves the performance of several variants of Adam on standard supervised language modelling and image classification tasks.
CrossSplit: Mitigating Label Noise Memorization through Data Splitting
Dec 03, 2022



We approach the problem of improving robustness of deep learning algorithms in the presence of label noise. Building upon existing label correction and co-teaching methods, we propose a novel training procedure to mitigate the memorization of noisy labels, called CrossSplit, which uses a pair of neural networks trained on two disjoint parts of the dataset. CrossSplit combines two main ingredients: (i) Cross-split label correction. The idea is that, since the model trained on one part of the data cannot memorize example-label pairs from the other part, the training labels presented to each network can be smoothly adjusted by using the predictions of its peer network; (ii) Cross-split semi-supervised training. A network trained on one part of the data also uses the unlabeled inputs of the other part. Extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet and mini-WebVision datasets demonstrate that our method can outperform the current state-of-the-art up to 90% noise ratio.