 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Forgetting Transformer: Softmax Attention with a Forget Gate
Mar 03, 2025An essential component of modern recurrent sequence models is the forget gate. While Transformers do not have an explicit recurrent form, we show that a forget gate can be naturally incorporated into Transformers by down-weighting the unnormalized attention scores in a data-dependent way. We name this attention mechanism the Forgetting Attention and the resulting model the Forgetting Transformer (FoX). We show that FoX outperforms the Transformer on long-context language modeling, length extrapolation, and short-context downstream tasks, while performing on par with the Transformer on long-context downstream tasks. Moreover, it is compatible with the FlashAttention algorithm and does not require any positional embeddings. Several analyses, including the needle-in-the-haystack test, show that FoX also retains the Transformer's superior long-context capabilities over recurrent sequence models such as Mamba-2, HGRN2, and DeltaNet. We also introduce a "Pro" block design that incorporates some common architectural components in recurrent sequence models and find it significantly improves the performance of both FoX and the Transformer. Our code is available at https://github.com/zhixuan-lin/forgetting-transformer.
The Curse of Diversity in Ensemble-Based Exploration
May 07, 2024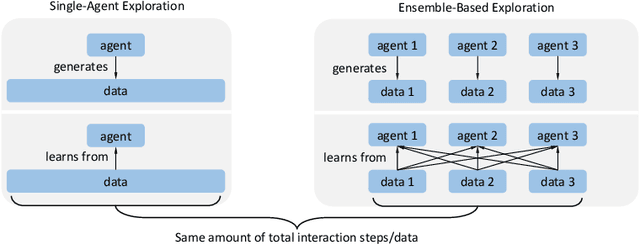


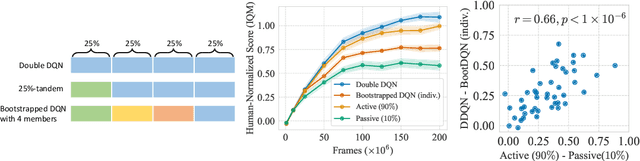
We uncover a surprising phenomenon in deep reinforcement learning: training a diverse ensemble of data-sharing agents -- a well-established exploration strategy -- can significantly impair the performance of the individual ensemble members when compared to standard single-agent training. Through careful analysis, we attribute the degradation in performance to the low proportion of self-generated data in the shared training data for each ensemble member, as well as the inefficiency of the individual ensemble members to learn from such highly off-policy data. We thus name this phenomenon the curse of diversity. We find that several intuitive solutions -- such as a larger replay buffer or a smaller ensemble size -- either fail to consistently mitigate the performance loss or undermine the advantages of ensembling. Finally, we demonstrate the potential of representation learning to counteract the curse of diversity with a novel method named Cross-Ensemble Representation Learning (CERL) in both discrete and continuous control domains. Our work offers valuable insights into an unexpected pitfall in ensemble-based exploration and raises important caveats for future applications of similar approaches.
Maxwell's Demon at Work: Efficient Pruning by Leveraging Saturation of Neurons
Mar 12, 2024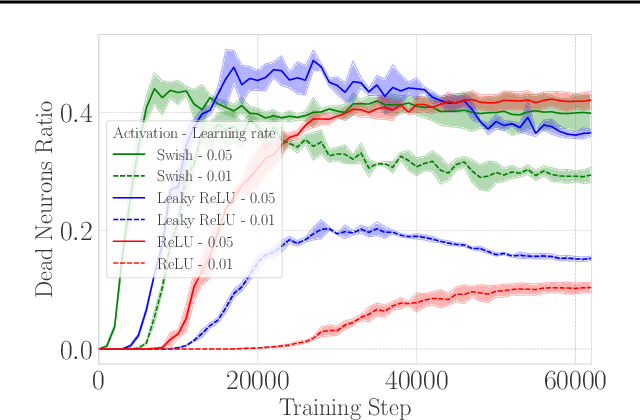
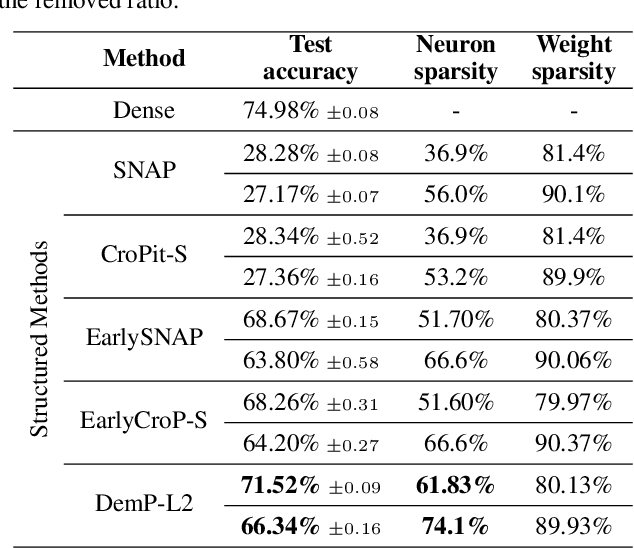
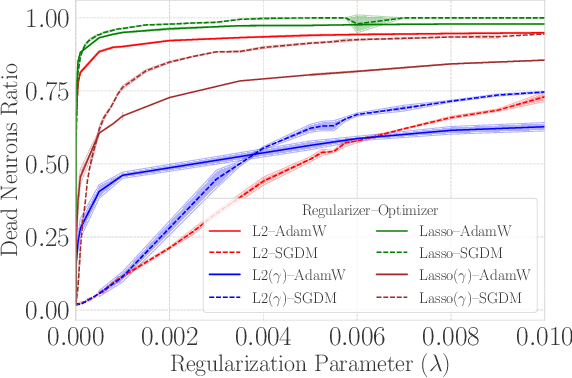
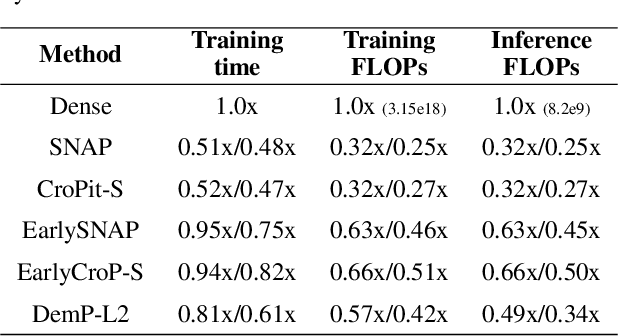
When training deep neural networks, the phenomenon of $\textit{dying neurons}$ $\unicode{x2013}$units that become inactive or saturated, output zero during training$\unicode{x2013}$ has traditionally been viewed as undesirable, linked with optimization challenges, and contributing to plasticity loss in continual learning scenarios. In this paper, we reassess this phenomenon, focusing on sparsity and pruning. By systematically exploring the impact of various hyperparameter configurations on dying neurons, we unveil their potential to facilitate simple yet effective structured pruning algorithms. We introduce $\textit{Demon Pruning}$ (DemP), a method that controls the proliferation of dead neurons, dynamically leading to network sparsity. Achieved through a combination of noise injection on active units and a one-cycled schedule regularization strategy, DemP stands out for its simplicity and broad applicability. Experiments on CIFAR10 and ImageNet datasets demonstrate that DemP surpasses existing structured pruning techniques, showcasing superior accuracy-sparsity tradeoffs and training speedups. These findings suggest a novel perspective on dying neurons as a valuable resource for efficient model compression and optimization.
Deep Reinforcement Learning with Plasticity Injection
May 24, 2023A growing body of evidence suggests that neural networks employed in deep reinforcement learning (RL) gradually lose their plasticity, the ability to learn from new data; however, the analysis and mitigation of this phenomenon is hampered by the complex relationship between plasticity, exploration, and performance in RL. This paper introduces plasticity injection, a minimalistic intervention that increases the network plasticity without changing the number of trainable parameters or biasing the predictions. The applications of this intervention are two-fold: first, as a diagnostic tool $\unicode{x2014}$ if injection increases the performance, we may conclude that an agent's network was losing its plasticity. This tool allows us to identify a subset of Atari environments where the lack of plasticity causes performance plateaus, motivating future studies on understanding and combating plasticity loss. Second, plasticity injection can be used to improve the computational efficiency of RL training if the agent has to re-learn from scratch due to exhausted plasticity or by growing the agent's network dynamically without compromising performance. The results on Atari show that plasticity injection attains stronger performance compared to alternative methods while being computationally efficient.
Understanding plasticity in neural networks
Mar 02, 2023
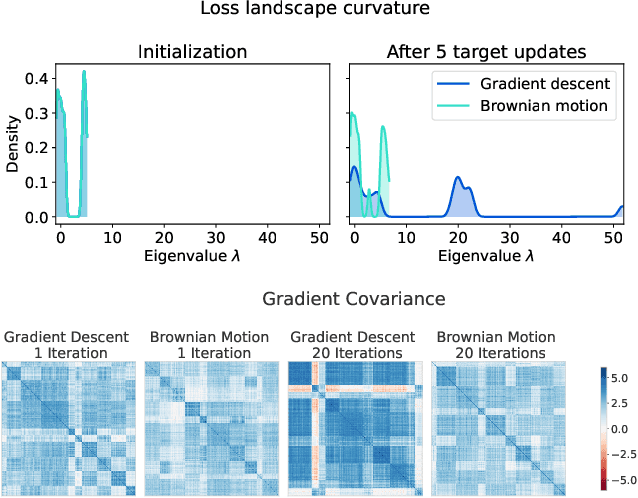
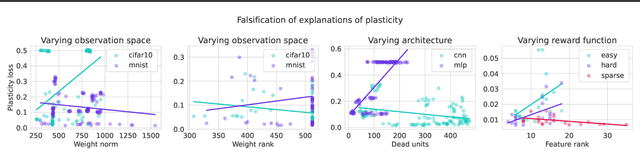

Plasticity, the ability of a neural network to quickly change its predictions in response to new information, is essential for the adaptability and robustness of deep reinforcement learning systems. Deep neural networks are known to lose plasticity over the course of training even in relatively simple learning problems, but the mechanisms driving this phenomenon are still poorly understood. This paper conducts a systematic empirical analysis into plasticity loss, with the goal of understanding the phenomenon mechanistically in order to guide the future development of targeted solutions. We find that loss of plasticity is deeply connected to changes in the curvature of the loss landscape, but that it typically occurs in the absence of saturated units or divergent gradient norms. Based on this insight, we identify a number of parameterization and optimization design choices which enable networks to better preserve plasticity over the course of training. We validate the utility of these findings in larger-scale learning problems by applying the best-performing intervention, layer normalization, to a deep RL agent trained on the Arcade Learning Environment.
The Primacy Bias in Deep Reinforcement Learning
May 16, 2022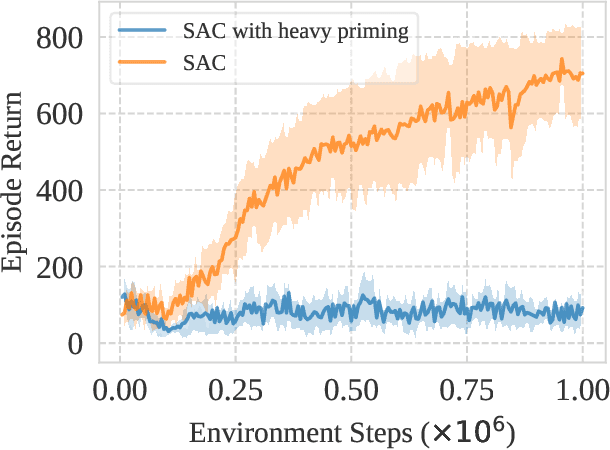
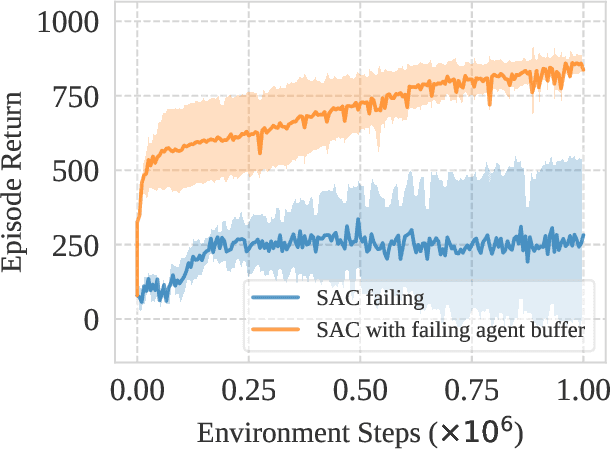
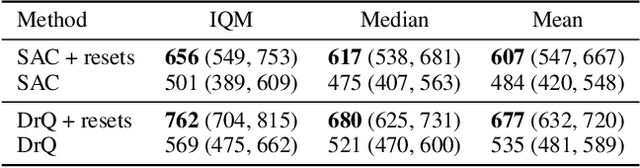

This work identifies a common flaw of deep reinforcement learning (RL) algorithms: a tendency to rely on early interactions and ignore useful evidence encountered later. Because of training on progressively growing datasets, deep RL agents incur a risk of overfitting to earlier experiences, negatively affecting the rest of the learning process. Inspired by cognitive science, we refer to this effect as the primacy bias. Through a series of experiments, we dissect the algorithmic aspects of deep RL that exacerbate this bias. We then propose a simple yet generally-applicable mechanism that tackles the primacy bias by periodically resetting a part of the agent. We apply this mechanism to algorithms in both discrete (Atari 100k) and continuous action (DeepMind Control Suite) domains, consistently improving their performance.
Quantifying and Understanding Adversarial Examples in Discrete Input Spaces
Dec 12, 2021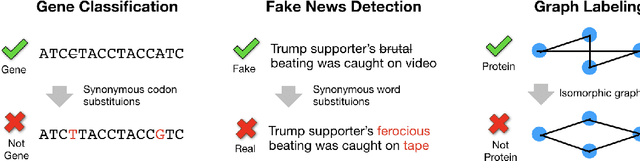
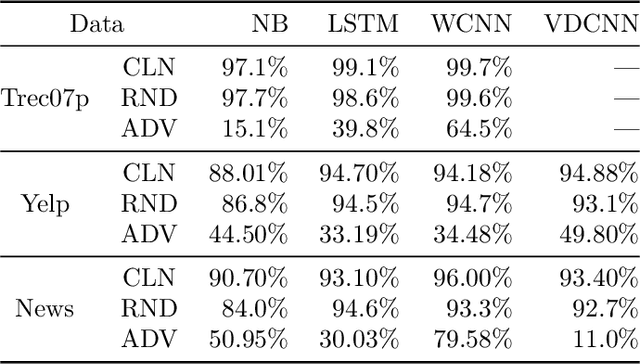


Modern classification algorithms are susceptible to adversarial examples--perturbations to inputs that cause the algorithm to produce undesirable behavior. In this work, we seek to understand and extend adversarial examples across domains in which inputs are discrete, particularly across new domains, such as computational biology. As a step towards this goal, we formalize a notion of synonymous adversarial examples that applies in any discrete setting and describe a simple domain-agnostic algorithm to construct such examples. We apply this algorithm across multiple domains--including sentiment analysis and DNA sequence classification--and find that it consistently uncovers adversarial examples. We seek to understand their prevalence theoretically and we attribute their existence to spurious token correlations, a statistical phenomenon that is specific to discrete spaces. Our work is a step towards a domain-agnostic treatment of discrete adversarial examples analogous to that of continuous inputs.
Control-Oriented Model-Based Reinforcement Learning with Implicit Differentiation
Jun 06, 2021
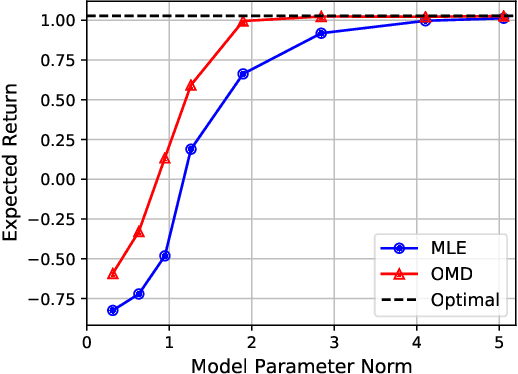
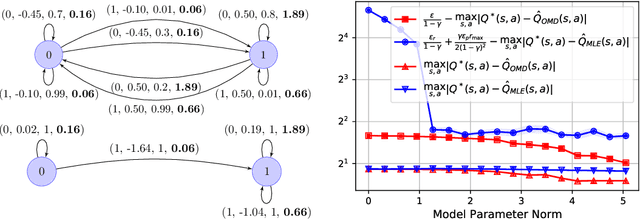
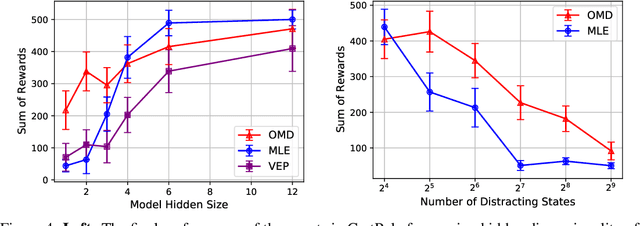
The shortcomings of maximum likelihood estimation in the context of model-based reinforcement learning have been highlighted by an increasing number of papers. When the model class is misspecified or has a limited representational capacity, model parameters with high likelihood might not necessarily result in high performance of the agent on a downstream control task. To alleviate this problem, we propose an end-to-end approach for model learning which directly optimizes the expected returns using implicit differentiation. We treat a value function that satisfies the Bellman optimality operator induced by the model as an implicit function of model parameters and show how to differentiate the function. We provide theoretical and empirical evidence highlighting the benefits of our approach in the model misspecification regime compared to likelihood-based methods.