 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorque-Aware Momentum
Dec 25, 2024Efficiently exploring complex loss landscapes is key to the performance of deep neural networks. While momentum-based optimizers are widely used in state-of-the-art setups, classical momentum can still struggle with large, misaligned gradients, leading to oscillations. To address this, we propose Torque-Aware Momentum (TAM), which introduces a damping factor based on the angle between the new gradients and previous momentum, stabilizing the update direction during training. Empirical results show that TAM, which can be combined with both SGD and Adam, enhances exploration, handles distribution shifts more effectively, and improves generalization performance across various tasks, including image classification and large language model fine-tuning, when compared to classical momentum-based optimizers.
Why Don't Prompt-Based Fairness Metrics Correlate?
Jun 09, 2024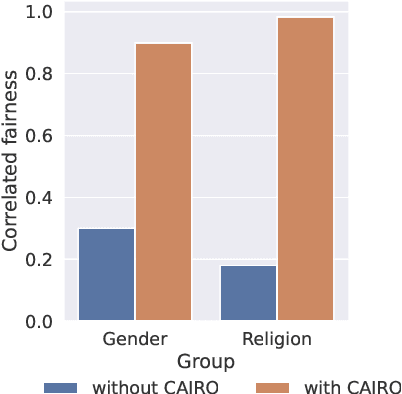

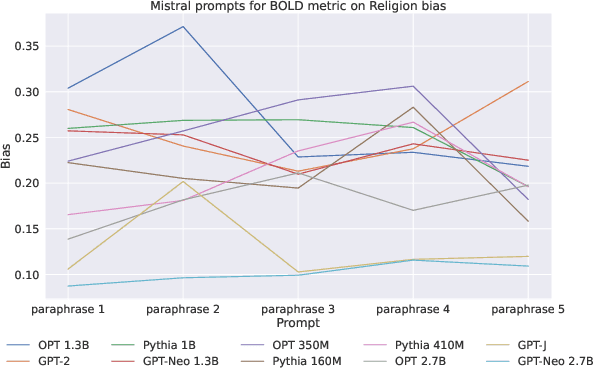
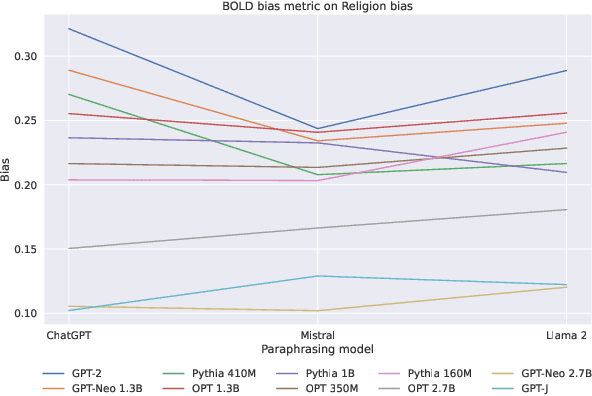
The widespread use of large language models has brought up essential questions about the potential biases these models might learn. This led to the development of several metrics aimed at evaluating and mitigating these biases. In this paper, we first demonstrate that prompt-based fairness metrics exhibit poor agreement, as measured by correlation, raising important questions about the reliability of fairness assessment using prompts. Then, we outline six relevant reasons why such a low correlation is observed across existing metrics. Based on these insights, we propose a method called Correlated Fairness Output (CAIRO) to enhance the correlation between fairness metrics. CAIRO augments the original prompts of a given fairness metric by using several pre-trained language models and then selects the combination of the augmented prompts that achieves the highest correlation across metrics. We show a significant improvement in Pearson correlation from 0.3 and 0.18 to 0.90 and 0.98 across metrics for gender and religion biases, respectively. Our code is available at https://github.com/chandar-lab/CAIRO.
Fairness-Aware Structured Pruning in Transformers
Dec 24, 2023The increasing size of large language models (LLMs) has introduced challenges in their training and inference. Removing model components is perceived as a solution to tackle the large model sizes, however, existing pruning methods solely focus on performance, without considering an essential aspect for the responsible use of LLMs: model fairness. It is crucial to address the fairness of LLMs towards diverse groups, such as women, Black people, LGBTQ+, Jewish communities, among others, as they are being deployed and available to a wide audience. In this work, first, we investigate how attention heads impact fairness and performance in pre-trained transformer-based language models. We then propose a novel method to prune the attention heads that negatively impact fairness while retaining the heads critical for performance, i.e. language modeling capabilities. Our approach is practical in terms of time and resources, as it does not require fine-tuning the final pruned, and fairer, model. Our findings demonstrate a reduction in gender bias by 19%, 19.5%, 39.5%, 34.7%, 23%, and 8% for DistilGPT-2, GPT-2, GPT-Neo of two different sizes, GPT-J, and Llama 2 models, respectively, in comparison to the biased model, with only a slight decrease in performance.
Should We Attend More or Less? Modulating Attention for Fairness
May 22, 2023

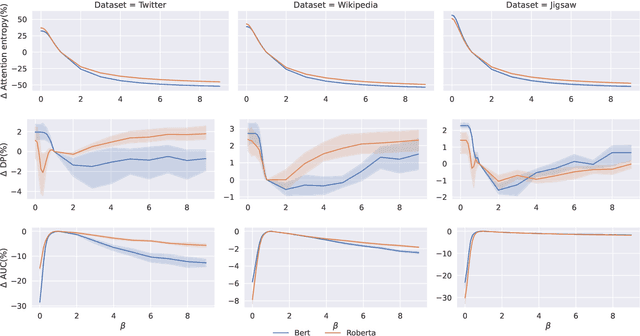
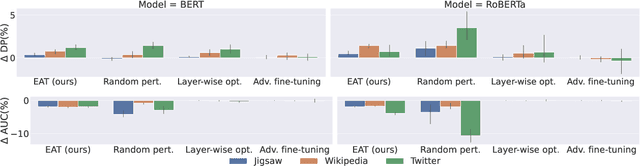
The abundance of annotated data in natural language processing (NLP) poses both opportunities and challenges. While it enables the development of high-performing models for a variety of tasks, it also poses the risk of models learning harmful biases from the data, such as gender stereotypes. In this work, we investigate the role of attention, a widely-used technique in current state-of-the-art NLP models, in the propagation of social biases. Specifically, we study the relationship between the entropy of the attention distribution and the model's performance and fairness. We then propose a novel method for modulating attention weights to improve model fairness after training. Since our method is only applied post-training and pre-inference, it is an intra-processing method and is, therefore, less computationally expensive than existing in-processing and pre-processing approaches. Our results show an increase in fairness and minimal performance loss on different text classification and generation tasks using language models of varying sizes. WARNING: This work uses language that is offensive.
Deep Learning on a Healthy Data Diet: Finding Important Examples for Fairness
Nov 25, 2022



Data-driven predictive solutions predominant in commercial applications tend to suffer from biases and stereotypes, which raises equity concerns. Prediction models may discover, use, or amplify spurious correlations based on gender or other protected personal characteristics, thus discriminating against marginalized groups. Mitigating gender bias has become an important research focus in natural language processing (NLP) and is an area where annotated corpora are available. Data augmentation reduces gender bias by adding counterfactual examples to the training dataset. In this work, we show that some of the examples in the augmented dataset can be not important or even harmful for fairness. We hence propose a general method for pruning both the factual and counterfactual examples to maximize the model's fairness as measured by the demographic parity, equality of opportunity, and equality of odds. The fairness achieved by our method surpasses that of data augmentation on three text classification datasets, using no more than half of the examples in the augmented dataset. Our experiments are conducted using models of varying sizes and pre-training settings.