 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Don't Prompt-Based Fairness Metrics Correlate?
Jun 09, 2024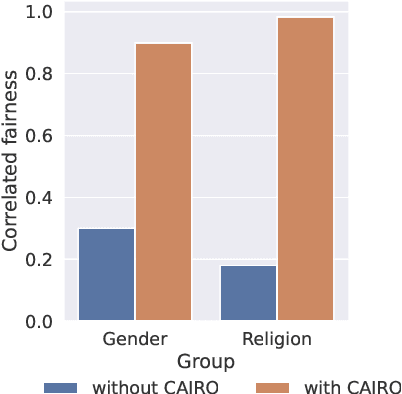

The widespread use of large language models has brought up essential questions about the potential biases these models might learn. This led to the development of several metrics aimed at evaluating and mitigating these biases. In this paper, we first demonstrate that prompt-based fairness metrics exhibit poor agreement, as measured by correlation, raising important questions about the reliability of fairness assessment using prompts. Then, we outline six relevant reasons why such a low correlation is observed across existing metrics. Based on these insights, we propose a method called Correlated Fairness Output (CAIRO) to enhance the correlation between fairness metrics. CAIRO augments the original prompts of a given fairness metric by using several pre-trained language models and then selects the combination of the augmented prompts that achieves the highest correlation across metrics. We show a significant improvement in Pearson correlation from 0.3 and 0.18 to 0.90 and 0.98 across metrics for gender and religion biases, respectively. Our code is available at https://github.com/chandar-lab/CAIRO.
Fairness-Aware Structured Pruning in Transformers
Dec 24, 2023The increasing size of large language models (LLMs) has introduced challenges in their training and inference. Removing model components is perceived as a solution to tackle the large model sizes, however, existing pruning methods solely focus on performance, without considering an essential aspect for the responsible use of LLMs: model fairness. It is crucial to address the fairness of LLMs towards diverse groups, such as women, Black people, LGBTQ+, Jewish communities, among others, as they are being deployed and available to a wide audience. In this work, first, we investigate how attention heads impact fairness and performance in pre-trained transformer-based language models. We then propose a novel method to prune the attention heads that negatively impact fairness while retaining the heads critical for performance, i.e. language modeling capabilities. Our approach is practical in terms of time and resources, as it does not require fine-tuning the final pruned, and fairer, model. Our findings demonstrate a reduction in gender bias by 19%, 19.5%, 39.5%, 34.7%, 23%, and 8% for DistilGPT-2, GPT-2, GPT-Neo of two different sizes, GPT-J, and Llama 2 models, respectively, in comparison to the biased model, with only a slight decrease in performance.
Should We Attend More or Less? Modulating Attention for Fairness
May 22, 2023

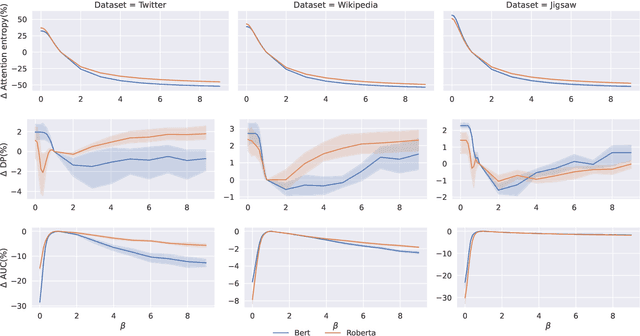
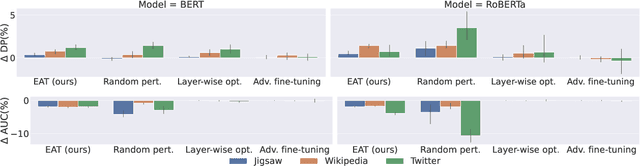
The abundance of annotated data in natural language processing (NLP) poses both opportunities and challenges. While it enables the development of high-performing models for a variety of tasks, it also poses the risk of models learning harmful biases from the data, such as gender stereotypes. In this work, we investigate the role of attention, a widely-used technique in current state-of-the-art NLP models, in the propagation of social biases. Specifically, we study the relationship between the entropy of the attention distribution and the model's performance and fairness. We then propose a novel method for modulating attention weights to improve model fairness after training. Since our method is only applied post-training and pre-inference, it is an intra-processing method and is, therefore, less computationally expensive than existing in-processing and pre-processing approaches. Our results show an increase in fairness and minimal performance loss on different text classification and generation tasks using language models of varying sizes. WARNING: This work uses language that is offensive.
Deep Learning on a Healthy Data Diet: Finding Important Examples for Fairness
Nov 25, 2022



Data-driven predictive solutions predominant in commercial applications tend to suffer from biases and stereotypes, which raises equity concerns. Prediction models may discover, use, or amplify spurious correlations based on gender or other protected personal characteristics, thus discriminating against marginalized groups. Mitigating gender bias has become an important research focus in natural language processing (NLP) and is an area where annotated corpora are available. Data augmentation reduces gender bias by adding counterfactual examples to the training dataset. In this work, we show that some of the examples in the augmented dataset can be not important or even harmful for fairness. We hence propose a general method for pruning both the factual and counterfactual examples to maximize the model's fairness as measured by the demographic parity, equality of opportunity, and equality of odds. The fairness achieved by our method surpasses that of data augmentation on three text classification datasets, using no more than half of the examples in the augmented dataset. Our experiments are conducted using models of varying sizes and pre-training settings.
Fast Strain Estimation and Frame Selection in Ultrasound Elastography using Machine Learning
Oct 16, 2021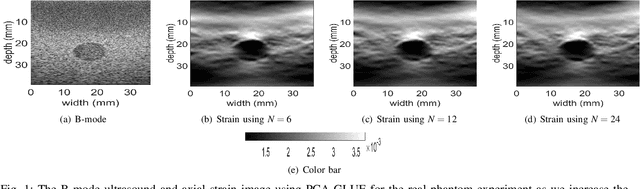
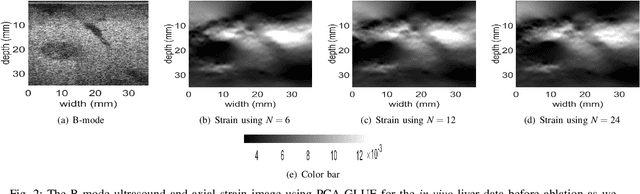
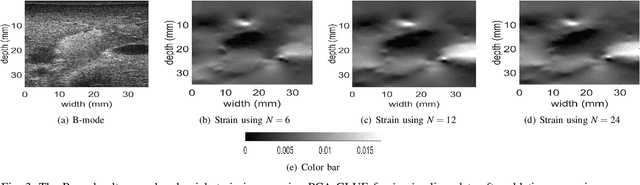
Ultrasound Elastography aims to determine the mechanical properties of the tissue by monitoring tissue deformation due to internal or external forces. Tissue deformations are estimated from ultrasound radio frequency (RF) signals and are often referred to as time delay estimation (TDE). Given two RF frames I1 and I2, we can compute a displacement image which shows the change in the position of each sample in I1 to a new position in I2. Two important challenges in TDE include high computational complexity and the difficulty in choosing suitable RF frames. Selecting suitable frames is of high importance because many pairs of RF frames either do not have acceptable deformation for extracting informative strain images or are decorrelated and deformation cannot be reliably estimated. Herein, we introduce a method that learns 12 displacement modes in quasi-static elastography by performing Principal Component Analysis (PCA) on displacement fields of a large training database. In the inference stage, we use dynamic programming (DP) to compute an initial displacement estimate of around 1% of the samples, and then decompose this sparse displacement into a linear combination of the 12 displacement modes. Our method assumes that the displacement of the whole image could also be described by this linear combination of principal components. We then use the GLobal Ultrasound Elastography (GLUE) method to fine-tune the result yielding the exact displacement image. Our method, which we call PCA-GLUE, is more than 10 times faster than DP in calculating the initial displacement map while giving the same result. Our second contribution in this paper is determining the suitability of the frame pair I1 and I2 for strain estimation, which we achieve by using the weight vector that we calculated for PCA-GLUE as an input to a multi-layer perceptron (MLP) classifier.
Automatic Frame Selection using CNN in Ultrasound Elastography
Feb 17, 2020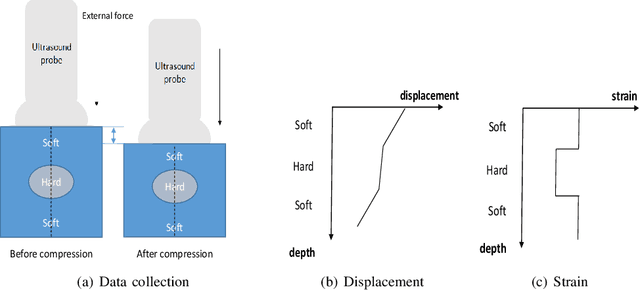
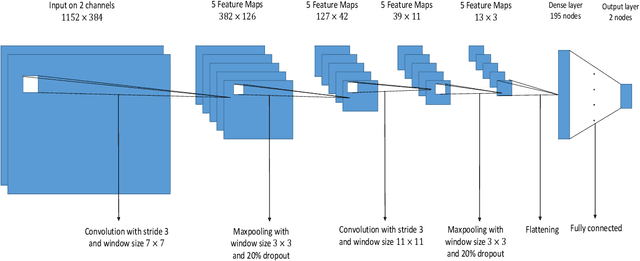
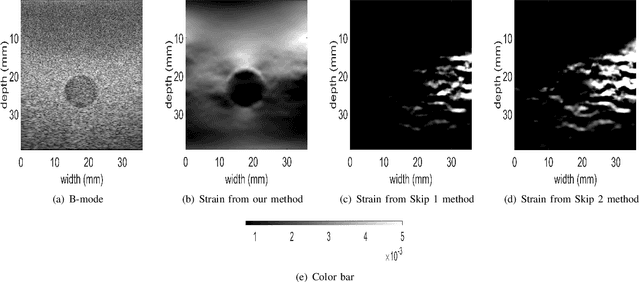

Ultrasound elastography is used to estimate the mechanical properties of the tissue by monitoring its response to an internal or external force. Different levels of deformation are obtained from different tissue types depending on their mechanical properties, where stiffer tissues deform less. Given two radio frequency (RF) frames collected before and after some deformation, we estimate displacement and strain images by comparing the RF frames. The quality of the strain image is dependent on the type of motion that occurs during deformation. In-plane axial motion results in high-quality strain images, whereas out-of-plane motion results in low-quality strain images. In this paper, we introduce a new method using a convolutional neural network (CNN) to determine the suitability of a pair of RF frames for elastography in only 5.4 ms. Our method could also be used to automatically choose the best pair of RF frames, yielding a high-quality strain image. The CNN was trained on 3,818 pairs of RF frames, while testing was done on 986 new unseen pairs, achieving an accuracy of more than 91%. The RF frames were collected from both phantom and in vivo data.
Automatic Frame Selection Using MLP Neural Network in Ultrasound Elastography
Nov 13, 2019



Ultrasound elastography estimates the mechanical properties of the tissue from two Radio-Frequency (RF) frames collected before and after tissue deformation due to an external or internal force. This work focuses on strain imaging in quasi-static elastography, where the tissue undergoes slow deformations and strain images are estimated as a surrogate for elasticity modulus. The quality of the strain image depends heavily on the underlying deformation, and even the best strain estimation algorithms cannot estimate a good strain image if the underlying deformation is not suitable. Herein, we introduce a new method for tracking the RF frames and selecting automatically the best possible pair. We achieve this by decomposing the axial displacement image into a linear combination of principal components (which are calculated offline) multiplied by their corresponding weights. We then use the calculated weights as the input feature vector to a multi-layer perceptron (MLP) classifier. The output is a binary decision, either 1 which refers to good frames, or 0 which refers to bad frames. Our MLP model is trained on in-vivo dataset and tested on different datasets of both in-vivo and phantom data. Results show that by using our technique, we would be able to achieve higher quality strain images compared to the traditional methods of picking up pairs that are 1, 2 or 3 frames apart. The training phase of our algorithm is computationally expensive and takes few hours, but it is only done once. The testing phase chooses the optimal pair of frames in only 1.9 ms.
Fast Approximate Time-Delay Estimation in Ultrasound Elastography Using Principal Component Analysis
Nov 13, 2019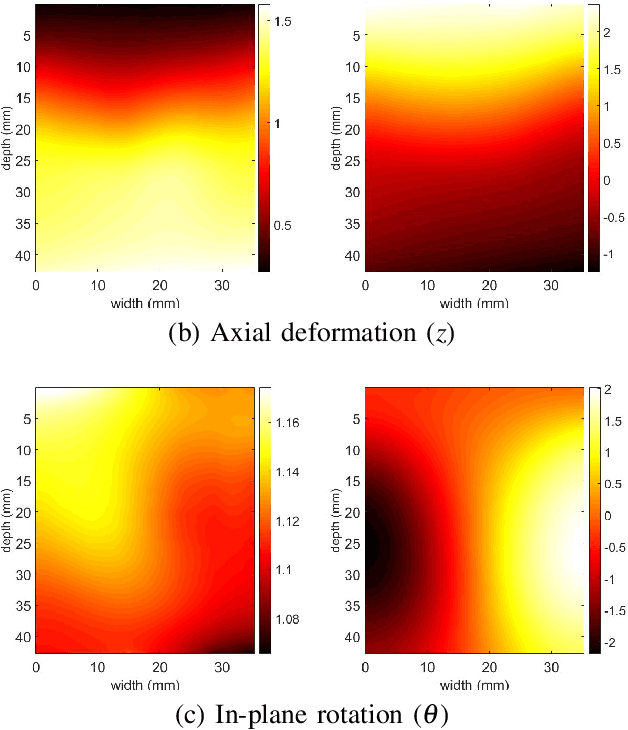
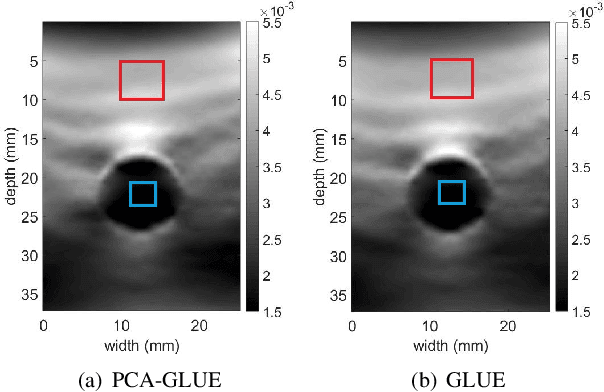
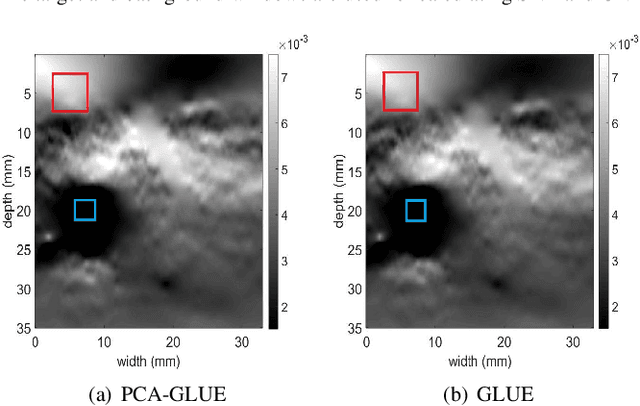

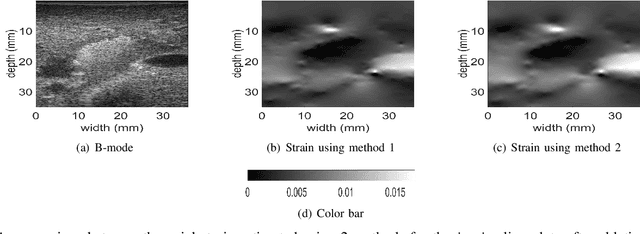
Time delay estimation (TDE) is a critical and challenging step in all ultrasound elastography methods. A growing number of TDE techniques require an approximate but robust and fast method to initialize solving for TDE. Herein, we present a fast method for calculating an approximate TDE between two radio frequency (RF) frames of ultrasound. Although this approximate TDE can be useful for several algorithms, we focus on GLobal Ultrasound Elastography (GLUE), which currently relies on Dynamic Programming (DP) to provide this approximate TDE. We exploit Principal Component Analysis (PCA) to find the general modes of deformation in quasi-static elastography, and therefore call our method PCA-GLUE. PCA-GLUE is a data-driven approach that learns a set of TDE principal components from a training database in real experiments. In the test phase, TDE is approximated as a weighted sum of these principal components. Our algorithm robustly estimates the weights from sparse feature matches, then passes the resulting displacement field to GLUE as initial estimates to perform a more accurate displacement estimation. PCA-GLUE is more than ten times faster than DP in estimation of the initial displacement field and yields similar results.
* Accepted to be Published in 2019, 41th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany