 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould We Attend More or Less? Modulating Attention for Fairness
Paper and Code
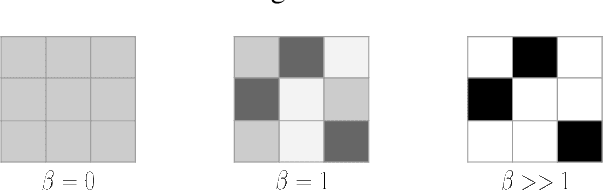

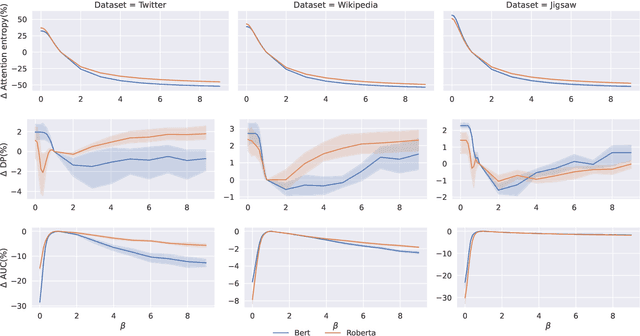
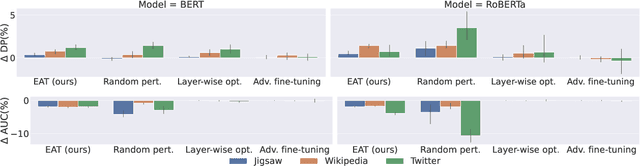
The abundance of annotated data in natural language processing (NLP) poses both opportunities and challenges. While it enables the development of high-performing models for a variety of tasks, it also poses the risk of models learning harmful biases from the data, such as gender stereotypes. In this work, we investigate the role of attention, a widely-used technique in current state-of-the-art NLP models, in the propagation of social biases. Specifically, we study the relationship between the entropy of the attention distribution and the model's performance and fairness. We then propose a novel method for modulating attention weights to improve model fairness after training. Since our method is only applied post-training and pre-inference, it is an intra-processing method and is, therefore, less computationally expensive than existing in-processing and pre-processing approaches. Our results show an increase in fairness and minimal performance loss on different text classification and generation tasks using language models of varying sizes. WARNING: This work uses language that is offensive.