 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mode-Seeking RL: Trajectory-Balance Post-Training for Diffusion Language Models
May 13, 2026Diffusion language models are a promising alternative to autoregressive models, yet post-training methods for them largely adapt reward-maximizing objectives. We identify a central failure mode in this setting we call trajectory locking: sampled reward-driven updates over-concentrate probability mass onto a narrow set of denoising paths, reducing coverage of alternative correct solutions under repeated sampling. To address this, we propose TraFL (Trajectory Flow baLancing), a trajectory-balance objective that trains the policy toward a reward-tilted target distribution anchored to a frozen reference model. We make this practical for diffusion language models with a diffusion-compatible sequence-level surrogate and a learned prompt-dependent normalization. Across mathematical reasoning and code generation benchmarks, TraFL is the only evaluated post-training method that improves over the base model in every benchmark-length setting, with gains that persist as the sampling budget increases. The improvements transfer to held-out evaluations: TraFL stays above the base model on Minerva Math and is the strongest method on every LiveCodeBench difficulty split.
InfMem: Learning System-2 Memory Control for Long-Context Agent
Feb 02, 2026Reasoning over ultra-long documents requires synthesizing sparse evidence scattered across distant segments under strict memory constraints. While streaming agents enable scalable processing, their passive memory update strategy often fails to preserve low-salience bridging evidence required for multi-hop reasoning. We propose InfMem, a control-centric agent that instantiates System-2-style control via a PreThink-Retrieve-Write protocol. InfMem actively monitors evidence sufficiency, performs targeted in-document retrieval, and applies evidence-aware joint compression to update a bounded memory. To ensure reliable control, we introduce a practical SFT-to-RL training recipe that aligns retrieval, writing, and stopping decisions with end-task correctness. On ultra-long QA benchmarks from 32k to 1M tokens, InfMem consistently outperforms MemAgent across backbones. Specifically, InfMem improves average absolute accuracy by +10.17, +11.84, and +8.23 points on Qwen3-1.7B, Qwen3-4B, and Qwen2.5-7B, respectively, while reducing inference time by $3.9\times$ on average (up to $5.1\times$) via adaptive early stopping.
Thinking Long, but Short: Stable Sequential Test-Time Scaling for Large Reasoning Models
Jan 14, 2026Sequential test-time scaling is a promising training-free method to improve large reasoning model accuracy, but as currently implemented, significant limitations have been observed. Inducing models to think for longer can increase their accuracy, but as the length of reasoning is further extended, it has also been shown to result in accuracy degradation and model instability. This work presents a novel sequential test-time scaling method, Min-Seek, which improves model accuracy significantly over a wide range of induced thoughts, stabilizing the accuracy of sequential scaling, and removing the need for reasoning length fine-tuning. Beyond improving model accuracy over a variety of reasoning tasks, our method is inherently efficient, as only the KV pairs of one additional induced thought are kept in the KV cache during reasoning. With a custom KV cache which stores keys without position embeddings, by dynamically encoding them contiguously before each new generated thought, our method can continue to reason well beyond a model's maximum context length, and under mild conditions has linear computational complexity.
Nested-ReFT: Efficient Reinforcement Learning for Large Language Model Fine-Tuning via Off-Policy Rollouts
Aug 13, 2025Advanced reasoning in LLMs on challenging domains like mathematical reasoning can be tackled using verifiable rewards based reinforced fine-tuning (ReFT). In standard ReFT frameworks, a behavior model generates multiple completions with answers per problem, for the answer to be then scored by a reward function. While such RL post-training methods demonstrate significant performance improvements across challenging reasoning domains, the computational cost of generating completions during training with multiple inference steps makes the training cost non-trivial. To address this, we draw inspiration from off-policy RL, and speculative decoding to introduce a novel ReFT framework, dubbed Nested-ReFT, where a subset of layers of the target model acts as the behavior model to generate off-policy completions during training. The behavior model configured with dynamic layer skipping per batch during training decreases the inference cost compared to the standard ReFT frameworks. Our theoretical analysis shows that Nested-ReFT yields unbiased gradient estimates with controlled variance. Our empirical analysis demonstrates improved computational efficiency measured as tokens/sec across multiple math reasoning benchmarks and model sizes. Additionally, we explore three variants of bias mitigation to minimize the off-policyness in the gradient updates that allows for maintaining performance that matches the baseline ReFT performance.
Resona: Improving Context Copying in Linear Recurrence Models with Retrieval
Mar 28, 2025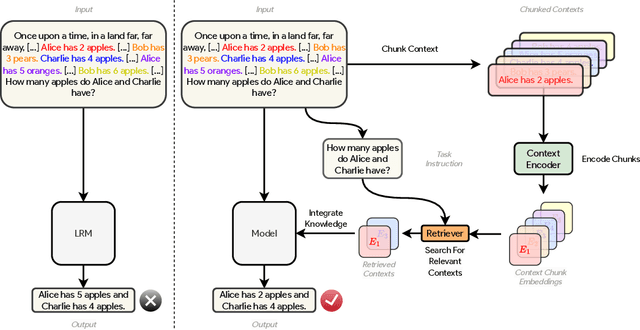

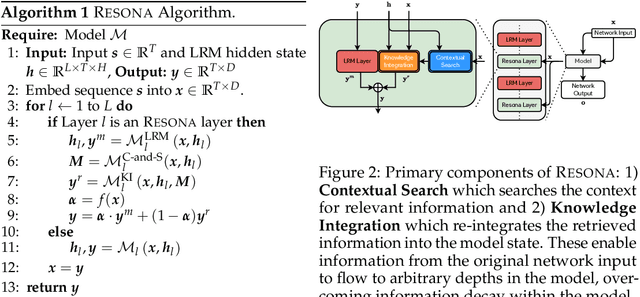
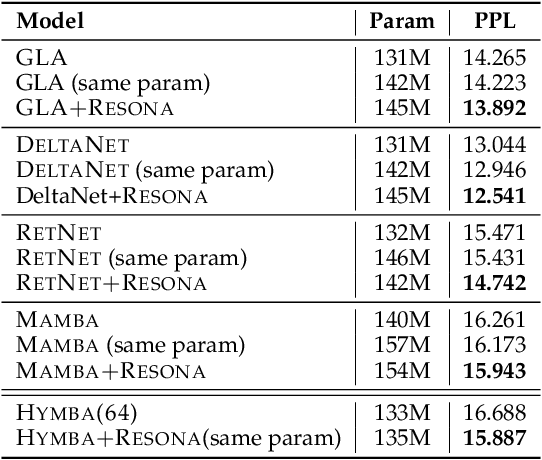
Recent shifts in the space of large language model (LLM) research have shown an increasing focus on novel architectures to compete with prototypical Transformer-based models that have long dominated this space. Linear recurrent models have proven to be a viable competitor due to their computational efficiency. However, such models still demonstrate a sizable gap compared to Transformers in terms of in-context learning among other tasks that require recalling information from a context. In this work, we introduce __Resona__, a simple and scalable framework for augmenting linear recurrent models with retrieval. __Resona__~augments models with the ability to integrate retrieved information from the provided input context, enabling tailored behavior to diverse task requirements. Experiments on a variety of linear recurrent models demonstrate that __Resona__-augmented models observe significant performance gains on a variety of synthetic as well as real-world natural language tasks, highlighting its ability to act as a general purpose method to improve the in-context learning and language modeling abilities of linear recurrent LLMs.
Do Robot Snakes Dream like Electric Sheep? Investigating the Effects of Architectural Inductive Biases on Hallucination
Oct 22, 2024



The growth in prominence of large language models (LLMs) in everyday life can be largely attributed to their generative abilities, yet some of this is also owed to the risks and costs associated with their use. On one front is their tendency to \textit{hallucinate} false or misleading information, limiting their reliability. On another is the increasing focus on the computational limitations associated with traditional self-attention based LLMs, which has brought about new alternatives, in particular recurrent models, meant to overcome them. Yet it remains uncommon to consider these two concerns simultaneously. Do changes in architecture exacerbate/alleviate existing concerns about hallucinations? Do they affect how and where they occur? Through an extensive evaluation, we study how these architecture-based inductive biases affect the propensity to hallucinate. While hallucination remains a general phenomenon not limited to specific architectures, the situations in which they occur and the ease with which specific types of hallucinations can be induced can significantly differ based on the model architecture. These findings highlight the need for better understanding both these problems in conjunction with each other, as well as consider how to design more universal techniques for handling hallucinations.
Context-Aware Assistant Selection for Improved Inference Acceleration with Large Language Models
Aug 16, 2024Despite their widespread adoption, large language models (LLMs) remain prohibitive to use under resource constraints, with their ever growing sizes only increasing the barrier for use. One noted issue is the high latency associated with auto-regressive generation, rendering large LLMs use dependent on advanced computing infrastructure. Assisted decoding, where a smaller draft model guides a larger target model's generation, has helped alleviate this, but remains dependent on alignment between the two models. Thus if the draft model is insufficiently capable on some domain relative to the target model, performance can degrade. Alternatively, one can leverage multiple draft models to better cover the expertise of the target, but when multiple black-box draft models are available, selecting an assistant without details about its construction can be difficult. To better understand this decision making problem, we observe it as a contextual bandit, where a policy must choose a draft model based on a context. We show that even without prior knowledge of the draft models, creating an offline dataset from only outputs of independent draft/target models and training a policy over the alignment of these outputs can accelerate performance on multiple domains provided the candidates are effective. Further results show this to hold on various settings with multiple assisted decoding candidates, highlighting its flexibility and the advantageous role that such decision making can play.
EWEK-QA: Enhanced Web and Efficient Knowledge Graph Retrieval for Citation-based Question Answering Systems
Jun 14, 2024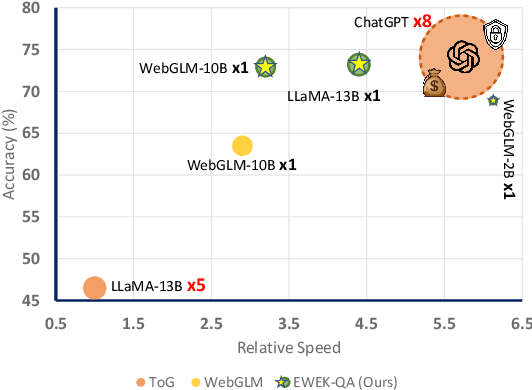
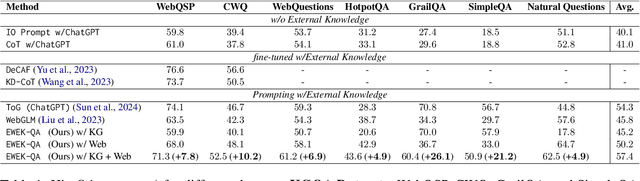
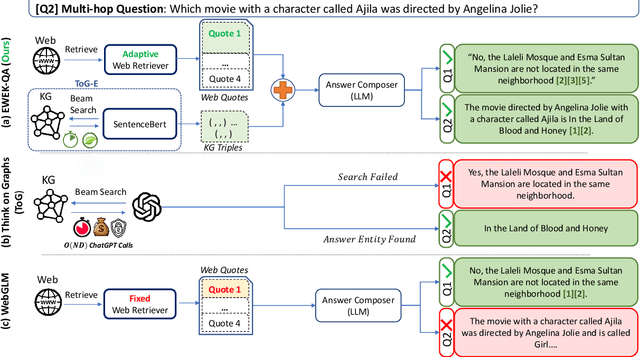
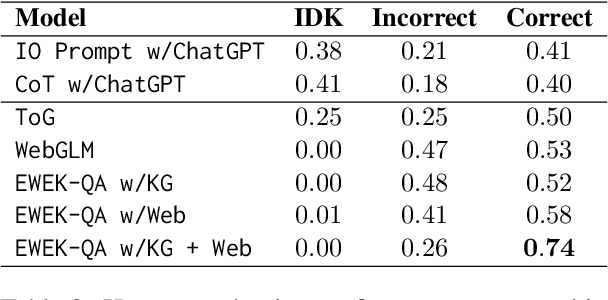
The emerging citation-based QA systems are gaining more attention especially in generative AI search applications. The importance of extracted knowledge provided to these systems is vital from both accuracy (completeness of information) and efficiency (extracting the information in a timely manner). In this regard, citation-based QA systems are suffering from two shortcomings. First, they usually rely only on web as a source of extracted knowledge and adding other external knowledge sources can hamper the efficiency of the system. Second, web-retrieved contents are usually obtained by some simple heuristics such as fixed length or breakpoints which might lead to splitting information into pieces. To mitigate these issues, we propose our enhanced web and efficient knowledge graph (KG) retrieval solution (EWEK-QA) to enrich the content of the extracted knowledge fed to the system. This has been done through designing an adaptive web retriever and incorporating KGs triples in an efficient manner. We demonstrate the effectiveness of EWEK-QA over the open-source state-of-the-art (SoTA) web-based and KG baseline models using a comprehensive set of quantitative and human evaluation experiments. Our model is able to: first, improve the web-retriever baseline in terms of extracting more relevant passages (>20\%), the coverage of answer span (>25\%) and self containment (>35\%); second, obtain and integrate KG triples into its pipeline very efficiently (by avoiding any LLM calls) to outperform the web-only and KG-only SoTA baselines significantly in 7 quantitative QA tasks and our human evaluation.
CHARP: Conversation History AwaReness Probing for Knowledge-grounded Dialogue Systems
May 24, 2024



In this work, we dive deep into one of the popular knowledge-grounded dialogue benchmarks that focus on faithfulness, FaithDial. We show that a significant portion of the FaithDial data contains annotation artifacts, which may bias models towards completely ignoring the conversation history. We therefore introduce CHARP, a diagnostic test set, designed for an improved evaluation of hallucinations in conversational model. CHARP not only measures hallucination but also the compliance of the models to the conversation task. Our extensive analysis reveals that models primarily exhibit poor performance on CHARP due to their inability to effectively attend to and reason over the conversation history. Furthermore, the evaluation methods of FaithDial fail to capture these shortcomings, neglecting the conversational history. Our findings indicate that there is substantial room for contribution in both dataset creation and hallucination evaluation for knowledge-grounded dialogue, and that CHARP can serve as a tool for monitoring the progress in this particular research area. CHARP is publicly available at https://huggingface.co/datasets/huawei-noah/CHARP
Towards Practical Tool Usage for Continually Learning LLMs
Apr 14, 2024Large language models (LLMs) show an innate skill for solving language based tasks. But insights have suggested an inability to adjust for information or task-solving skills becoming outdated, as their knowledge, stored directly within their parameters, remains static in time. Tool use helps by offloading work to systems that the LLM can access through an interface, but LLMs that use them still must adapt to nonstationary environments for prolonged use, as new tools can emerge and existing tools can change. Nevertheless, tools require less specialized knowledge, therefore we hypothesize they are better suited for continual learning (CL) as they rely less on parametric memory for solving tasks and instead focus on learning when to apply pre-defined tools. To verify this, we develop a synthetic benchmark and follow this by aggregating existing NLP tasks to form a more realistic testing scenario. While we demonstrate scaling model size is not a solution, regardless of tool usage, continual learning techniques can enable tool LLMs to both adapt faster while forgetting less, highlighting their potential as continual learners.