 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Languages Unintelligible to Multilingual Models through Local Structure Probes
Nov 09, 2022



Providing better language tools for low-resource and endangered languages is imperative for equitable growth. Recent progress with massively multilingual pretrained models has proven surprisingly effective at performing zero-shot transfer to a wide variety of languages. However, this transfer is not universal, with many languages not currently understood by multilingual approaches. It is estimated that only 72 languages possess a "small set of labeled datasets" on which we could test a model's performance, the vast majority of languages not having the resources available to simply evaluate performances on. In this work, we attempt to clarify which languages do and do not currently benefit from such transfer. To that end, we develop a general approach that requires only unlabelled text to detect which languages are not well understood by a cross-lingual model. Our approach is derived from the hypothesis that if a model's understanding is insensitive to perturbations to text in a language, it is likely to have a limited understanding of that language. We construct a cross-lingual sentence similarity task to evaluate our approach empirically on 350, primarily low-resource, languages.
Local Structure Matters Most in Most Languages
Nov 09, 2022



Many recent perturbation studies have found unintuitive results on what does and does not matter when performing Natural Language Understanding (NLU) tasks in English. Coding properties, such as the order of words, can often be removed through shuffling without impacting downstream performances. Such insight may be used to direct future research into English NLP models. As many improvements in multilingual settings consist of wholesale adaptation of English approaches, it is important to verify whether those studies replicate or not in multilingual settings. In this work, we replicate a study on the importance of local structure, and the relative unimportance of global structure, in a multilingual setting. We find that the phenomenon observed on the English language broadly translates to over 120 languages, with a few caveats.
FIGR: Few-shot Image Generation with Reptile
Jan 08, 2019
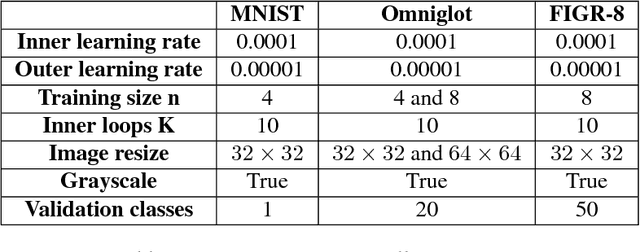


Generative Adversarial Networks (GAN) boast impressive capacity to generate realistic images. However, like much of the field of deep learning, they require an inordinate amount of data to produce results, thereby limiting their usefulness in generating novelty. In the same vein, recent advances in meta-learning have opened the door to many few-shot learning applications. In the present work, we propose Few-shot Image Generation using Reptile (FIGR), a GAN meta-trained with Reptile. Our model successfully generates novel images on both MNIST and Omniglot with as little as 4 images from an unseen class. We further contribute FIGR-8, a new dataset for few-shot image generation, which contains 1,548,944 icons categorized in over 18,409 classes. Trained on FIGR-8, initial results show that our model can generalize to more advanced concepts (such as "bird" and "knife") from as few as 8 samples from a previously unseen class of images and as little as 10 training steps through those 8 images. This work demonstrates the potential of training a GAN for few-shot image generation and aims to set a new benchmark for future work in the domain.