 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIS-Digger: Towards Comprehensive Research Agent Systems for Real-world Unindexed Information Seeking
Mar 11, 2026Recent advancements in LLM-based information-seeking agents have achieved record-breaking performance on established benchmarks. However, these agents remain heavily reliant on search-engine-indexed knowledge, leaving a critical blind spot: Unindexed Information Seeking (UIS). This paper identifies and explores the UIS problem, where vital information is not captured by search engine crawlers, such as overlooked content, dynamic webpages, and embedded files. Despite its significance, UIS remains an underexplored challenge. To address this gap, we introduce UIS-QA, the first dedicated UIS benchmark, comprising 110 expert-annotated QA pairs. Notably, even state-of-the-art agents experience a drastic performance drop on UIS-QA (e.g., from 70.90 on GAIA and 46.70 on BrowseComp-zh to 24.55 on UIS-QA), underscoring the severity of the problem. To mitigate this, we propose UIS-Digger, a novel multi-agent framework that incorporates dual-mode browsing and enables simultaneous webpage searching and file parsing. With a relatively small $\sim$30B-parameter backbone LLM optimized using SFT and RFT training strategies, UIS-Digger sets a strong baseline at 27.27\%, outperforming systems integrating sophisticated LLMs such as O3 and GPT-4.1. This demonstrates the importance of proactive interaction with unindexed sources for effective and comprehensive information-seeking. Our work not only uncovers a fundamental limitation in current agent evaluation paradigms but also provides the first toolkit for advancing UIS research, defining a new and promising direction for robust information-seeking systems.
Gradually Excavating External Knowledge for Implicit Complex Question Answering
Mar 09, 2026Recently, large language models (LLMs) have gained much attention for the emergence of human-comparable capabilities and huge potential. However, for open-domain implicit question-answering problems, LLMs may not be the ultimate solution due to the reasons of: 1) uncovered or out-of-date domain knowledge, 2) one-shot generation and hence restricted comprehensiveness. To this end, this work proposes a gradual knowledge excavation framework for open-domain complex question answering, where LLMs iteratively and actively acquire external information, and then reason based on acquired historical knowledge. Specifically, during each step of the solving process, the model selects an action to execute, such as querying external knowledge or performing a single logical reasoning step, to gradually progress toward a final answer. Our method can effectively leverage plug-and-play external knowledge and dynamically adjust the strategy for solving complex questions. Evaluated on the StrategyQA dataset, our method achieves 78.17% accuracy with less than 6% parameters of its competitors, setting new SOTA for ~10B-scale LLMs.
DLLM Agent: See Farther, Run Faster
Feb 07, 2026Diffusion large language models (DLLMs) have emerged as an alternative to autoregressive (AR) decoding with appealing efficiency and modeling properties, yet their implications for agentic multi-step decision making remain underexplored. We ask a concrete question: when the generation paradigm is changed but the agent framework and supervision are held fixed, do diffusion backbones induce systematically different planning and tool-use behaviors, and do these differences translate into end-to-end efficiency gains? We study this in a controlled setting by instantiating DLLM and AR backbones within the same agent workflow (DeepDiver) and performing matched agent-oriented fine-tuning on the same trajectory data, yielding diffusion-backed DLLM Agents and directly comparable AR agents. Across benchmarks and case studies, we find that, at comparable accuracy, DLLM Agents are on average over 30% faster end to end than AR agents, with some cases exceeding 8x speedup. Conditioned on correct task completion, DLLM Agents also require fewer interaction rounds and tool invocations, consistent with higher planner hit rates that converge earlier to a correct action path with less backtracking. We further identify two practical considerations for deploying diffusion backbones in tool-using agents. First, naive DLLM policies are more prone to structured tool-call failures, necessitating stronger tool-call-specific training to emit valid schemas and arguments. Second, for multi-turn inputs interleaving context and action spans, diffusion-style span corruption requires aligned attention masking to avoid spurious context-action information flow; without such alignment, performance degrades. Finally, we analyze attention dynamics across workflow stages and observe paradigm-specific coordination patterns, suggesting stronger global planning signals in diffusion-backed agents.
ReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
Pangu DeepDiver: Adaptive Search Intensity Scaling via Open-Web Reinforcement Learning
May 30, 2025Information seeking demands iterative evidence gathering and reflective reasoning, yet large language models (LLMs) still struggle with it in open-web question answering. Existing methods rely on static prompting rules or training with Wikipedia-based corpora and retrieval environments, limiting adaptability to the real-world web environment where ambiguity, conflicting evidence, and noise are prevalent. These constrained training settings hinder LLMs from learning to dynamically decide when and where to search, and how to adjust search depth and frequency based on informational demands. We define this missing capacity as Search Intensity Scaling (SIS)--the emergent skill to intensify search efforts under ambiguous or conflicting conditions, rather than settling on overconfident, under-verification answers. To study SIS, we introduce WebPuzzle, the first dataset designed to foster information-seeking behavior in open-world internet environments. WebPuzzle consists of 24K training instances and 275 test questions spanning both wiki-based and open-web queries. Building on this dataset, we propose DeepDiver, a Reinforcement Learning (RL) framework that promotes SIS by encouraging adaptive search policies through exploration under a real-world open-web environment. Experimental results show that Pangu-7B-Reasoner empowered by DeepDiver achieve performance on real-web tasks comparable to the 671B-parameter DeepSeek-R1. We detail DeepDiver's training curriculum from cold-start supervised fine-tuning to a carefully designed RL phase, and present that its capability of SIS generalizes from closed-form QA to open-ended tasks such as long-form writing. Our contributions advance adaptive information seeking in LLMs and provide a valuable benchmark and dataset for future research.
MTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025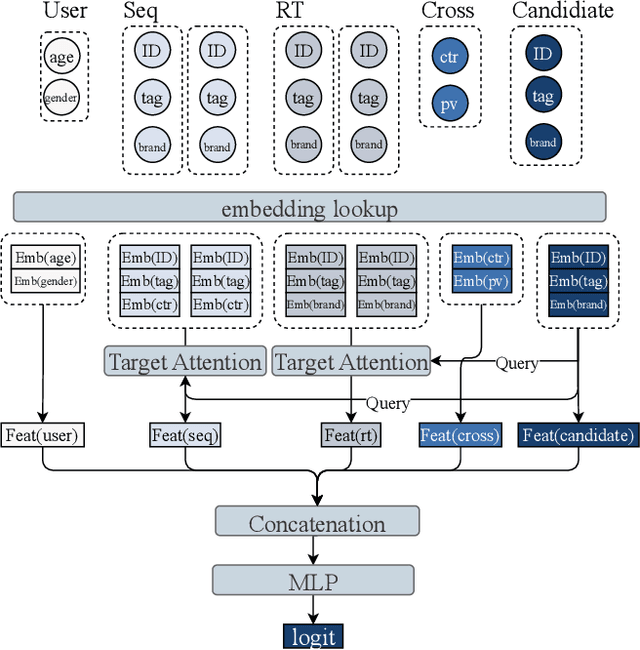
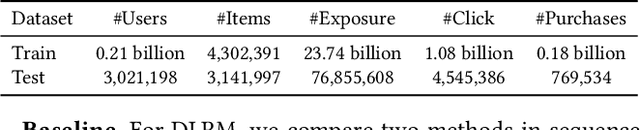
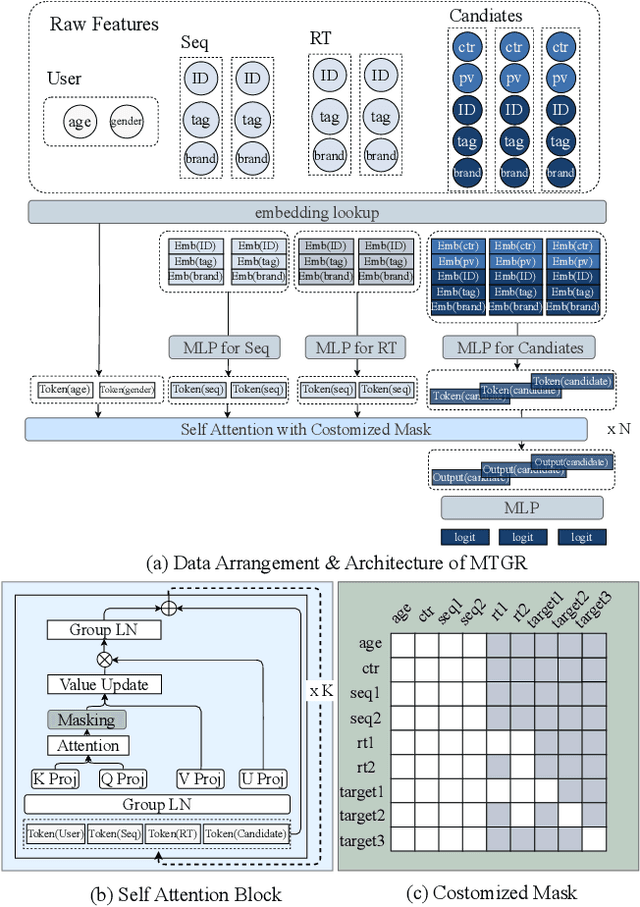

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.
DPSeg: Dual-Prompt Cost Volume Learning for Open-Vocabulary Semantic Segmentation
May 16, 2025Open-vocabulary semantic segmentation aims to segment images into distinct semantic regions for both seen and unseen categories at the pixel level. Current methods utilize text embeddings from pre-trained vision-language models like CLIP but struggle with the inherent domain gap between image and text embeddings, even after extensive alignment during training. Additionally, relying solely on deep text-aligned features limits shallow-level feature guidance, which is crucial for detecting small objects and fine details, ultimately reducing segmentation accuracy. To address these limitations, we propose a dual prompting framework, DPSeg, for this task. Our approach combines dual-prompt cost volume generation, a cost volume-guided decoder, and a semantic-guided prompt refinement strategy that leverages our dual prompting scheme to mitigate alignment issues in visual prompt generation. By incorporating visual embeddings from a visual prompt encoder, our approach reduces the domain gap between text and image embeddings while providing multi-level guidance through shallow features. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches on multiple public datasets.
DocPuzzle: A Process-Aware Benchmark for Evaluating Realistic Long-Context Reasoning Capabilities
Feb 25, 2025We present DocPuzzle, a rigorously constructed benchmark for evaluating long-context reasoning capabilities in large language models (LLMs). This benchmark comprises 100 expert-level QA problems requiring multi-step reasoning over long real-world documents. To ensure the task quality and complexity, we implement a human-AI collaborative annotation-validation pipeline. DocPuzzle introduces an innovative evaluation framework that mitigates guessing bias through checklist-guided process analysis, establishing new standards for assessing reasoning capacities in LLMs. Our evaluation results show that: 1)Advanced slow-thinking reasoning models like o1-preview(69.7%) and DeepSeek-R1(66.3%) significantly outperform best general instruct models like Claude 3.5 Sonnet(57.7%); 2)Distilled reasoning models like DeepSeek-R1-Distill-Qwen-32B(41.3%) falls far behind the teacher model, suggesting challenges to maintain the generalization of reasoning capabilities relying solely on distillation.
More Tokens, Lower Precision: Towards the Optimal Token-Precision Trade-off in KV Cache Compression
Dec 17, 2024As large language models (LLMs) process increasing context windows, the memory usage of KV cache has become a critical bottleneck during inference. The mainstream KV compression methods, including KV pruning and KV quantization, primarily focus on either token or precision dimension and seldom explore the efficiency of their combination. In this paper, we comprehensively investigate the token-precision trade-off in KV cache compression. Experiments demonstrate that storing more tokens in the KV cache with lower precision, i.e., quantized pruning, can significantly enhance the long-context performance of LLMs. Furthermore, in-depth analysis regarding token-precision trade-off from a series of key aspects exhibit that, quantized pruning achieves substantial improvements in retrieval-related tasks and consistently performs well across varying input lengths. Moreover, quantized pruning demonstrates notable stability across different KV pruning methods, quantization strategies, and model scales. These findings provide valuable insights into the token-precision trade-off in KV cache compression. We plan to release our code in the near future.
Quasi-Newton OMP Approach for Super-Resolution Channel Estimation and Extrapolation
Nov 09, 2024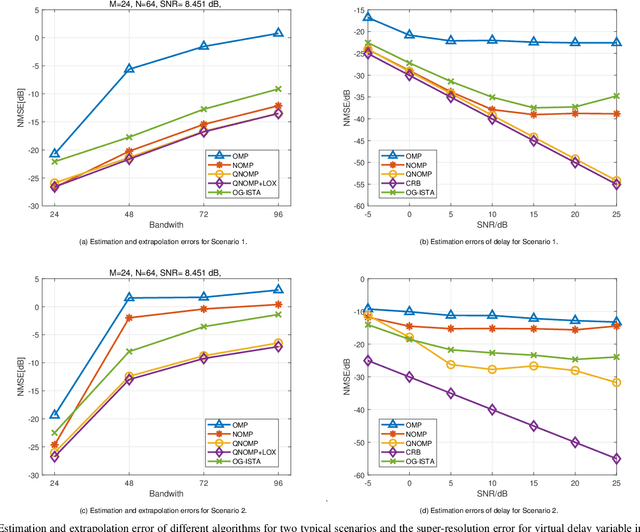
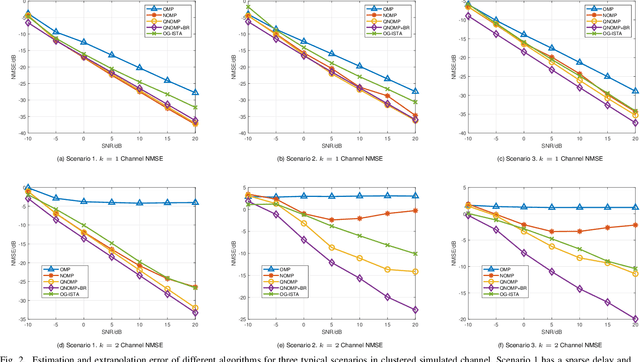
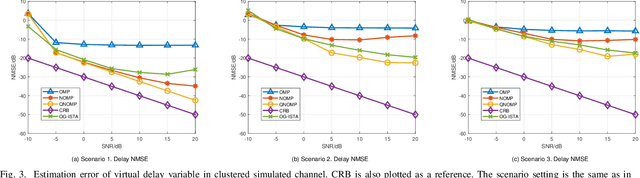
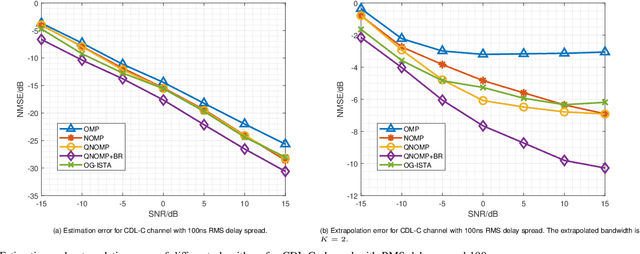
Channel estimation and extrapolation are fundamental issues in MIMO communication systems. In this paper, we proposed the quasi-Newton orthogonal matching pursuit (QNOMP) approach to overcome these issues with high efficiency while maintaining accuracy. The algorithm consists of two stages on the super-resolution recovery: we first performed a cheap on-grid OMP estimation of channel parameters in the sparsity domain (e.g., delay or angle), then an off-grid optimization to achieve the super-resolution. In the off-grid stage, we employed the BFGS quasi-Newton method to jointly estimate the parameters through a multipath model, which improved the speed and accuracy significantly. Furthermore, we derived the optimal extrapolated solution in the linear minimum mean squared estimator criterion, revealed its connection with Slepian basis, and presented a practical algorithm to realize the extrapolation based on the QNOMP results. Special treatment utilizing the block sparsity nature of the considered channels was also proposed. Numerical experiments on the simulated models and CDL-C channels demonstrated the high performance and low computational complexity of QNOMP.