 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTServe: Efficient Serving for Generative Recommendation Models with Hierarchical Caches
Apr 24, 2026Generative recommendation (GR) offers superior modeling capabilities but suffers from prohibitive inference costs due to the repeated encoding of long user histories. While cross-request Key-Value (KV) cache reuse presents a significant optimization opportunity, the massive scale of individual user states creates a storage explosion that far exceeds physical GPU limits. We propose MTServe, a hierarchical cache management system that virtualizes GPU memory by leveraging host RAM as a scalable backup store. To bridge the I/O gap between tiers, MTServe introduces a suite of system-level optimizations, including a hybrid storage layout, an asynchronous data transfer pipeline, and a locality-driven replacement policy. On both public and production datasets, MTServe delivers up to 3.1* speedup while maintaining near-perfect hit ratios (>98.5%).
Short Chains, Deep Thoughts: Balancing Reasoning Efficiency and Intra-Segment Capability via Split-Merge Optimization
Feb 03, 2026While Large Reasoning Models (LRMs) have demonstrated impressive capabilities in solving complex tasks through the generation of long reasoning chains, this reliance on verbose generation results in significant latency and computational overhead. To address these challenges, we propose \textbf{CoSMo} (\textbf{Co}nsistency-Guided \textbf{S}plit-\textbf{M}erge \textbf{O}ptimization), a framework designed to eliminate structural redundancy rather than indiscriminately restricting token volume. Specifically, CoSMo utilizes a split-merge algorithm that dynamically refines reasoning chains by merging redundant segments and splitting logical gaps to ensure coherence. We then employ structure-aligned reinforcement learning with a novel segment-level budget to supervise the model in maintaining efficient reasoning structures throughout training. Extensive experiments across multiple benchmarks and backbones demonstrate that CoSMo achieves superior performance, improving accuracy by \textbf{3.3} points while reducing segment usage by \textbf{28.7\%} on average compared to reasoning efficiency baselines.
MTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025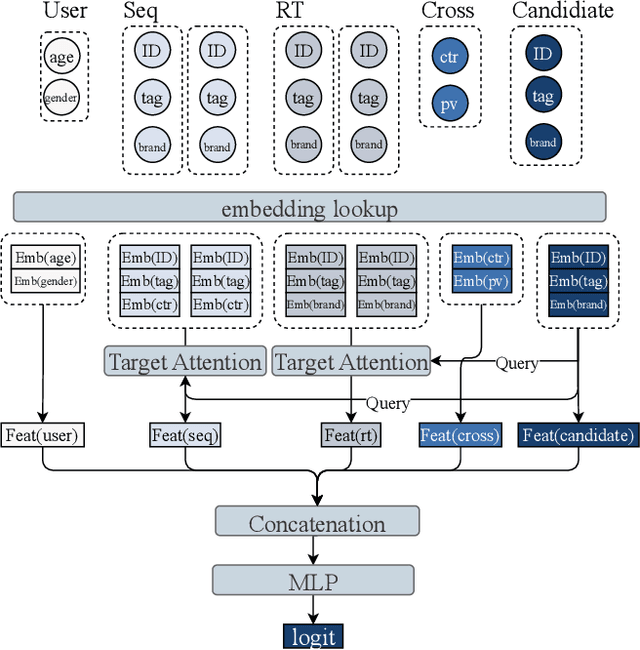
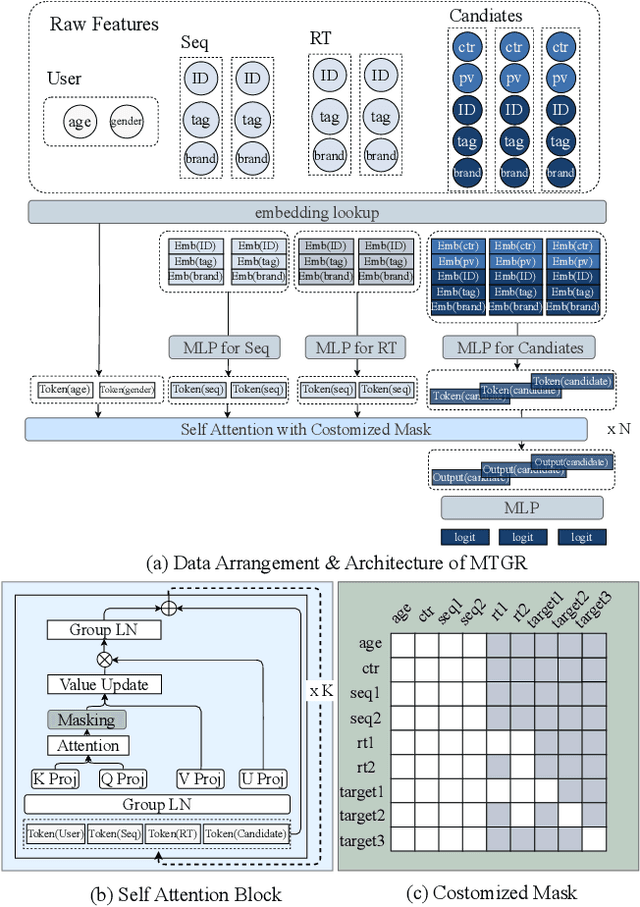

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.
HyperTree Planning: Enhancing LLM Reasoning via Hierarchical Thinking
May 05, 2025Recent advancements have significantly enhanced the performance of large language models (LLMs) in tackling complex reasoning tasks, achieving notable success in domains like mathematical and logical reasoning. However, these methods encounter challenges with complex planning tasks, primarily due to extended reasoning steps, diverse constraints, and the challenge of handling multiple distinct sub-tasks. To address these challenges, we propose HyperTree Planning (HTP), a novel reasoning paradigm that constructs hypertree-structured planning outlines for effective planning. The hypertree structure enables LLMs to engage in hierarchical thinking by flexibly employing the divide-and-conquer strategy, effectively breaking down intricate reasoning steps, accommodating diverse constraints, and managing multiple distinct sub-tasks in a well-organized manner. We further introduce an autonomous planning framework that completes the planning process by iteratively refining and expanding the hypertree-structured planning outlines. Experiments demonstrate the effectiveness of HTP, achieving state-of-the-art accuracy on the TravelPlanner benchmark with Gemini-1.5-Pro, resulting in a 3.6 times performance improvement over o1-preview.
Sparse Brains are Also Adaptive Brains: Cognitive-Load-Aware Dynamic Activation for LLMs
Feb 26, 2025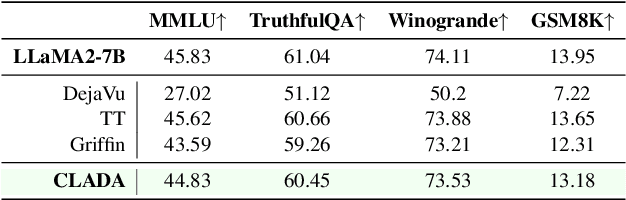
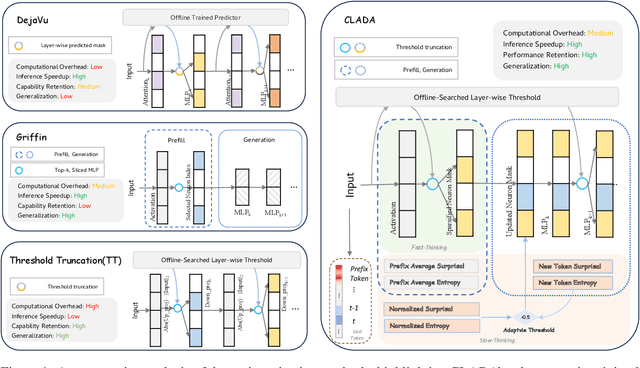
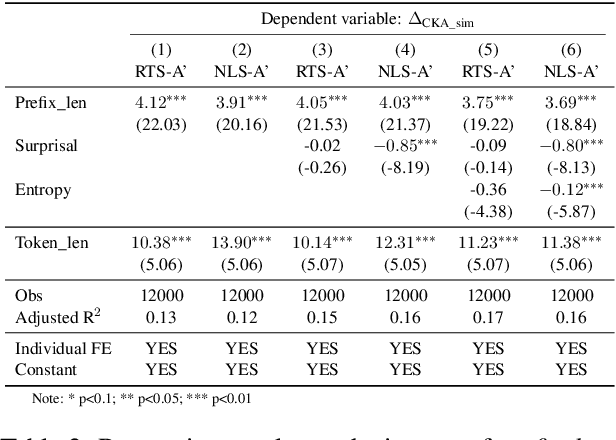
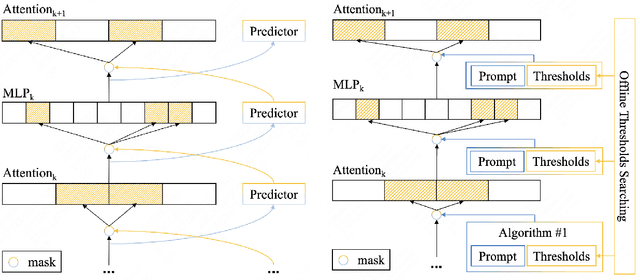
Dense large language models(LLMs) face critical efficiency bottlenecks as they rigidly activate all parameters regardless of input complexity. While existing sparsity methods(static pruning or dynamic activation) address this partially, they either lack adaptivity to contextual or model structural demands or incur prohibitive computational overhead. Inspired by human brain's dual-process mechanisms - predictive coding (N400) for backbone sparsity and structural reanalysis (P600) for complex context - we propose CLADA, a \textit{\textbf{C}ognitive-\textbf{L}oad-\textbf{A}ware \textbf{D}ynamic \textbf{A}ctivation} framework that synergizes statistical sparsity with semantic adaptability. Our key insight is that LLM activations exhibit two complementary patterns: 1) \textit{Global statistical sparsity} driven by sequence-level prefix information, and 2) \textit{Local semantic adaptability} modulated by cognitive load metrics(e.g., surprisal and entropy). CLADA employs a hierarchical thresholding strategy: a baseline from offline error-controlled optimization ensures 40\%+ sparsity, dynamically adjusted by real-time cognitive signals. Evaluations across six mainstream LLMs and nine benchmarks demonstrate that CLADA achieves \textbf{~20\% average speedup with <2\% accuracy drop}, outperforming Griffin (5\%+ degradation) and TT (negligible speedup). Crucially, we establish the first formal connection between neurolinguistic event-related potential (ERP) components and LLM efficiency mechanisms through multi-level regression analysis ($R^2=0.17$ for sparsity-adaptation synergy). Requiring no retraining or architectural changes, CLADA offers a deployable solution for resource-aware LLM inference while advancing biologically-inspired AI design. Our code is available at \href{https://github.com/Oldify/CLADA}{CLADA}.
First Activations Matter: Training-Free Methods for Dynamic Activation in Large Language Models
Aug 21, 2024Dynamic activation (DA) techniques, such as DejaVu and MoEfication, have demonstrated their potential to significantly enhance the inference efficiency of large language models (LLMs). However, these techniques often rely on ReLU activation functions or require additional parameters and training to maintain performance. This paper introduces a training-free Threshold-based Dynamic Activation(TDA) method that leverage sequence information to exploit the inherent sparsity of models across various architectures. This method is designed to accelerate generation speed by 18-25\% without significantly compromising task performance, thereby addressing the limitations of existing DA techniques. Moreover, we delve into the root causes of LLM sparsity and theoretically analyze two of its critical features: history-related activation uncertainty and semantic-irrelevant activation inertia. Our comprehensive analyses not only provide a robust theoretical foundation for DA methods but also offer valuable insights to guide future research in optimizing LLMs for greater efficiency and effectiveness.
MOYU: A Theoretical Study on Massive Over-activation Yielded Uplifts in LLMs
Jun 18, 2024

Massive Over-activation Yielded Uplifts(MOYU) is an inherent property of large language models, and dynamic activation(DA) based on the MOYU property is a clever yet under-explored strategy designed to accelerate inference in these models. Existing methods that utilize MOYU often face a significant 'Impossible Trinity': struggling to simultaneously maintain model performance, enhance inference speed, and extend applicability across various architectures. Due to the theoretical ambiguities surrounding MOYU, this paper elucidates the root cause of the MOYU property and outlines the mechanisms behind two primary limitations encountered by current DA methods: 1) history-related activation uncertainty, and 2) semantic-irrelevant activation inertia. Our analysis not only underscores the limitations of current dynamic activation strategies within large-scale LLaMA models but also proposes opportunities for refining the design of future sparsity schemes.
Dynamic Activation Pitfalls in LLaMA Models: An Empirical Study
May 15, 2024In this work, we systematically investigate the efficacy of dynamic activation mechanisms within the LLaMA family of language models. Despite the potential of dynamic activation methods to reduce computation and increase speed in models using the ReLU activation function, our empirical findings have uncovered several inherent pitfalls in the current dynamic activation schemes. Through extensive experiments across various dynamic activation strategies, we demonstrate that LLaMA models usually underperform when compared to their ReLU counterparts, particularly in scenarios demanding high sparsity ratio. We attribute these deficiencies to a combination of factors: 1) the inherent complexity of dynamically predicting activation heads and neurons; 2) the inadequate sparsity resulting from activation functions; 3) the insufficient preservation of information resulting from KV cache skipping. Our analysis not only sheds light on the limitations of dynamic activation in the context of large-scale LLaMA models but also proposes roadmaps for enhancing the design of future sparsity schemes.
Re-evaluating the Memory-balanced Pipeline Parallelism: BPipe
Jan 04, 2024



Pipeline parallelism is an essential technique in the training of large-scale Transformer models. However, it suffers from imbalanced memory consumption, leading to insufficient memory utilization. The BPipe technique was proposed to address this issue and has proven effective in the GPT-3 model. Nevertheless, our experiments have not yielded similar benefits for LLaMA training. Additionally, BPipe only yields negligible benefits for GPT-3 training when applying flash attention. We analyze the underlying causes of the divergent performance of BPipe on GPT-3 and LLaMA. Furthermore, we introduce a novel method to estimate the performance of BPipe.
Morphological Operation Residual Blocks: Enhancing 3D Morphological Feature Representation in Convolutional Neural Networks for Semantic Segmentation of Medical Images
Mar 06, 2021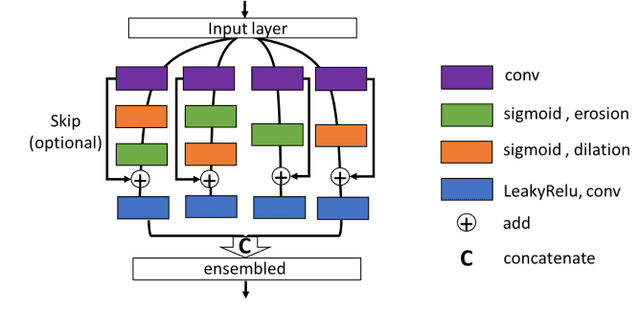

The shapes and morphology of the organs and tissues are important prior knowledge in medical imaging recognition and segmentation. The morphological operation is a well-known method for morphological feature extraction. As the morphological operation is performed well in hand-crafted image segmentation techniques, it is also promising to design an approach to approximate morphological operation in the convolutional networks. However, using the traditional convolutional neural network as a black-box is usually hard to specify the morphological operation action. Here, we introduced a 3D morphological operation residual block to extract morphological features in end-to-end deep learning models for semantic segmentation. This study proposed a novel network block architecture that embedded the morphological operation as an infinitely strong prior in the convolutional neural network. Several 3D deep learning models with the proposed morphological operation block were built and compared in different medical imaging segmentation tasks. Experimental results showed the proposed network achieved a relatively higher performance in the segmentation tasks comparing with the conventional approach. In conclusion, the novel network block could be easily embedded in traditional networks and efficiently reinforce the deep learning models for medical imaging segmentation.