 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the accuracy and generalizability of molecular property regression models with a substructure-substitution-rule-informed framework
Nov 11, 2025Artificial Intelligence (AI)-aided drug discovery is an active research field, yet AI models often exhibit poor accuracy in regression tasks for molecular property prediction, and perform catastrophically poorly for out-of-distribution (OOD) molecules. Here, we present MolRuleLoss, a substructure-substitution-rule-informed framework that improves the accuracy and generalizability of multiple molecular property regression models (MPRMs) such as GEM and UniMol for diverse molecular property prediction tasks. MolRuleLoss incorporates partial derivative constraints for substructure substitution rules (SSRs) into an MPRM's loss function. When using GEM models for predicting lipophilicity, water solubility, and solvation-free energy (using lipophilicity, ESOL, and freeSolv datasets from MoleculeNet), the root mean squared error (RMSE) values with and without MolRuleLoss were 0.587 vs. 0.660, 0.777 vs. 0.798, and 1.252 vs. 1.877, respectively, representing 2.6-33.3% performance improvements. We show that both the number and the quality of SSRs contribute to the magnitude of prediction accuracy gains obtained upon adding MolRuleLoss to an MPRM. MolRuleLoss improved the generalizability of MPRMs for "activity cliff" molecules in a lipophilicity prediction task and improved the generalizability of MPRMs for OOD molecules in a melting point prediction task. In a molecular weight prediction task for OOD molecules, MolRuleLoss reduced the RMSE value of a GEM model from 29.507 to 0.007. We also provide a formal demonstration that the upper bound of the variation for property change of SSRs is positively correlated with an MPRM's error. Together, we show that using the MolRuleLoss framework as a bolt-on boosts the prediction accuracy and generalizability of multiple MPRMs, supporting diverse applications in areas like cheminformatics and AI-aided drug discovery.
Revisiting Generative Infrared and Visible Image Fusion Based on Human Cognitive Laws
Oct 30, 2025Existing infrared and visible image fusion methods often face the dilemma of balancing modal information. Generative fusion methods reconstruct fused images by learning from data distributions, but their generative capabilities remain limited. Moreover, the lack of interpretability in modal information selection further affects the reliability and consistency of fusion results in complex scenarios. This manuscript revisits the essence of generative image fusion under the inspiration of human cognitive laws and proposes a novel infrared and visible image fusion method, termed HCLFuse. First, HCLFuse investigates the quantification theory of information mapping in unsupervised fusion networks, which leads to the design of a multi-scale mask-regulated variational bottleneck encoder. This encoder applies posterior probability modeling and information decomposition to extract accurate and concise low-level modal information, thereby supporting the generation of high-fidelity structural details. Furthermore, the probabilistic generative capability of the diffusion model is integrated with physical laws, forming a time-varying physical guidance mechanism that adaptively regulates the generation process at different stages, thereby enhancing the ability of the model to perceive the intrinsic structure of data and reducing dependence on data quality. Experimental results show that the proposed method achieves state-of-the-art fusion performance in qualitative and quantitative evaluations across multiple datasets and significantly improves semantic segmentation metrics. This fully demonstrates the advantages of this generative image fusion method, drawing inspiration from human cognition, in enhancing structural consistency and detail quality.
Rethinking the Mean Teacher Strategy from the Perspective of Self-paced Learning
May 16, 2025



Semi-supervised medical image segmentation has attracted significant attention due to its potential to reduce manual annotation costs. The mean teacher (MT) strategy, commonly understood as introducing smoothed, temporally lagged consistency regularization, has demonstrated strong performance across various tasks in this field. In this work, we reinterpret the MT strategy on supervised data as a form of self-paced learning, regulated by the output agreement between the temporally lagged teacher model and the ground truth labels. This idea is further extended to incorporate agreement between a temporally lagged model and a cross-architectural model, which offers greater flexibility in regulating the learning pace and enables application to unlabeled data. Specifically, we propose dual teacher-student learning (DTSL), a framework that introduces two groups of teacher-student models with different architectures. The output agreement between the cross-group teacher and student models is used as pseudo-labels, generated via a Jensen-Shannon divergence-based consensus label generator (CLG). Extensive experiments on popular datasets demonstrate that the proposed method consistently outperforms existing state-of-the-art approaches. Ablation studies further validate the effectiveness of the proposed modules.
An artificially intelligent magnetic resonance spectroscopy quantification method: Comparison between QNet and LCModel on the cloud computing platform CloudBrain-MRS
Mar 06, 2025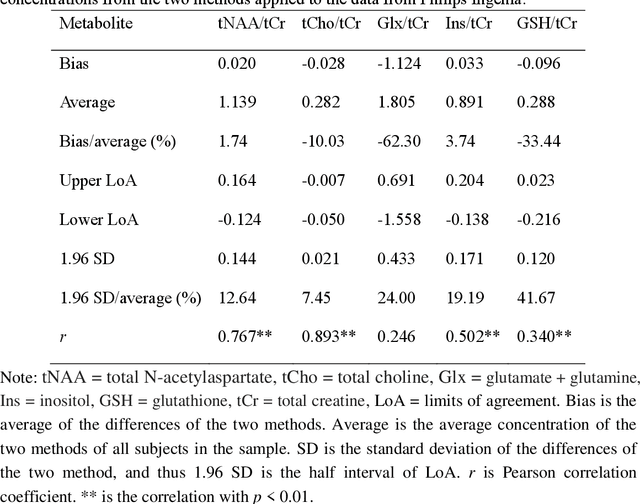

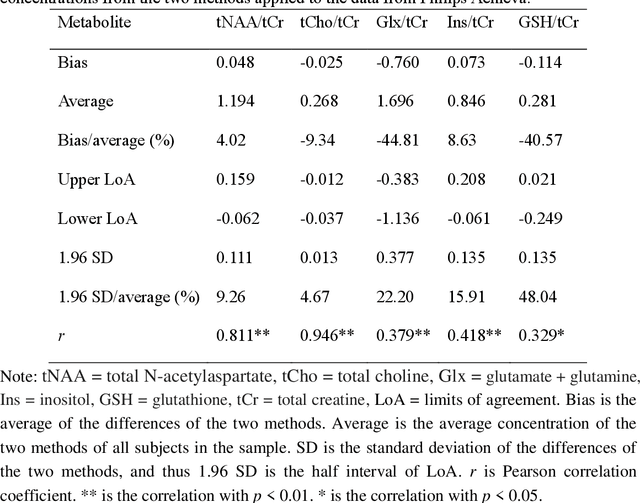
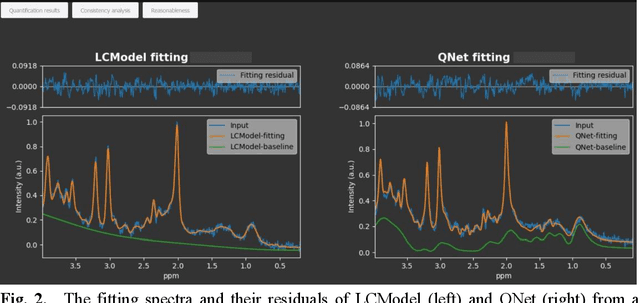
Objctives: This work aimed to statistically compare the metabolite quantification of human brain magnetic resonance spectroscopy (MRS) between the deep learning method QNet and the classical method LCModel through an easy-to-use intelligent cloud computing platform CloudBrain-MRS. Materials and Methods: In this retrospective study, two 3 T MRI scanners Philips Ingenia and Achieva collected 61 and 46 in vivo 1H magnetic resonance (MR) spectra of healthy participants, respectively, from the brain region of pregenual anterior cingulate cortex from September to October 2021. The analyses of Bland-Altman, Pearson correlation and reasonability were performed to assess the degree of agreement, linear correlation and reasonability between the two quantification methods. Results: Fifteen healthy volunteers (12 females and 3 males, age range: 21-35 years, mean age/standard deviation = 27.4/3.9 years) were recruited. The analyses of Bland-Altman, Pearson correlation and reasonability showed high to good consistency and very strong to moderate correlation between the two methods for quantification of total N-acetylaspartate (tNAA), total choline (tCho), and inositol (Ins) (relative half interval of limits of agreement = 3.04%, 9.3%, and 18.5%, respectively; Pearson correlation coefficient r = 0.775, 0.927, and 0.469, respectively). In addition, quantification results of QNet are more likely to be closer to the previous reported average values than those of LCModel. Conclusion: There were high or good degrees of consistency between the quantification results of QNet and LCModel for tNAA, tCho, and Ins, and QNet generally has more reasonable quantification than LCModel.
Mitigating Data Consistency Induced Discrepancy in Cascaded Diffusion Models for Sparse-view CT Reconstruction
Mar 14, 2024
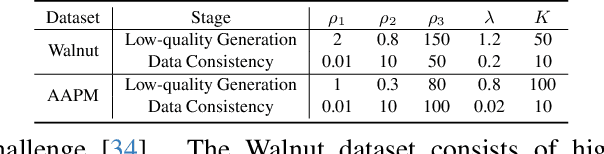
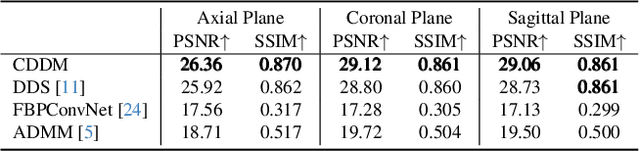
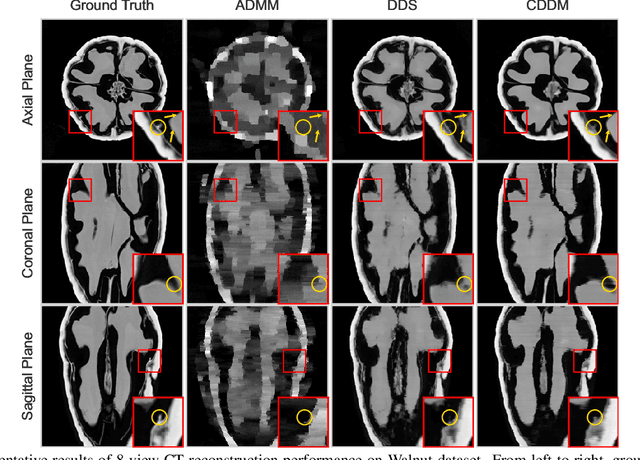
Sparse-view Computed Tomography (CT) image reconstruction is a promising approach to reduce radiation exposure, but it inevitably leads to image degradation. Although diffusion model-based approaches are computationally expensive and suffer from the training-sampling discrepancy, they provide a potential solution to the problem. This study introduces a novel Cascaded Diffusion with Discrepancy Mitigation (CDDM) framework, including the low-quality image generation in latent space and the high-quality image generation in pixel space which contains data consistency and discrepancy mitigation in a one-step reconstruction process. The cascaded framework minimizes computational costs by moving some inference steps from pixel space to latent space. The discrepancy mitigation technique addresses the training-sampling gap induced by data consistency, ensuring the data distribution is close to the original manifold. A specialized Alternating Direction Method of Multipliers (ADMM) is employed to process image gradients in separate directions, offering a more targeted approach to regularization. Experimental results across two datasets demonstrate CDDM's superior performance in high-quality image generation with clearer boundaries compared to existing methods, highlighting the framework's computational efficiency.
Moving Object Localization based on the Fusion of Ultra-WideBand and LiDAR with a Mobile Robot
Oct 16, 2023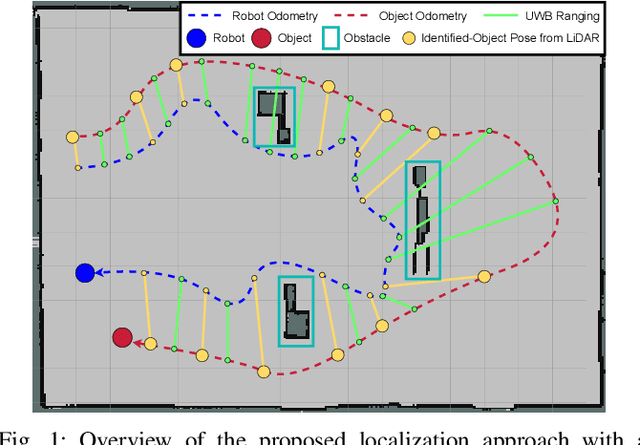
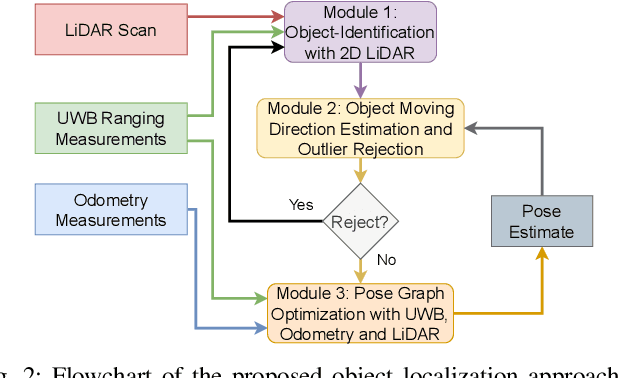

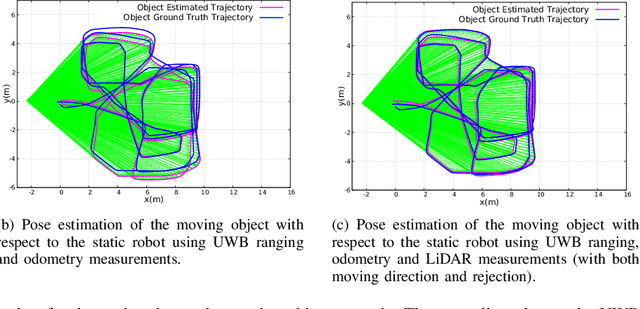
Localization of objects is vital for robot-object interaction. Light Detection and Ranging (LiDAR) application in robotics is an emerging and widely used object localization technique due to its accurate distance measurement, long-range, wide field of view, and robustness in different conditions. However, LiDAR is unable to identify the objects when they are obstructed by obstacles, resulting in inaccuracy and noise in localization. To address this issue, we present an approach incorporating LiDAR and Ultra-Wideband (UWB) ranging for object localization. The UWB is popular in sensor fusion localization algorithms due to its low weight and low power consumption. In addition, the UWB is able to return ranging measurements even when the object is not within line-of-sight. Our approach provides an efficient solution to combine an anonymous optical sensor (LiDAR) with an identity-based radio sensor (UWB) to improve the localization accuracy of the object. Our approach consists of three modules. The first module is an object-identification algorithm that compares successive scans from the LiDAR to detect a moving object in the environment and returns the position with the closest range to UWB ranging. The second module estimates the moving object's moving direction using the previous and current estimated position from our object-identification module. It removes the suspicious estimations through an outlier rejection criterion. Lastly, we fuse the LiDAR, UWB ranging, and odometry measurements in pose graph optimization (PGO) to recover the entire trajectory of the robot and object. Extensive experiments were performed to evaluate the performance of the proposed approach.
Accelerating Large Batch Training via Gradient Signal to Noise Ratio (GSNR)
Sep 24, 2023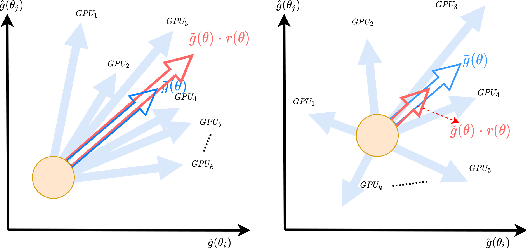
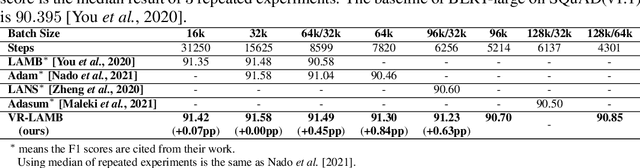
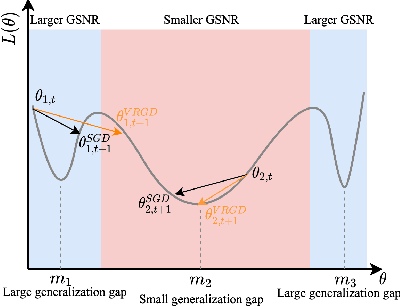

As models for nature language processing (NLP), computer vision (CV) and recommendation systems (RS) require surging computation, a large number of GPUs/TPUs are paralleled as a large batch (LB) to improve training throughput. However, training such LB tasks often meets large generalization gap and downgrades final precision, which limits enlarging the batch size. In this work, we develop the variance reduced gradient descent technique (VRGD) based on the gradient signal to noise ratio (GSNR) and apply it onto popular optimizers such as SGD/Adam/LARS/LAMB. We carry out a theoretical analysis of convergence rate to explain its fast training dynamics, and a generalization analysis to demonstrate its smaller generalization gap on LB training. Comprehensive experiments demonstrate that VRGD can accelerate training ($1\sim 2 \times$), narrow generalization gap and improve final accuracy. We push the batch size limit of BERT pretraining up to 128k/64k and DLRM to 512k without noticeable accuracy loss. We improve ImageNet Top-1 accuracy at 96k by $0.52pp$ than LARS. The generalization gap of BERT and ImageNet training is significantly reduce by over $65\%$.
SKDBERT: Compressing BERT via Stochastic Knowledge Distillation
Nov 29, 2022In this paper, we propose Stochastic Knowledge Distillation (SKD) to obtain compact BERT-style language model dubbed SKDBERT. In each iteration, SKD samples a teacher model from a pre-defined teacher ensemble, which consists of multiple teacher models with multi-level capacities, to transfer knowledge into student model in an one-to-one manner. Sampling distribution plays an important role in SKD. We heuristically present three types of sampling distributions to assign appropriate probabilities for multi-level teacher models. SKD has two advantages: 1) it can preserve the diversities of multi-level teacher models via stochastically sampling single teacher model in each iteration, and 2) it can also improve the efficacy of knowledge distillation via multi-level teacher models when large capacity gap exists between the teacher model and the student model. Experimental results on GLUE benchmark show that SKDBERT reduces the size of a BERT$_{\rm BASE}$ model by 40% while retaining 99.5% performances of language understanding and being 100% faster.
AMAD: Adversarial Multiscale Anomaly Detection on High-Dimensional and Time-Evolving Categorical Data
Jul 12, 2019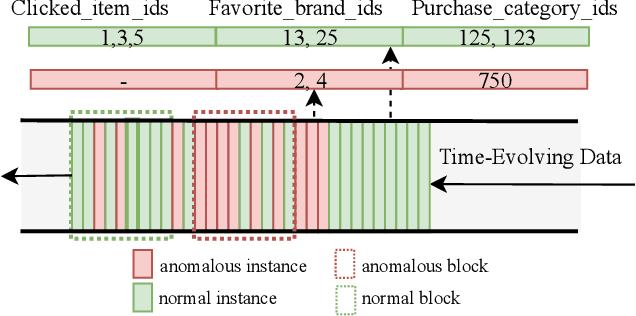

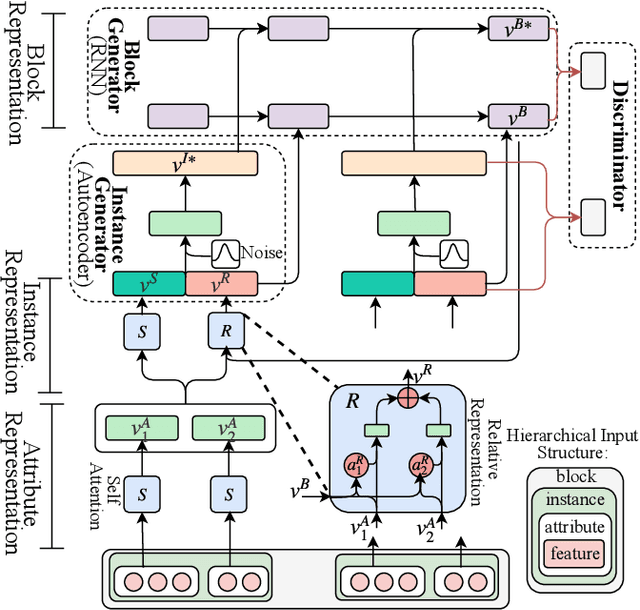

Anomaly detection is facing with emerging challenges in many important industry domains, such as cyber security and online recommendation and advertising. The recent trend in these areas calls for anomaly detection on time-evolving data with high-dimensional categorical features without labeled samples. Also, there is an increasing demand for identifying and monitoring irregular patterns at multiple resolutions. In this work, we propose a unified end-to-end approach to solve these challenges by combining the advantages of Adversarial Autoencoder and Recurrent Neural Network. The model learns data representations cross different scales with attention mechanisms, on which an enhanced two-resolution anomaly detector is developed for both instances and data blocks. Extensive experiments are performed over three types of datasets to demonstrate the efficacy of our method and its superiority over the state-of-art approaches.
Visualizing and Understanding Deep Neural Networks in CTR Prediction
Jun 22, 2018



Although deep learning techniques have been successfully applied to many tasks, interpreting deep neural network models is still a big challenge to us. Recently, many works have been done on visualizing and analyzing the mechanism of deep neural networks in the areas of image processing and natural language processing. In this paper, we present our approaches to visualize and understand deep neural networks for a very important commercial task--CTR (Click-through rate) prediction. We conduct experiments on the productive data from our online advertising system with daily varying distribution. To understand the mechanism and the performance of the model, we inspect the model's inner status at neuron level. Also, a probe approach is implemented to measure the layer-wise performance of the model. Moreover, to measure the influence from the input features, we calculate saliency scores based on the back-propagated gradients. Practical applications are also discussed, for example, in understanding, monitoring, diagnosing and refining models and algorithms.