 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance Robustness of Language Models Against Variation Attack through Graph Integration
Apr 18, 2024



The widespread use of pre-trained language models (PLMs) in natural language processing (NLP) has greatly improved performance outcomes. However, these models' vulnerability to adversarial attacks (e.g., camouflaged hints from drug dealers), particularly in the Chinese language with its rich character diversity/variation and complex structures, hatches vital apprehension. In this study, we propose a novel method, CHinese vAriatioN Graph Enhancement (CHANGE), to increase the robustness of PLMs against character variation attacks in Chinese content. CHANGE presents a novel approach for incorporating a Chinese character variation graph into the PLMs. Through designing different supplementary tasks utilizing the graph structure, CHANGE essentially enhances PLMs' interpretation of adversarially manipulated text. Experiments conducted in a multitude of NLP tasks show that CHANGE outperforms current language models in combating against adversarial attacks and serves as a valuable contribution to robust language model research. These findings contribute to the groundwork on robust language models and highlight the substantial potential of graph-guided pre-training strategies for real-world applications.
Cross-Domain Contract Element Extraction with a Bi-directional Feedback Clause-Element Relation Network
May 13, 2021
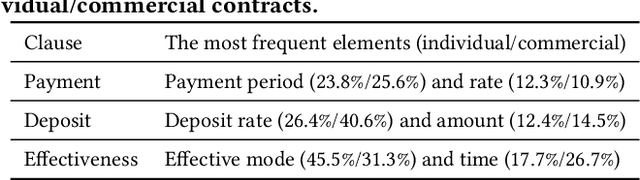
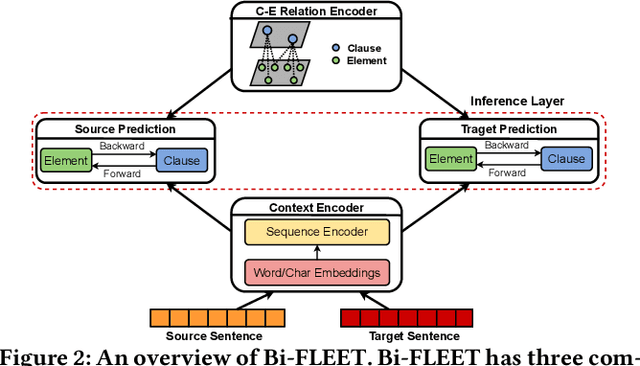
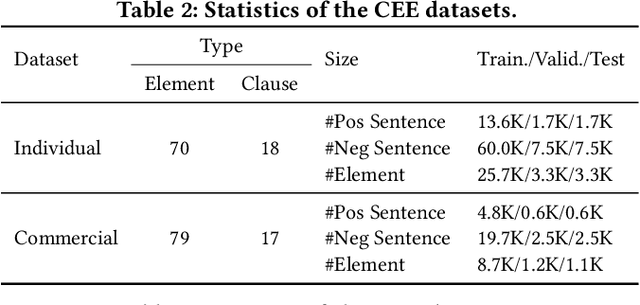
Contract element extraction (CEE) is the novel task of automatically identifying and extracting legally relevant elements such as contract dates, payments, and legislation references from contracts. Automatic methods for this task view it as a sequence labeling problem and dramatically reduce human labor. However, as contract genres and element types may vary widely, a significant challenge for this sequence labeling task is how to transfer knowledge from one domain to another, i.e., cross-domain CEE. Cross-domain CEE differs from cross-domain named entity recognition (NER) in two important ways. First, contract elements are far more fine-grained than named entities, which hinders the transfer of extractors. Second, the extraction zones for cross-domain CEE are much larger than for cross-domain NER. As a result, the contexts of elements from different domains can be more diverse. We propose a framework, the Bi-directional Feedback cLause-Element relaTion network (Bi-FLEET), for the cross-domain CEE task that addresses the above challenges. Bi-FLEET has three main components: (1) a context encoder, (2) a clause-element relation encoder, and (3) an inference layer. To incorporate invariant knowledge about element and clause types, a clause-element graph is constructed across domains and a hierarchical graph neural network is adopted in the clause-element relation encoder. To reduce the influence of context variations, a multi-task framework with a bi-directional feedback scheme is designed in the inference layer, conducting both clause classification and element extraction. The experimental results over both cross-domain NER and CEE tasks show that Bi-FLEET significantly outperforms state-of-the-art baselines.
Cross-Lingual Low-Resource Set-to-Description Retrieval for Global E-Commerce
May 17, 2020
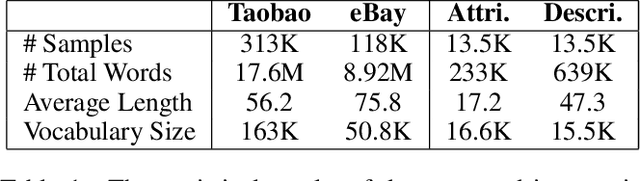
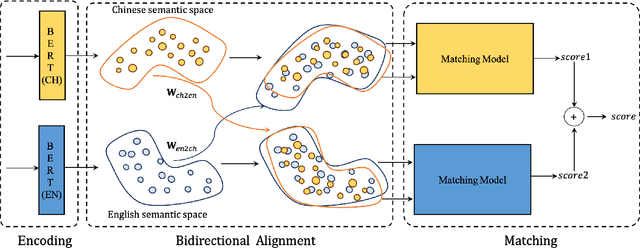

With the prosperous of cross-border e-commerce, there is an urgent demand for designing intelligent approaches for assisting e-commerce sellers to offer local products for consumers from all over the world. In this paper, we explore a new task of cross-lingual information retrieval, i.e., cross-lingual set-to-description retrieval in cross-border e-commerce, which involves matching product attribute sets in the source language with persuasive product descriptions in the target language. We manually collect a new and high-quality paired dataset, where each pair contains an unordered product attribute set in the source language and an informative product description in the target language. As the dataset construction process is both time-consuming and costly, the new dataset only comprises of 13.5k pairs, which is a low-resource setting and can be viewed as a challenging testbed for model development and evaluation in cross-border e-commerce. To tackle this cross-lingual set-to-description retrieval task, we propose a novel cross-lingual matching network (CLMN) with the enhancement of context-dependent cross-lingual mapping upon the pre-trained monolingual BERT representations. Experimental results indicate that our proposed CLMN yields impressive results on the challenging task and the context-dependent cross-lingual mapping on BERT yields noticeable improvement over the pre-trained multi-lingual BERT model.
AMAD: Adversarial Multiscale Anomaly Detection on High-Dimensional and Time-Evolving Categorical Data
Jul 12, 2019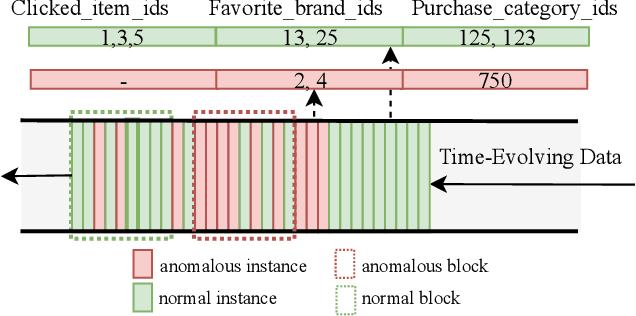

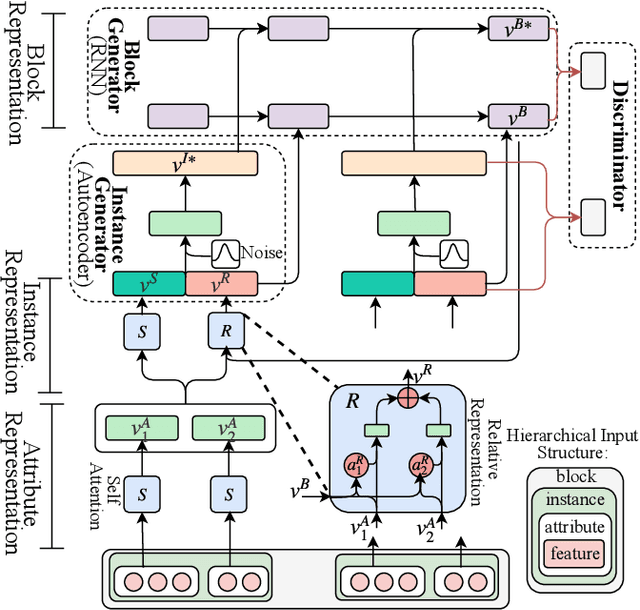

Anomaly detection is facing with emerging challenges in many important industry domains, such as cyber security and online recommendation and advertising. The recent trend in these areas calls for anomaly detection on time-evolving data with high-dimensional categorical features without labeled samples. Also, there is an increasing demand for identifying and monitoring irregular patterns at multiple resolutions. In this work, we propose a unified end-to-end approach to solve these challenges by combining the advantages of Adversarial Autoencoder and Recurrent Neural Network. The model learns data representations cross different scales with attention mechanisms, on which an enhanced two-resolution anomaly detector is developed for both instances and data blocks. Extensive experiments are performed over three types of datasets to demonstrate the efficacy of our method and its superiority over the state-of-art approaches.