 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlRetriever: Harnessing the Power of Instructions for Controllable Retrieval
Aug 19, 2023



Recent studies have shown that dense retrieval models, lacking dedicated training data, struggle to perform well across diverse retrieval tasks, as different retrieval tasks often entail distinct search intents. To address this challenge, in this work we introduce ControlRetriever, a generic and efficient approach with a parameter isolated architecture, capable of controlling dense retrieval models to directly perform varied retrieval tasks, harnessing the power of instructions that explicitly describe retrieval intents in natural language. Leveraging the foundation of ControlNet, which has proven powerful in text-to-image generation, ControlRetriever imbues different retrieval models with the new capacity of controllable retrieval, all while being guided by task-specific instructions. Furthermore, we propose a novel LLM guided Instruction Synthesizing and Iterative Training strategy, which iteratively tunes ControlRetriever based on extensive automatically-generated retrieval data with diverse instructions by capitalizing the advancement of large language models. Extensive experiments show that in the BEIR benchmark, with only natural language descriptions of specific retrieval intent for each task, ControlRetriever, as a unified multi-task retrieval system without task-specific tuning, significantly outperforms baseline methods designed with task-specific retrievers and also achieves state-of-the-art zero-shot performance.
Meta-augmented Prompt Tuning for Better Few-shot Learning
Mar 28, 2023



Prompt tuning is a parameter-efficient method, which freezes all PLM parameters and only prepends some additional tunable tokens called soft prompts to the input text. However, soft prompts heavily rely on a better initialization and may easily result in overfitting under few-shot settings, which causes prompt-tuning performing much worse than fine-tuning. To address the above issues, this paper proposes a novel Self-sUpervised Meta-prompt learning framework with MEtagradient Regularization for few shot generalization (SUMMER). We leverage self-supervised meta-learning to better initialize soft prompts and curriculum-based task augmentation is further proposed to enrich the meta-task distribution. Besides, a novel meta-gradient regularization method is integrated into the meta-prompt learning framework, which meta-learns to transform the raw gradient during few-shot learning into a domain-generalizable direction, thus alleviating the problem of overfitting. Extensive experiments show that SUMMER achieves better performance for different few-shot downstream tasks, and also exhibits a stronger domain generalization ability.
Cross-Domain Contract Element Extraction with a Bi-directional Feedback Clause-Element Relation Network
May 13, 2021
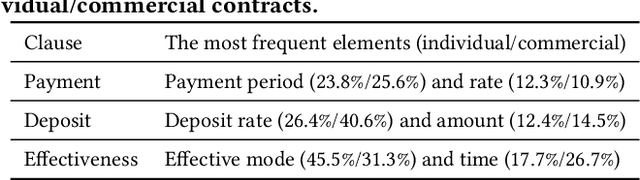
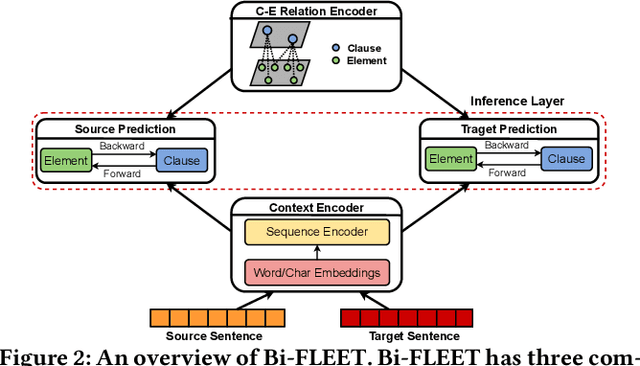
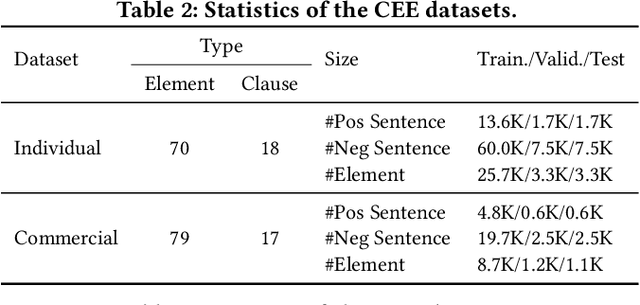
Contract element extraction (CEE) is the novel task of automatically identifying and extracting legally relevant elements such as contract dates, payments, and legislation references from contracts. Automatic methods for this task view it as a sequence labeling problem and dramatically reduce human labor. However, as contract genres and element types may vary widely, a significant challenge for this sequence labeling task is how to transfer knowledge from one domain to another, i.e., cross-domain CEE. Cross-domain CEE differs from cross-domain named entity recognition (NER) in two important ways. First, contract elements are far more fine-grained than named entities, which hinders the transfer of extractors. Second, the extraction zones for cross-domain CEE are much larger than for cross-domain NER. As a result, the contexts of elements from different domains can be more diverse. We propose a framework, the Bi-directional Feedback cLause-Element relaTion network (Bi-FLEET), for the cross-domain CEE task that addresses the above challenges. Bi-FLEET has three main components: (1) a context encoder, (2) a clause-element relation encoder, and (3) an inference layer. To incorporate invariant knowledge about element and clause types, a clause-element graph is constructed across domains and a hierarchical graph neural network is adopted in the clause-element relation encoder. To reduce the influence of context variations, a multi-task framework with a bi-directional feedback scheme is designed in the inference layer, conducting both clause classification and element extraction. The experimental results over both cross-domain NER and CEE tasks show that Bi-FLEET significantly outperforms state-of-the-art baselines.