 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Batch Training via Gradient Signal to Noise Ratio (GSNR)
Sep 24, 2023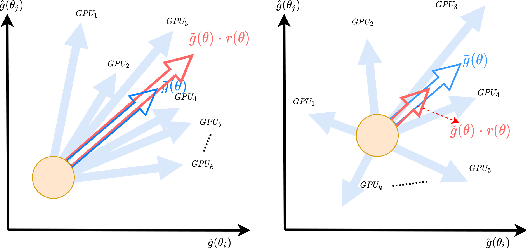
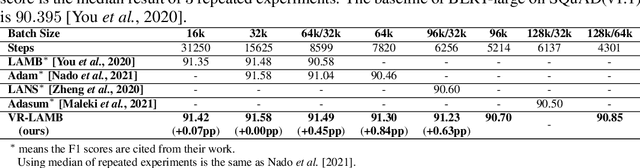
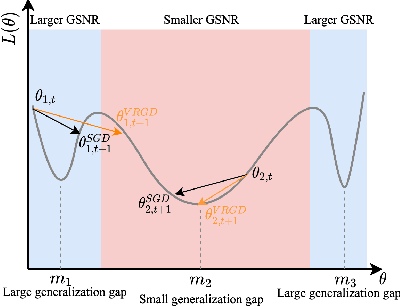

As models for nature language processing (NLP), computer vision (CV) and recommendation systems (RS) require surging computation, a large number of GPUs/TPUs are paralleled as a large batch (LB) to improve training throughput. However, training such LB tasks often meets large generalization gap and downgrades final precision, which limits enlarging the batch size. In this work, we develop the variance reduced gradient descent technique (VRGD) based on the gradient signal to noise ratio (GSNR) and apply it onto popular optimizers such as SGD/Adam/LARS/LAMB. We carry out a theoretical analysis of convergence rate to explain its fast training dynamics, and a generalization analysis to demonstrate its smaller generalization gap on LB training. Comprehensive experiments demonstrate that VRGD can accelerate training ($1\sim 2 \times$), narrow generalization gap and improve final accuracy. We push the batch size limit of BERT pretraining up to 128k/64k and DLRM to 512k without noticeable accuracy loss. We improve ImageNet Top-1 accuracy at 96k by $0.52pp$ than LARS. The generalization gap of BERT and ImageNet training is significantly reduce by over $65\%$.