 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse-Aware Dual-Track Streaming Response for Low-Latency Spoken Dialogue Systems
Feb 26, 2026Achieving human-like responsiveness is a critical yet challenging goal for cascaded spoken dialogue systems. Conventional ASR-LLM-TTS pipelines follow a strictly sequential paradigm, requiring complete transcription and full reasoning before speech synthesis can begin, which results in high response latency. We propose the Discourse-Aware Dual-Track Streaming Response (DDTSR) framework, a low-latency architecture that enables listen-while-thinking and speak-while-thinking. DDTSR is built upon three key mechanisms: (1) connective-guided small-large model synergy, where an auxiliary small model generates minimal-committal discourse connectives while a large model performs knowledge-intensive reasoning in parallel; (2) streaming-based cross-modal collaboration, which dynamically overlaps ASR, LLM inference, and TTS to advance the earliest speakable moment; and (3) curriculum-learning-based discourse continuity enhancement, which maintains coherence and logical consistency between early responses and subsequent reasoning outputs. Experiments on two spoken dialogue benchmarks demonstrate that DDTSR reduces response latency by 19%-51% while preserving discourse quality. Further analysis shows that DDTSR functions as a plug-and-play module compatible with diverse LLM backbones, and remains robust across varying utterance lengths, indicating strong practicality and scalability for real-time spoken interaction.
Sparse Brains are Also Adaptive Brains: Cognitive-Load-Aware Dynamic Activation for LLMs
Feb 26, 2025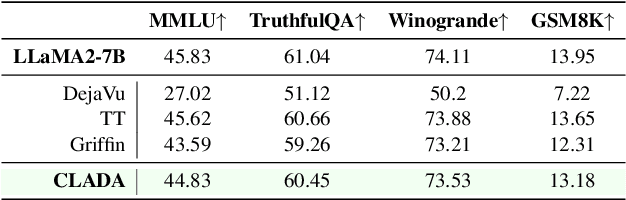
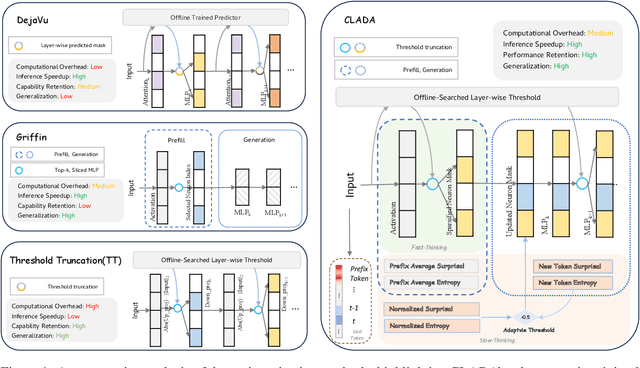
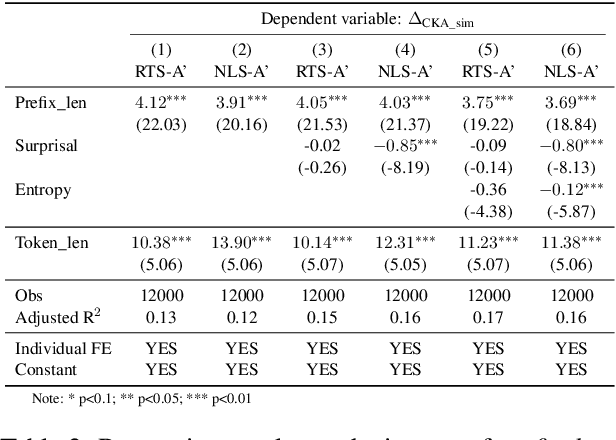
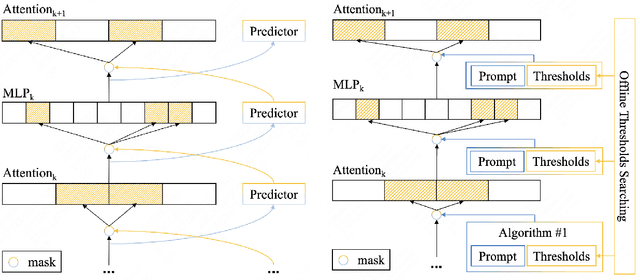
Dense large language models(LLMs) face critical efficiency bottlenecks as they rigidly activate all parameters regardless of input complexity. While existing sparsity methods(static pruning or dynamic activation) address this partially, they either lack adaptivity to contextual or model structural demands or incur prohibitive computational overhead. Inspired by human brain's dual-process mechanisms - predictive coding (N400) for backbone sparsity and structural reanalysis (P600) for complex context - we propose CLADA, a \textit{\textbf{C}ognitive-\textbf{L}oad-\textbf{A}ware \textbf{D}ynamic \textbf{A}ctivation} framework that synergizes statistical sparsity with semantic adaptability. Our key insight is that LLM activations exhibit two complementary patterns: 1) \textit{Global statistical sparsity} driven by sequence-level prefix information, and 2) \textit{Local semantic adaptability} modulated by cognitive load metrics(e.g., surprisal and entropy). CLADA employs a hierarchical thresholding strategy: a baseline from offline error-controlled optimization ensures 40\%+ sparsity, dynamically adjusted by real-time cognitive signals. Evaluations across six mainstream LLMs and nine benchmarks demonstrate that CLADA achieves \textbf{~20\% average speedup with <2\% accuracy drop}, outperforming Griffin (5\%+ degradation) and TT (negligible speedup). Crucially, we establish the first formal connection between neurolinguistic event-related potential (ERP) components and LLM efficiency mechanisms through multi-level regression analysis ($R^2=0.17$ for sparsity-adaptation synergy). Requiring no retraining or architectural changes, CLADA offers a deployable solution for resource-aware LLM inference while advancing biologically-inspired AI design. Our code is available at \href{https://github.com/Oldify/CLADA}{CLADA}.
Cross-strait Variations on Two Near-synonymous Loanwords xie2shang1 and tan2pan4: A Corpus-based Comparative Study
Oct 09, 2022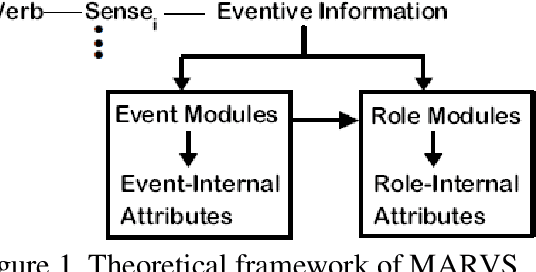
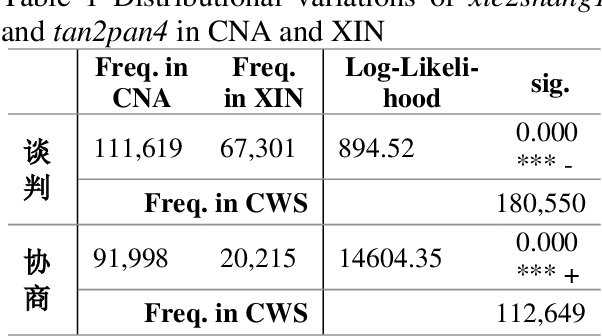
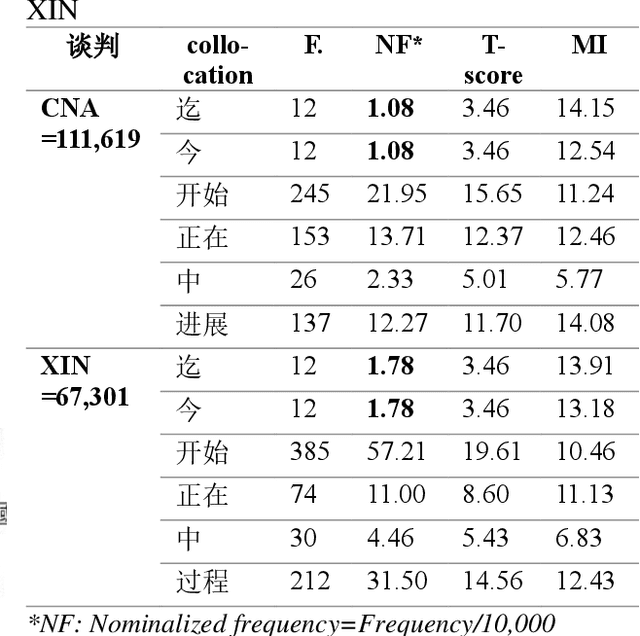

This study attempts to investigate cross-strait variations on two typical synonymous loanwords in Chinese, i.e. xie2shang1 and tan2pan4, drawn on MARVS theory. Through a comparative analysis, the study found some distributional, eventual, and contextual similarities and differences across Taiwan and Mainland Mandarin. Compared with the underused tan2pan4, xie2shang1 is significantly overused in Taiwan Mandarin and vice versa in Mainland Mandarin. Additionally, though both words can refer to an inchoative process in Mainland and Taiwan Mandarin, the starting point for xie2shang1 in Mainland Mandarin is somewhat blurring compared with the usage in Taiwan Mandarin. Further on, in Taiwan Mandarin, tan2pan4 can be used in economic and diplomatic contexts, while xie2shang1 is used almost exclusively in political contexts. In Mainland Mandarin, however, the two words can be used in a hybrid manner within political contexts; moreover, tan2pan4 is prominently used in diplomatic contexts with less reference to economic activities, while xie2sahng1 can be found in both political and legal contexts, emphasizing a role of mediation.
Automatic Analysis of Linguistic Features in Journal Articles of Different Academic Impacts with Feature Engineering Techniques
Nov 15, 2021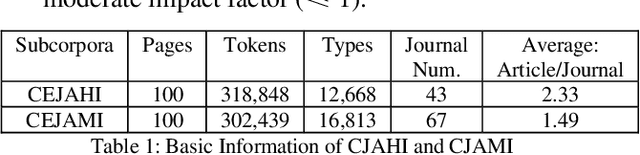

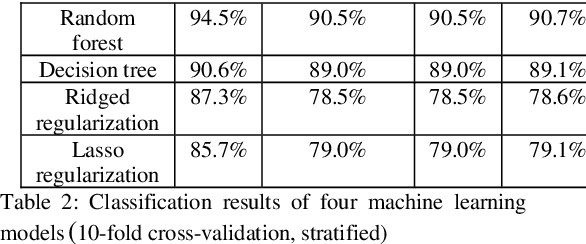
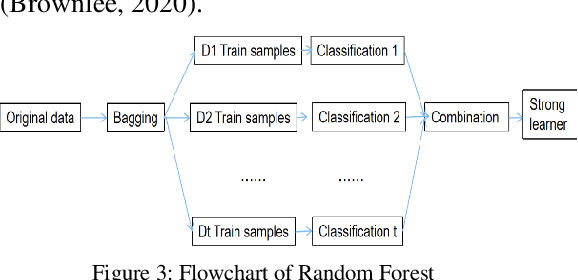
English research articles (RAs) are an essential genre in academia, so the attempts to employ NLP to assist the development of academic writing ability have received considerable attention in the last two decades. However, there has been no study employing feature engineering techniques to investigate the linguistic features of RAs of different academic impacts (i.e., the papers of high/moderate citation times published in the journals of high/moderate impact factors). This study attempts to extract micro-level linguistic features in high- and moderate-impact journal RAs, using feature engineering methods. We extracted 25 highly relevant features from the Corpus of English Journal Articles through feature selection methods. All papers in the corpus deal with COVID-19 medical empirical studies. The selected features were then validated of the classification performance in terms of consistency and accuracy through supervised machine learning methods. Results showed that 24 linguistic features such as the overlapping of content words between adjacent sentences, the use of third-person pronouns, auxiliary verbs, tense, emotional words provide consistent and accurate predictions for journal articles with different academic impacts. Lastly, the random forest model is shown to be the best model to fit the relationship between these 24 features and journal articles with high and moderate impacts. These findings can be used to inform academic writing courses and lay the foundation for developing automatic evaluation systems for L2 graduate students.
Predicting gender and age categories in English conversations using lexical, non-lexical, and turn-taking features
Feb 26, 2021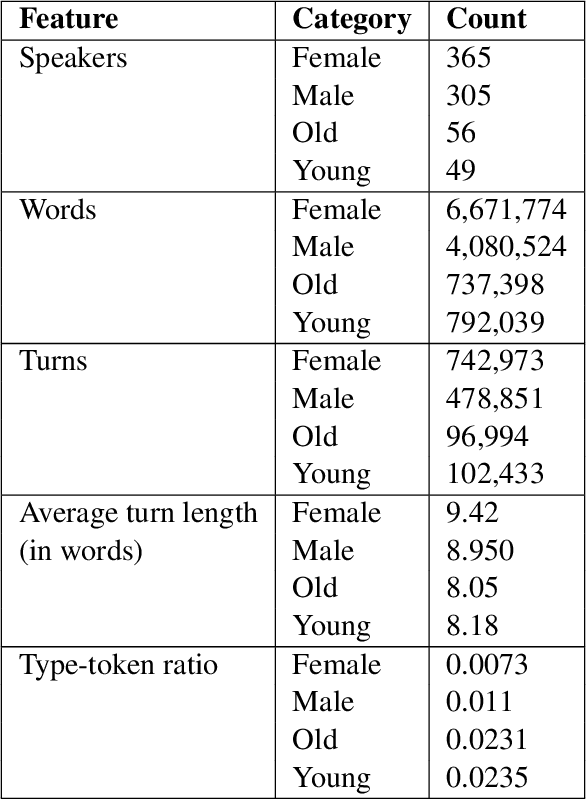

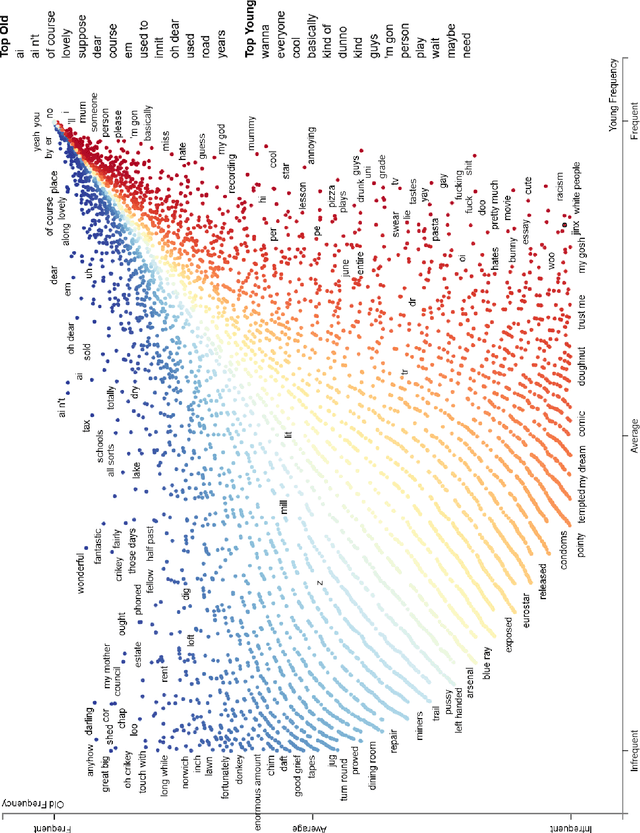
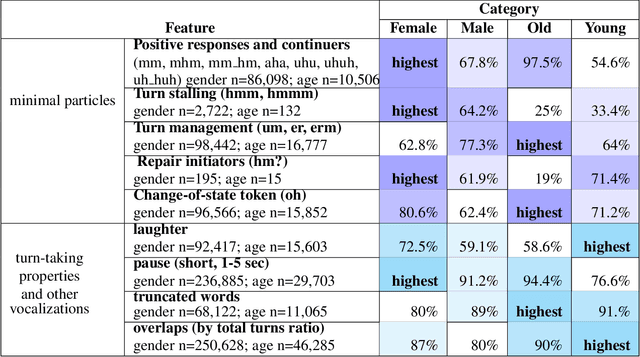
This paper examines gender and age salience and (stereo)typicality in British English talk with the aim to predict gender and age categories based on lexical, phrasal and turn-taking features. We examine the SpokenBNC, a corpus of around 11.4 million words of British English conversations and identify behavioural differences between speakers that are labelled for gender and age categories. We explore differences in language use and turn-taking dynamics and identify a range of characteristics that set the categories apart. We find that female speakers tend to produce more and slightly longer turns, while turns by male speakers feature a higher type-token ratio and a distinct range of minimal particles such as "eh", "uh" and "em". Across age groups, we observe, for instance, that swear words and laughter characterize young speakers' talk, while old speakers tend to produce more truncated words. We then use the observed characteristics to predict gender and age labels of speakers per conversation and per turn as a classification task, showing that non-lexical utterances such as minimal particles that are usually left out of dialog data can contribute to setting the categories apart.
A Structured Distributional Model of Sentence Meaning and Processing
Jun 17, 2019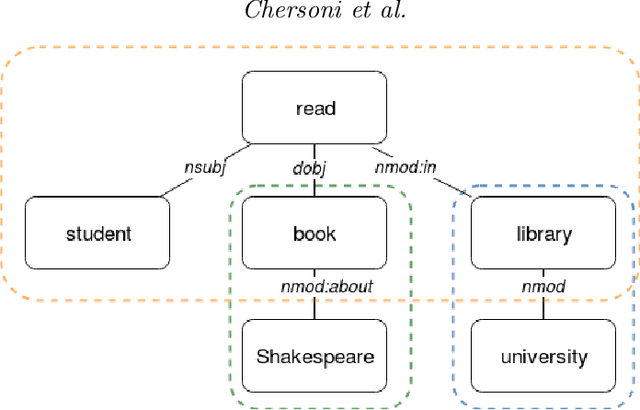

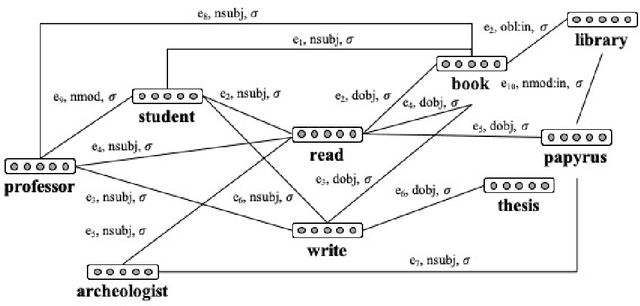
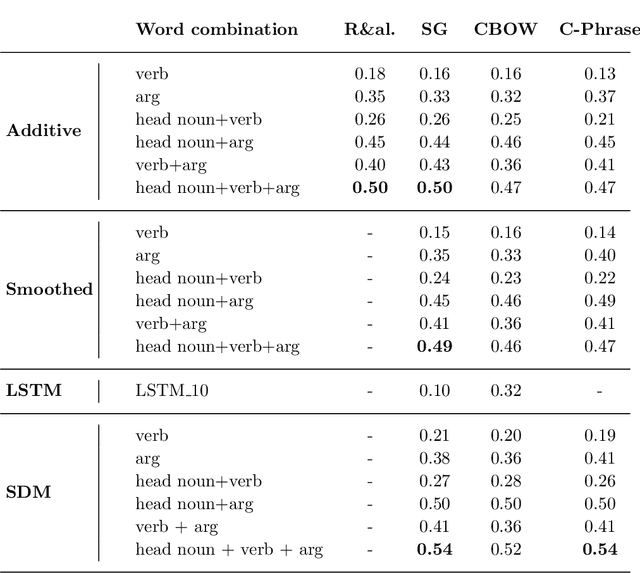
Most compositional distributional semantic models represent sentence meaning with a single vector. In this paper, we propose a Structured Distributional Model (SDM) that combines word embeddings with formal semantics and is based on the assumption that sentences represent events and situations. The semantic representation of a sentence is a formal structure derived from Discourse Representation Theory and containing distributional vectors. This structure is dynamically and incrementally built by integrating knowledge about events and their typical participants, as they are activated by lexical items. Event knowledge is modeled as a graph extracted from parsed corpora and encoding roles and relationships between participants that are represented as distributional vectors. SDM is grounded on extensive psycholinguistic research showing that generalized knowledge about events stored in semantic memory plays a key role in sentence comprehension. We evaluate SDM on two recently introduced compositionality datasets, and our results show that combining a simple compositional model with event knowledge constantly improves performances, even with different types of word embeddings.
A realistic and robust model for Chinese word segmentation
May 21, 2019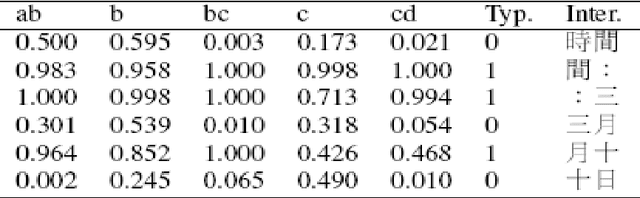
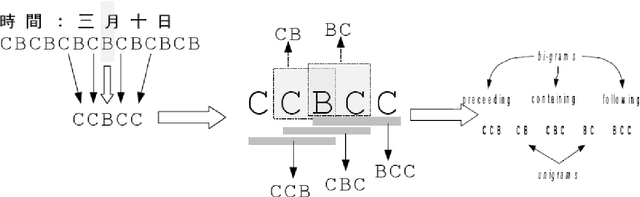
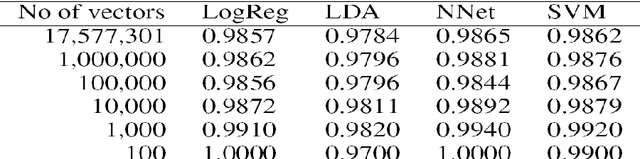
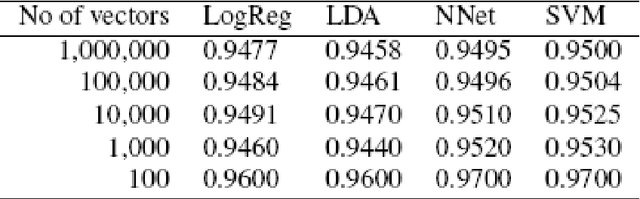
A realistic Chinese word segmentation tool must adapt to textual variations with minimal training input and yet robust enough to yield reliable segmentation result for all variants. Various lexicon-driven approaches to Chinese segmentation, e.g. [1,16], achieve high f-scores yet require massive training for any variation. Text-driven approach, e.g. [12], can be easily adapted for domain and genre changes yet has difficulty matching the high f-scores of the lexicon-driven approaches. In this paper, we refine and implement an innovative text-driven word boundary decision (WBD) segmentation model proposed in [15]. The WBD model treats word segmentation simply and efficiently as a binary decision on whether to realize the natural textual break between two adjacent characters as a word boundary. The WBD model allows simple and quick training data preparation converting characters as contextual vectors for learning the word boundary decision. Machine learning experiments with four different classifiers show that training with 1,000 vectors and 1 million vectors achieve comparable and reliable results. In addition, when applied to SigHAN Bakeoff 3 competition data, the WBD model produces OOV recall rates that are higher than all published results. Unlike all previous work, our OOV recall rate is comparable to our own F-score. Both experiments support the claim that the WBD model is a realistic model for Chinese word segmentation as it can be easily adapted for new variants with the robust result. In conclusion, we will discuss linguistic ramifications as well as future implications for the WBD approach.
Dual Memory Network Model for Biased Product Review Classification
Sep 16, 2018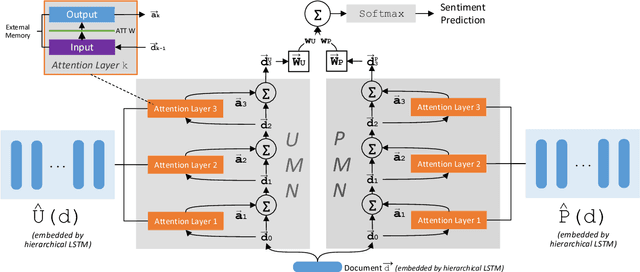
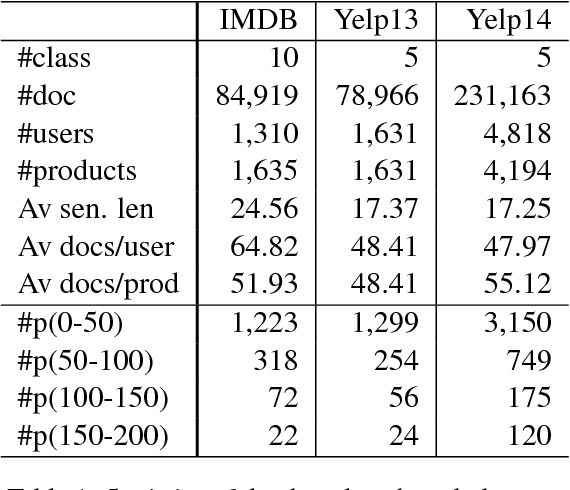
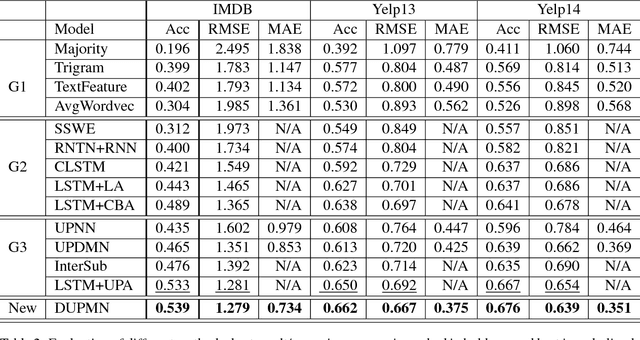

In sentiment analysis (SA) of product reviews, both user and product information are proven to be useful. Current tasks handle user profile and product information in a unified model which may not be able to learn salient features of users and products effectively. In this work, we propose a dual user and product memory network (DUPMN) model to learn user profiles and product reviews using separate memory networks. Then, the two representations are used jointly for sentiment prediction. The use of separate models aims to capture user profiles and product information more effectively. Compared to state-of-the-art unified prediction models, the evaluations on three benchmark datasets, IMDB, Yelp13, and Yelp14, show that our dual learning model gives performance gain of 0.6%, 1.2%, and 0.9%, respectively. The improvements are also deemed very significant measured by p-values.
Representing Verbs with Rich Contexts: an Evaluation on Verb Similarity
Oct 05, 2016
Several studies on sentence processing suggest that the mental lexicon keeps track of the mutual expectations between words. Current DSMs, however, represent context words as separate features, thereby loosing important information for word expectations, such as word interrelations. In this paper, we present a DSM that addresses this issue by defining verb contexts as joint syntactic dependencies. We test our representation in a verb similarity task on two datasets, showing that joint contexts achieve performances comparable to single dependencies or even better. Moreover, they are able to overcome the data sparsity problem of joint feature spaces, in spite of the limited size of our training corpus.
Testing APSyn against Vector Cosine on Similarity Estimation
Oct 05, 2016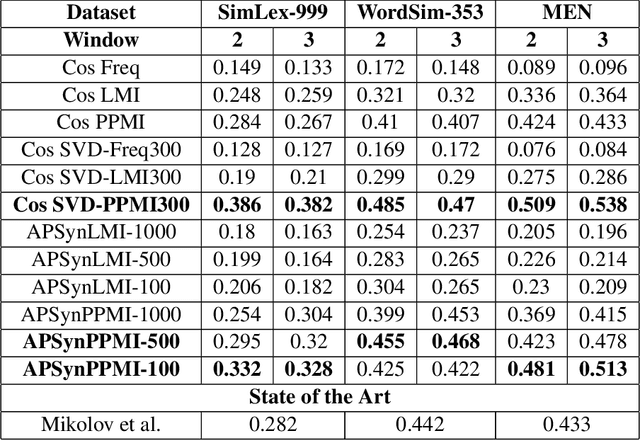
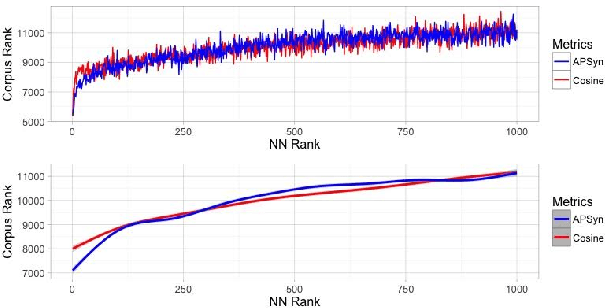
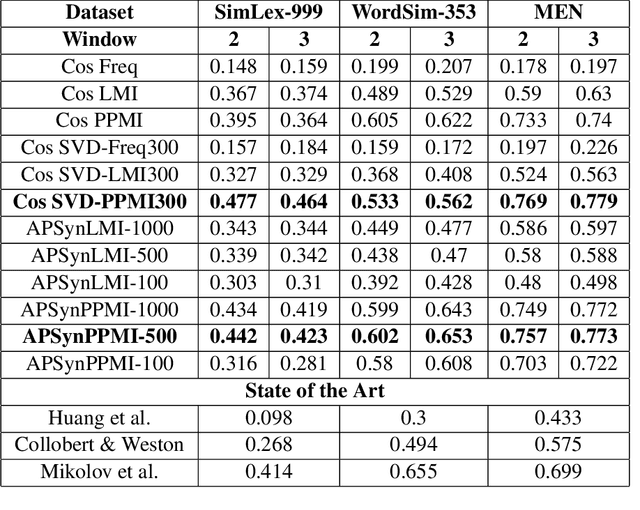
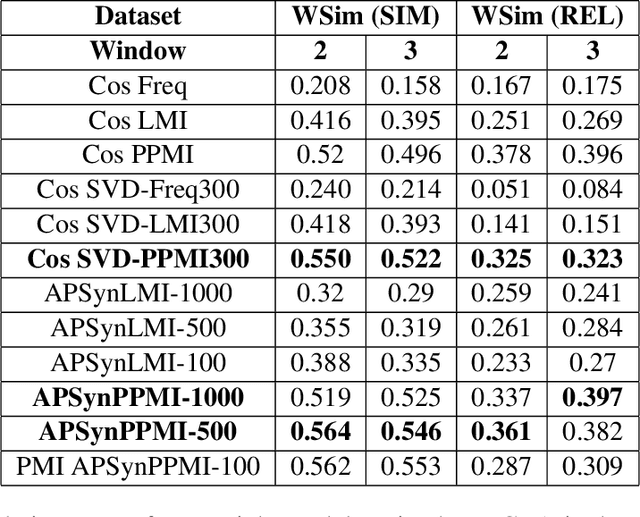
In Distributional Semantic Models (DSMs), Vector Cosine is widely used to estimate similarity between word vectors, although this measure was noticed to suffer from several shortcomings. The recent literature has proposed other methods which attempt to mitigate such biases. In this paper, we intend to investigate APSyn, a measure that computes the extent of the intersection between the most associated contexts of two target words, weighting it by context relevance. We evaluated this metric in a similarity estimation task on several popular test sets, and our results show that APSyn is in fact highly competitive, even with respect to the results reported in the literature for word embeddings. On top of it, APSyn addresses some of the weaknesses of Vector Cosine, performing well also on genuine similarity estimation.