 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA realistic and robust model for Chinese word segmentation
May 21, 2019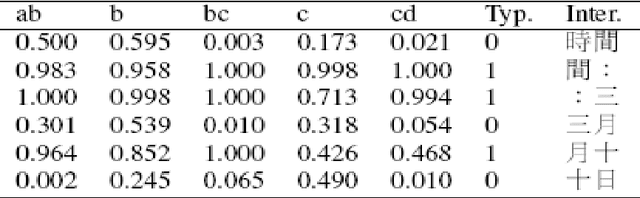
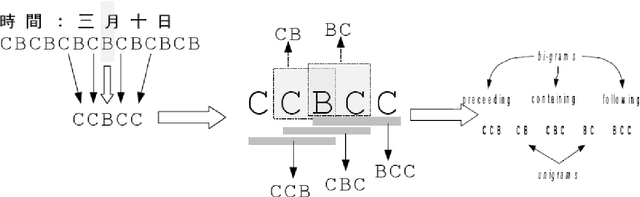
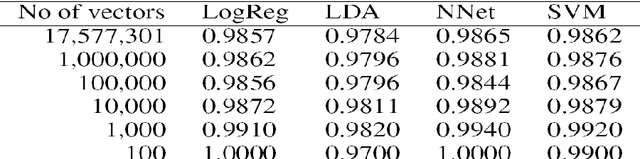
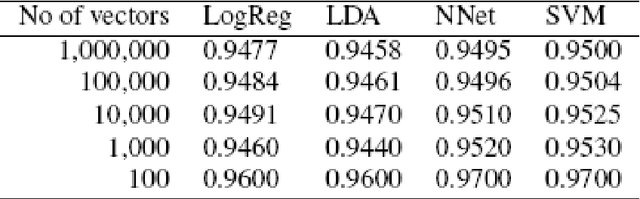
A realistic Chinese word segmentation tool must adapt to textual variations with minimal training input and yet robust enough to yield reliable segmentation result for all variants. Various lexicon-driven approaches to Chinese segmentation, e.g. [1,16], achieve high f-scores yet require massive training for any variation. Text-driven approach, e.g. [12], can be easily adapted for domain and genre changes yet has difficulty matching the high f-scores of the lexicon-driven approaches. In this paper, we refine and implement an innovative text-driven word boundary decision (WBD) segmentation model proposed in [15]. The WBD model treats word segmentation simply and efficiently as a binary decision on whether to realize the natural textual break between two adjacent characters as a word boundary. The WBD model allows simple and quick training data preparation converting characters as contextual vectors for learning the word boundary decision. Machine learning experiments with four different classifiers show that training with 1,000 vectors and 1 million vectors achieve comparable and reliable results. In addition, when applied to SigHAN Bakeoff 3 competition data, the WBD model produces OOV recall rates that are higher than all published results. Unlike all previous work, our OOV recall rate is comparable to our own F-score. Both experiments support the claim that the WBD model is a realistic model for Chinese word segmentation as it can be easily adapted for new variants with the robust result. In conclusion, we will discuss linguistic ramifications as well as future implications for the WBD approach.